 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Group Composition: A Window into the Mechanics of Deep Learning
Feb 03, 2026How do neural networks trained over sequences acquire the ability to perform structured operations, such as arithmetic, geometric, and algorithmic computation? To gain insight into this question, we introduce the sequential group composition task. In this task, networks receive a sequence of elements from a finite group encoded in a real vector space and must predict their cumulative product. The task can be order-sensitive and requires a nonlinear architecture to be learned. Our analysis isolates the roles of the group structure, encoding statistics, and sequence length in shaping learning. We prove that two-layer networks learn this task one irreducible representation of the group at a time in an order determined by the Fourier statistics of the encoding. These networks can perfectly learn the task, but doing so requires a hidden width exponential in the sequence length $k$. In contrast, we show how deeper models exploit the associativity of the task to dramatically improve this scaling: recurrent neural networks compose elements sequentially in $k$ steps, while multilayer networks compose adjacent pairs in parallel in $\log k$ layers. Overall, the sequential group composition task offers a tractable window into the mechanics of deep learning.
Identifiable Equivariant Networks are Layerwise Equivariant
Jan 29, 2026We investigate the relation between end-to-end equivariance and layerwise equivariance in deep neural networks. We prove the following: For a network whose end-to-end function is equivariant with respect to group actions on the input and output spaces, there is a parameter choice yielding the same end-to-end function such that its layers are equivariant with respect to some group actions on the latent spaces. Our result assumes that the parameters of the model are identifiable in an appropriate sense. This identifiability property has been established in the literature for a large class of networks, to which our results apply immediately, while it is conjectural for others. The theory we develop is grounded in an abstract formalism, and is therefore architecture-agnostic. Overall, our results provide a mathematical explanation for the emergence of equivariant structures in the weights of neural networks during training -- a phenomenon that is consistently observed in practice.
Critical Points of Degenerate Metrics on Algebraic Varieties: A Tale of Overparametrization
Dec 24, 2025


We study the critical points over an algebraic variety of an optimization problem defined by a quadratic objective that is degenerate. This scenario arises in machine learning when the dataset size is small with respect to the model, and is typically referred to as overparametrization. Our main result relates the degenerate optimization problem to a nondegenerate one via a projection. In the highly-degenerate regime, we find that a central role is played by the ramification locus of the projection. Additionally, we provide tools for counting the number of critical points over projective varieties, and discuss specific cases arising from deep learning. Our work bridges tools from algebraic geometry with ideas from machine learning, and it extends the line of literature around the Euclidean distance degree to the degenerate setting.
Sprecher Networks: A Parameter-Efficient Kolmogorov-Arnold Architecture
Dec 22, 2025We present Sprecher Networks (SNs), a family of trainable neural architectures inspired by the classical Kolmogorov-Arnold-Sprecher (KAS) construction for approximating multivariate continuous functions. Distinct from Multi-Layer Perceptrons (MLPs) with fixed node activations and Kolmogorov-Arnold Networks (KANs) featuring learnable edge activations, SNs utilize shared, learnable splines (monotonic and general) within structured blocks incorporating explicit shift parameters and mixing weights. Our approach directly realizes Sprecher's specific 1965 sum of shifted splines formula in its single-layer variant and extends it to deeper, multi-layer compositions. We further enhance the architecture with optional lateral mixing connections that enable intra-block communication between output dimensions, providing a parameter-efficient alternative to full attention mechanisms. Beyond parameter efficiency with $O(LN + LG)$ scaling (where $G$ is the knot count of the shared splines) versus MLPs' $O(LN^2)$, SNs admit a sequential evaluation strategy that reduces peak forward-intermediate memory from $O(N^2)$ to $O(N)$ (treating batch size as constant), making much wider architectures feasible under memory constraints. We demonstrate empirically that composing these blocks into deep networks leads to highly parameter and memory-efficient models, discuss theoretical motivations, and compare SNs with related architectures (MLPs, KANs, and networks with learnable node activations).
Alternating Gradient Flows: A Theory of Feature Learning in Two-layer Neural Networks
Jun 06, 2025What features neural networks learn, and how, remains an open question. In this paper, we introduce Alternating Gradient Flows (AGF), an algorithmic framework that describes the dynamics of feature learning in two-layer networks trained from small initialization. Prior works have shown that gradient flow in this regime exhibits a staircase-like loss curve, alternating between plateaus where neurons slowly align to useful directions and sharp drops where neurons rapidly grow in norm. AGF approximates this behavior as an alternating two-step process: maximizing a utility function over dormant neurons and minimizing a cost function over active ones. AGF begins with all neurons dormant. At each round, a dormant neuron activates, triggering the acquisition of a feature and a drop in the loss. AGF quantifies the order, timing, and magnitude of these drops, matching experiments across architectures. We show that AGF unifies and extends existing saddle-to-saddle analyses in fully connected linear networks and attention-only linear transformers, where the learned features are singular modes and principal components, respectively. In diagonal linear networks, we prove AGF converges to gradient flow in the limit of vanishing initialization. Applying AGF to quadratic networks trained to perform modular addition, we give the first complete characterization of the training dynamics, revealing that networks learn Fourier features in decreasing order of coefficient magnitude. Altogether, AGF offers a promising step towards understanding feature learning in neural networks.
Learning on a Razor's Edge: the Singularity Bias of Polynomial Neural Networks
May 17, 2025Deep neural networks often infer sparse representations, converging to a subnetwork during the learning process. In this work, we theoretically analyze subnetworks and their bias through the lens of algebraic geometry. We consider fully-connected networks with polynomial activation functions, and focus on the geometry of the function space they parametrize, often referred to as neuromanifold. First, we compute the dimension of the subspace of the neuromanifold parametrized by subnetworks. Second, we show that this subspace is singular. Third, we argue that such singularities often correspond to critical points of the training dynamics. Lastly, we discuss convolutional networks, for which subnetworks and singularities are similarly related, but the bias does not arise.
An Invitation to Neuroalgebraic Geometry
Jan 31, 2025



In this expository work, we promote the study of function spaces parameterized by machine learning models through the lens of algebraic geometry. To this end, we focus on algebraic models, such as neural networks with polynomial activations, whose associated function spaces are semi-algebraic varieties. We outline a dictionary between algebro-geometric invariants of these varieties, such as dimension, degree, and singularities, and fundamental aspects of machine learning, such as sample complexity, expressivity, training dynamics, and implicit bias. Along the way, we review the literature and discuss ideas beyond the algebraic domain. This work lays the foundations of a research direction bridging algebraic geometry and deep learning, that we refer to as neuroalgebraic geometry.
On the Geometry and Optimization of Polynomial Convolutional Networks
Oct 01, 2024



We study convolutional neural networks with monomial activation functions. Specifically, we prove that their parameterization map is regular and is an isomorphism almost everywhere, up to rescaling the filters. By leveraging on tools from algebraic geometry, we explore the geometric properties of the image in function space of this map -- typically referred to as neuromanifold. In particular, we compute the dimension and the degree of the neuromanifold, which measure the expressivity of the model, and describe its singularities. Moreover, for a generic large dataset, we derive an explicit formula that quantifies the number of critical points arising in the optimization of a regression loss.
Relative Representations: Topological and Geometric Perspectives
Sep 17, 2024


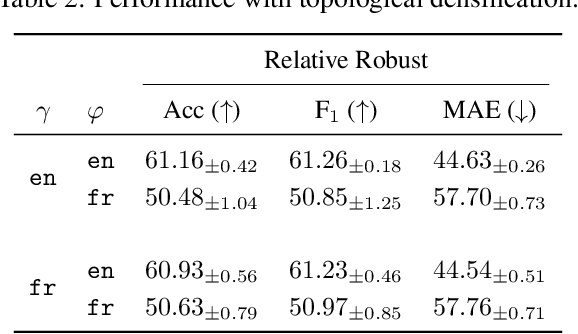
Relative representations are an established approach to zero-shot model stitching, consisting of a non-trainable transformation of the latent space of a deep neural network. Based on insights of topological and geometric nature, we propose two improvements to relative representations. First, we introduce a normalization procedure in the relative transformation, resulting in invariance to non-isotropic rescalings and permutations. The latter coincides with the symmetries in parameter space induced by common activation functions. Second, we propose to deploy topological densification when fine-tuning relative representations, a topological regularization loss encouraging clustering within classes. We provide an empirical investigation on a natural language task, where both the proposed variations yield improved performance on zero-shot model stitching.
Geometry of Lightning Self-Attention: Identifiability and Dimension
Aug 30, 2024



We consider function spaces defined by self-attention networks without normalization, and theoretically analyze their geometry. Since these networks are polynomial, we rely on tools from algebraic geometry. In particular, we study the identifiability of deep attention by providing a description of the generic fibers of the parametrization for an arbitrary number of layers and, as a consequence, compute the dimension of the function space. Additionally, for a single-layer model, we characterize the singular and boundary points. Finally, we formulate a conjectural extension of our results to normalized self-attention networks, prove it for a single layer, and numerically verify it in the deep case.