 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, anticipate and generate: Semi-supervised recurrent latent variable models for human activity modeling
Paper and Code
Sep 19, 2018

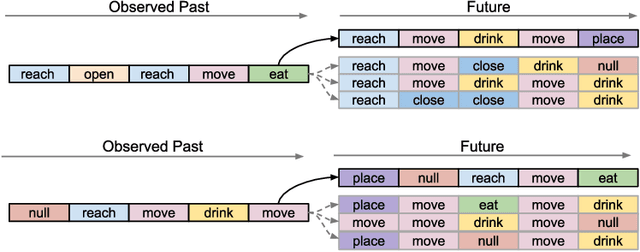

Successful Human-Robot collaboration requires a predictive model of human behavior. The robot needs to be able to recognize current goals and actions and to predict future activities in a given context. However, the spatio-temporal sequence of human actions is difficult to model since latent factors such as intention, task, knowledge, intuition and preference determine the action choices of each individual. In this work we introduce semi-supervised variational recurrent neural networks which are able to a) model temporal distributions over latent factors and the observable feature space, b) incorporate discrete labels such as activity type when available, and c) generate possible future action sequences on both feature and label level. We evaluate our model on the Cornell Activity Dataset CAD-120 dataset. Our model outperforms state-of-the-art approaches in both activity and affordance detection and anticipation. Additionally, we show how samples of possible future action sequences are in line with past observations.