 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating many futures: Online human motion prediction and synthesis for human-robot collaboration
Paper and Code
Feb 27, 2017
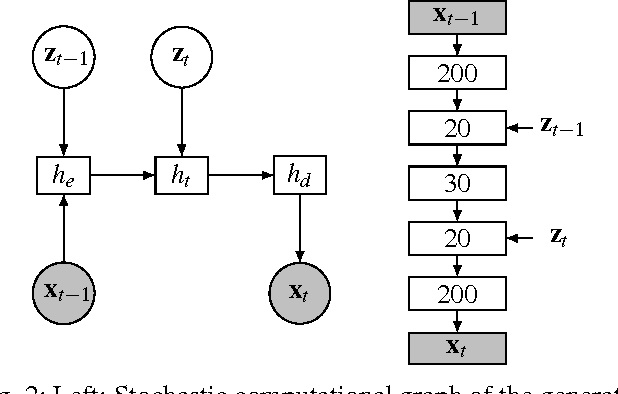

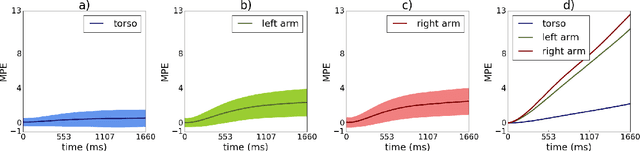
Fluent and safe interactions of humans and robots require both partners to anticipate the others' actions. A common approach to human intention inference is to model specific trajectories towards known goals with supervised classifiers. However, these approaches do not take possible future movements into account nor do they make use of kinematic cues, such as legible and predictable motion. The bottleneck of these methods is the lack of an accurate model of general human motion. In this work, we present a conditional variational autoencoder that is trained to predict a window of future human motion given a window of past frames. Using skeletal data obtained from RGB depth images, we show how this unsupervised approach can be used for online motion prediction for up to 1660 ms. Additionally, we demonstrate online target prediction within the first 300-500 ms after motion onset without the use of target specific training data. The advantage of our probabilistic approach is the possibility to draw samples of possible future motions. Finally, we investigate how movements and kinematic cues are represented on the learned low dimensional manifold.