 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Apr 20, 2026Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers
Feb 06, 2026Can general-purpose AI architectures go beyond prediction to discover the physical laws governing the universe? True intelligence relies on "world models" -- causal abstractions that allow an agent to not only predict future states but understand the underlying governing dynamics. While previous "AI Physicist" approaches have successfully recovered such laws, they typically rely on strong, domain-specific priors that effectively "bake in" the physics. Conversely, Vafa et al. recently showed that generic Transformers fail to acquire these world models, achieving high predictive accuracy without capturing the underlying physical laws. We bridge this gap by systematically introducing three minimal inductive biases. We show that ensuring spatial smoothness (by formulating prediction as continuous regression) and stability (by training with noisy contexts to mitigate error accumulation) enables generic Transformers to surpass prior failures and learn a coherent Keplerian world model, successfully fitting ellipses to planetary trajectories. However, true physical insight requires a third bias: temporal locality. By restricting the attention window to the immediate past -- imposing the simple assumption that future states depend only on the local state rather than a complex history -- we force the model to abandon curve-fitting and discover Newtonian force representations. Our results demonstrate that simple architectural choices determine whether an AI becomes a curve-fitter or a physicist, marking a critical step toward automated scientific discovery.
NeuroAI for AI Safety
Nov 27, 2024



As AI systems become increasingly powerful, the need for safe AI has become more pressing. Humans are an attractive model for AI safety: as the only known agents capable of general intelligence, they perform robustly even under conditions that deviate significantly from prior experiences, explore the world safely, understand pragmatics, and can cooperate to meet their intrinsic goals. Intelligence, when coupled with cooperation and safety mechanisms, can drive sustained progress and well-being. These properties are a function of the architecture of the brain and the learning algorithms it implements. Neuroscience may thus hold important keys to technical AI safety that are currently underexplored and underutilized. In this roadmap, we highlight and critically evaluate several paths toward AI safety inspired by neuroscience: emulating the brain's representations, information processing, and architecture; building robust sensory and motor systems from imitating brain data and bodies; fine-tuning AI systems on brain data; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We make several concrete recommendations for how neuroscience can positively impact AI safety.
Beyond Euclid: An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures
Jul 12, 2024



The enduring legacy of Euclidean geometry underpins classical machine learning, which, for decades, has been primarily developed for data lying in Euclidean space. Yet, modern machine learning increasingly encounters richly structured data that is inherently nonEuclidean. This data can exhibit intricate geometric, topological and algebraic structure: from the geometry of the curvature of space-time, to topologically complex interactions between neurons in the brain, to the algebraic transformations describing symmetries of physical systems. Extracting knowledge from such non-Euclidean data necessitates a broader mathematical perspective. Echoing the 19th-century revolutions that gave rise to non-Euclidean geometry, an emerging line of research is redefining modern machine learning with non-Euclidean structures. Its goal: generalizing classical methods to unconventional data types with geometry, topology, and algebra. In this review, we provide an accessible gateway to this fast-growing field and propose a graphical taxonomy that integrates recent advances into an intuitive unified framework. We subsequently extract insights into current challenges and highlight exciting opportunities for future development in this field.
The Selective G-Bispectrum and its Inversion: Applications to G-Invariant Networks
Jul 10, 2024
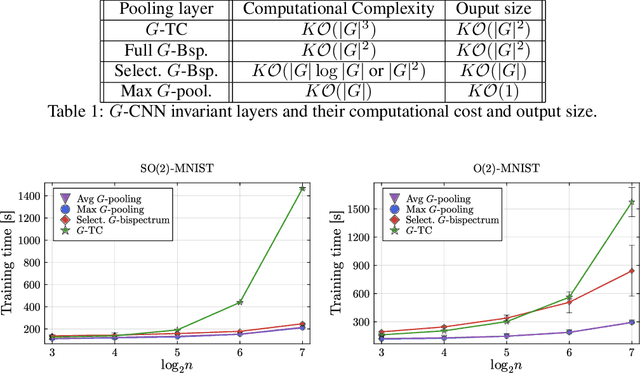

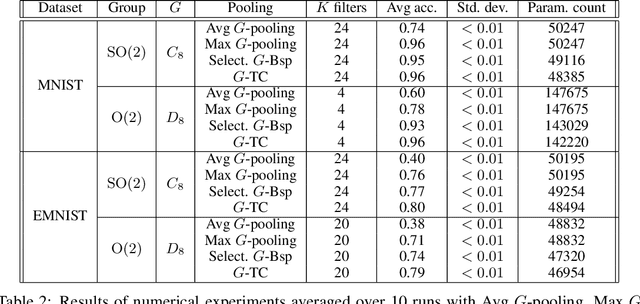
An important problem in signal processing and deep learning is to achieve \textit{invariance} to nuisance factors not relevant for the task. Since many of these factors are describable as the action of a group $G$ (e.g. rotations, translations, scalings), we want methods to be $G$-invariant. The $G$-Bispectrum extracts every characteristic of a given signal up to group action: for example, the shape of an object in an image, but not its orientation. Consequently, the $G$-Bispectrum has been incorporated into deep neural network architectures as a computational primitive for $G$-invariance\textemdash akin to a pooling mechanism, but with greater selectivity and robustness. However, the computational cost of the $G$-Bispectrum ($\mathcal{O}(|G|^2)$, with $|G|$ the size of the group) has limited its widespread adoption. Here, we show that the $G$-Bispectrum computation contains redundancies that can be reduced into a \textit{selective $G$-Bispectrum} with $\mathcal{O}(|G|)$ complexity. We prove desirable mathematical properties of the selective $G$-Bispectrum and demonstrate how its integration in neural networks enhances accuracy and robustness compared to traditional approaches, while enjoying considerable speeds-up compared to the full $G$-Bispectrum.
Harmonics of Learning: Universal Fourier Features Emerge in Invariant Networks
Dec 23, 2023In this work, we formally prove that, under certain conditions, if a neural network is invariant to a finite group then its weights recover the Fourier transform on that group. This provides a mathematical explanation for the emergence of Fourier features -- a ubiquitous phenomenon in both biological and artificial learning systems. The results hold even for non-commutative groups, in which case the Fourier transform encodes all the irreducible unitary group representations. Our findings have consequences for the problem of symmetry discovery. Specifically, we demonstrate that the algebraic structure of an unknown group can be recovered from the weights of a network that is at least approximately invariant within certain bounds. Overall, this work contributes to a foundation for an algebraic learning theory of invariant neural network representations.
Exploring the hierarchical structure of human plans via program generation
Nov 30, 2023Human behavior is inherently hierarchical, resulting from the decomposition of a task into subtasks or an abstract action into concrete actions. However, behavior is typically measured as a sequence of actions, which makes it difficult to infer its hierarchical structure. In this paper, we explore how people form hierarchically-structured plans, using an experimental paradigm that makes hierarchical representations observable: participants create programs that produce sequences of actions in a language with explicit hierarchical structure. This task lets us test two well-established principles of human behavior: utility maximization (i.e. using fewer actions) and minimum description length (MDL; i.e. having a shorter program). We find that humans are sensitive to both metrics, but that both accounts fail to predict a qualitative feature of human-created programs, namely that people prefer programs with reuse over and above the predictions of MDL. We formalize this preference for reuse by extending the MDL account into a generative model over programs, modeling hierarchy choice as the induction of a grammar over actions. Our account can explain the preference for reuse and provides the best prediction of human behavior, going beyond simple accounts of compressibility to highlight a principle that guides hierarchical planning.
A General Framework for Robust G-Invariance in G-Equivariant Networks
Oct 28, 2023We introduce a general method for achieving robust group-invariance in group-equivariant convolutional neural networks ($G$-CNNs), which we call the $G$-triple-correlation ($G$-TC) layer. The approach leverages the theory of the triple-correlation on groups, which is the unique, lowest-degree polynomial invariant map that is also complete. Many commonly used invariant maps - such as the max - are incomplete: they remove both group and signal structure. A complete invariant, by contrast, removes only the variation due to the actions of the group, while preserving all information about the structure of the signal. The completeness of the triple correlation endows the $G$-TC layer with strong robustness, which can be observed in its resistance to invariance-based adversarial attacks. In addition, we observe that it yields measurable improvements in classification accuracy over standard Max $G$-Pooling in $G$-CNN architectures. We provide a general and efficient implementation of the method for any discretized group, which requires only a table defining the group's product structure. We demonstrate the benefits of this method for $G$-CNNs defined on both commutative and non-commutative groups - $SO(2)$, $O(2)$, $SO(3)$, and $O(3)$ (discretized as the cyclic $C8$, dihedral $D16$, chiral octahedral $O$ and full octahedral $O_h$ groups) - acting on $\mathbb{R}^2$ and $\mathbb{R}^3$ on both $G$-MNIST and $G$-ModelNet10 datasets.
Identifying Interpretable Visual Features in Artificial and Biological Neural Systems
Oct 18, 2023



Single neurons in neural networks are often interpretable in that they represent individual, intuitively meaningful features. However, many neurons exhibit $\textit{mixed selectivity}$, i.e., they represent multiple unrelated features. A recent hypothesis proposes that features in deep networks may be represented in $\textit{superposition}$, i.e., on non-orthogonal axes by multiple neurons, since the number of possible interpretable features in natural data is generally larger than the number of neurons in a given network. Accordingly, we should be able to find meaningful directions in activation space that are not aligned with individual neurons. Here, we propose (1) an automated method for quantifying visual interpretability that is validated against a large database of human psychophysics judgments of neuron interpretability, and (2) an approach for finding meaningful directions in network activation space. We leverage these methods to discover directions in convolutional neural networks that are more intuitively meaningful than individual neurons, as we confirm and investigate in a series of analyses. Moreover, we apply the same method to three recent datasets of visual neural responses in the brain and find that our conclusions largely transfer to real neural data, suggesting that superposition might be deployed by the brain. This also provides a link with disentanglement and raises fundamental questions about robust, efficient and factorized representations in both artificial and biological neural systems.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023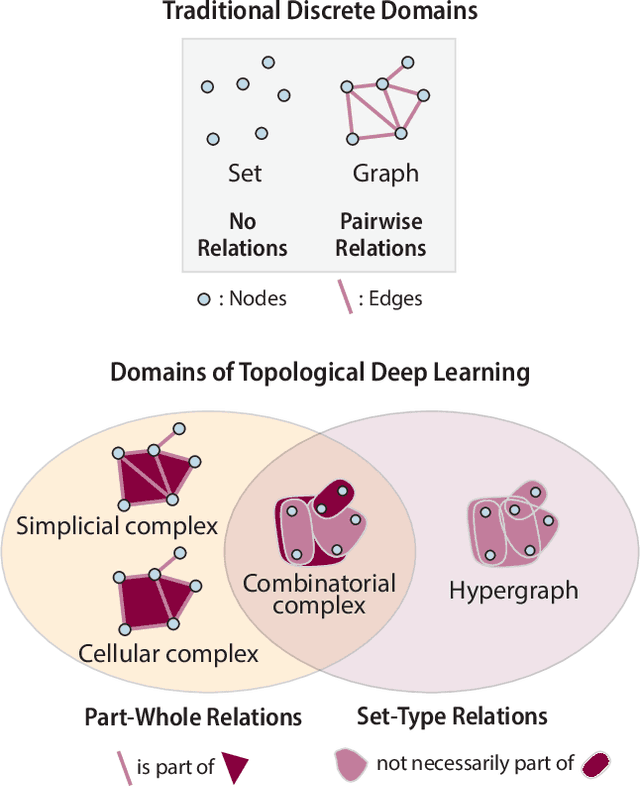
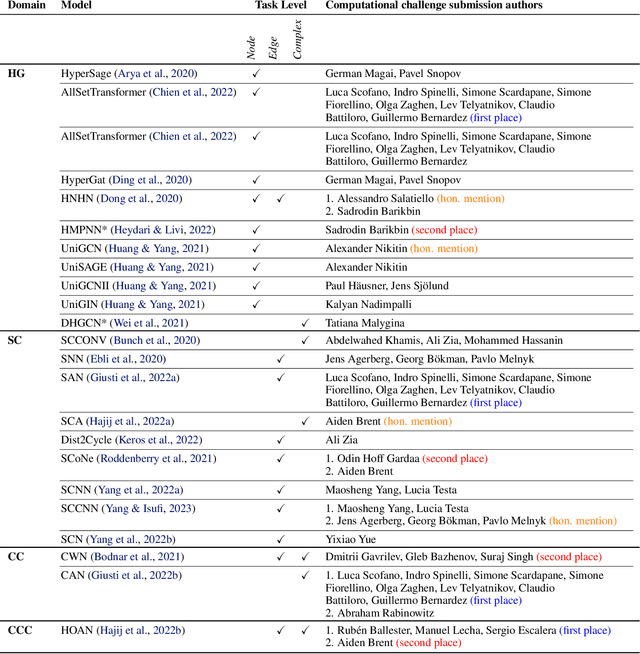
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.