 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURLOST: Unsupervised Representation Learning without Stationarity or Topology
Oct 06, 2023Unsupervised representation learning has seen tremendous progress but is constrained by its reliance on data modality-specific stationarity and topology, a limitation not found in biological intelligence systems. For instance, human vision processes visual signals derived from irregular and non-stationary sampling lattices yet accurately perceives the geometry of the world. We introduce a novel framework that learns from high-dimensional data lacking stationarity and topology. Our model combines a learnable self-organizing layer, density adjusted spectral clustering, and masked autoencoders. We evaluate its effectiveness on simulated biological vision data, neural recordings from the primary visual cortex, and gene expression datasets. Compared to state-of-the-art unsupervised learning methods like SimCLR and MAE, our model excels at learning meaningful representations across diverse modalities without depending on stationarity or topology. It also outperforms other methods not dependent on these factors, setting a new benchmark in the field. This work represents a step toward unsupervised learning methods that can generalize across diverse high-dimensional data modalities.
Learning Internal Representations of 3D Transformations from 2D Projected Inputs
Mar 31, 2023When interacting in a three dimensional world, humans must estimate 3D structure from visual inputs projected down to two dimensional retinal images. It has been shown that humans use the persistence of object shape over motion-induced transformations as a cue to resolve depth ambiguity when solving this underconstrained problem. With the aim of understanding how biological vision systems may internally represent 3D transformations, we propose a computational model, based on a generative manifold model, which can be used to infer 3D structure from the motion of 2D points. Our model can also learn representations of the transformations with minimal supervision, providing a proof of concept for how humans may develop internal representations on a developmental or evolutionary time scale. Focused on rotational motion, we show how our model infers depth from moving 2D projected points, learns 3D rotational transformations from 2D training stimuli, and compares to human performance on psychophysical structure-from-motion experiments.
PIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
Minimalistic Unsupervised Learning with the Sparse Manifold Transform
Sep 30, 2022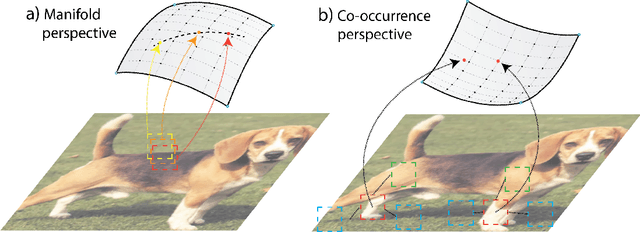

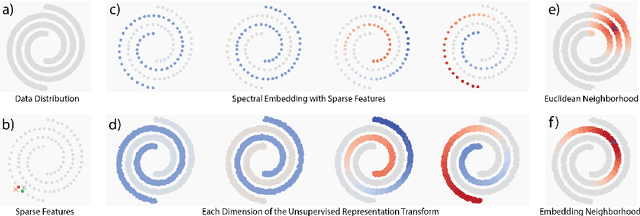

We describe a minimalistic and interpretable method for unsupervised learning, without resorting to data augmentation, hyperparameter tuning, or other engineering designs, that achieves performance close to the SOTA SSL methods. Our approach leverages the sparse manifold transform, which unifies sparse coding, manifold learning, and slow feature analysis. With a one-layer deterministic sparse manifold transform, one can achieve 99.3% KNN top-1 accuracy on MNIST, 81.1% KNN top-1 accuracy on CIFAR-10 and 53.2% on CIFAR-100. With a simple gray-scale augmentation, the model gets 83.2% KNN top-1 accuracy on CIFAR-10 and 57% on CIFAR-100. These results significantly close the gap between simplistic ``white-box'' methods and the SOTA methods. Additionally, we provide visualization to explain how an unsupervised representation transform is formed. The proposed method is closely connected to latent-embedding self-supervised methods and can be treated as the simplest form of VICReg. Though there remains a small performance gap between our simple constructive model and SOTA methods, the evidence points to this as a promising direction for achieving a principled and white-box approach to unsupervised learning.
Bispectral Neural Networks
Sep 09, 2022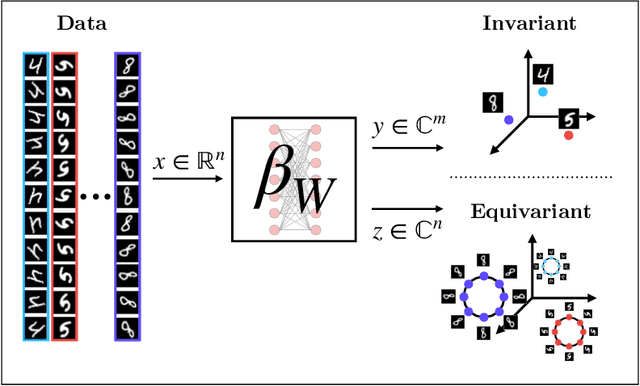
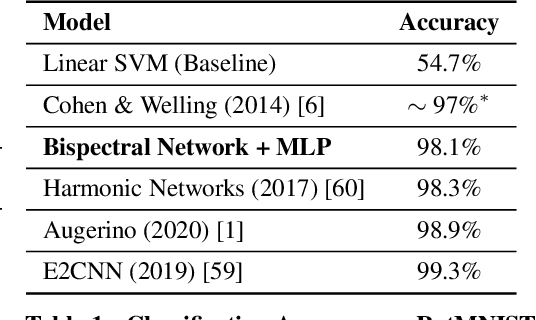
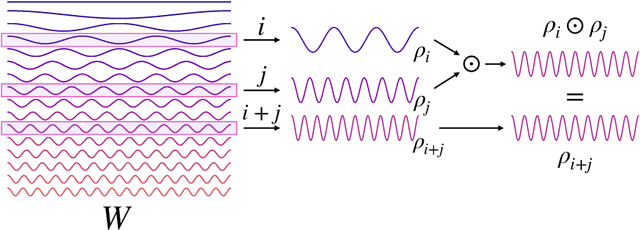
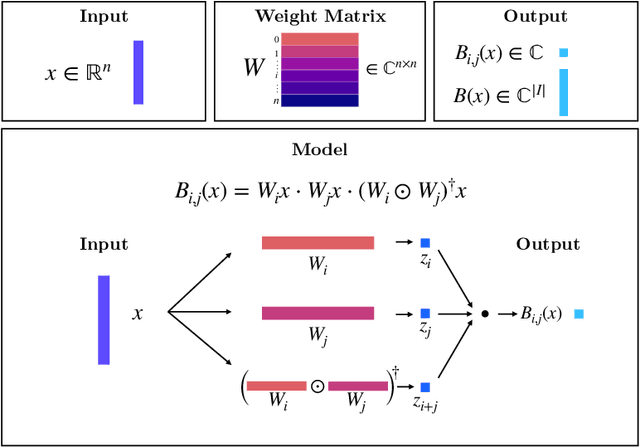
We present a novel machine learning architecture, Bispectral Neural Networks (BNNs), for learning representations of data that are invariant to the actions of groups on the space over which a signal is defined. The model incorporates the ansatz of the bispectrum, an analytically defined group invariant that is complete--that is, it preserves all signal structure while removing only the variation due to group actions. Here, we demonstrate that BNNs are able to discover arbitrary commutative group structure in data, with the trained models learning the irreducible representations of the groups, which allows for the recovery of the group Cayley tables. Remarkably, trained networks learn to approximate bispectra on these groups, and thus possess the robustness, completeness, and generality of the analytical object.
An Interactive Annotation Tool for Perceptual Video Compression
May 08, 2022


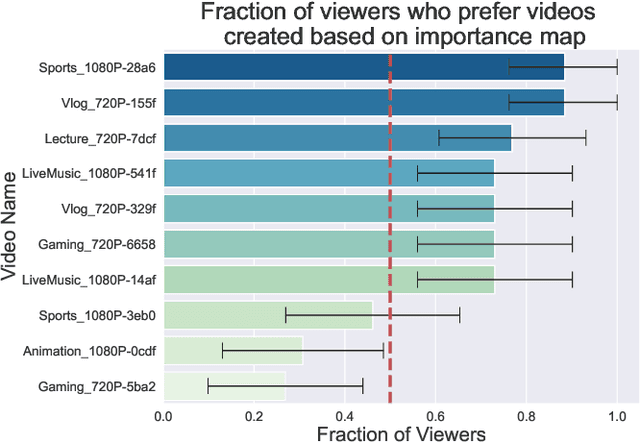
Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
Disentangling images with Lie group transformations and sparse coding
Dec 11, 2020



Discrete spatial patterns and their continuous transformations are two important regularities contained in natural signals. Lie groups and representation theory are mathematical tools that have been used in previous works to model continuous image transformations. On the other hand, sparse coding is an important tool for learning dictionaries of patterns in natural signals. In this paper, we combine these ideas in a Bayesian generative model that learns to disentangle spatial patterns and their continuous transformations in a completely unsupervised manner. Images are modeled as a sparse superposition of shape components followed by a transformation that is parameterized by n continuous variables. The shape components and transformations are not predefined, but are instead adapted to learn the symmetries in the data, with the constraint that the transformations form a representation of an n-dimensional torus. Training the model on a dataset consisting of controlled geometric transformations of specific MNIST digits shows that it can recover these transformations along with the digits. Training on the full MNIST dataset shows that it can learn both the basic digit shapes and the natural transformations such as shearing and stretching that are contained in this data.
RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior
Oct 07, 2020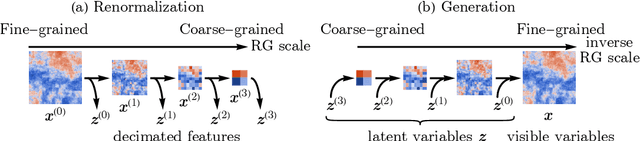
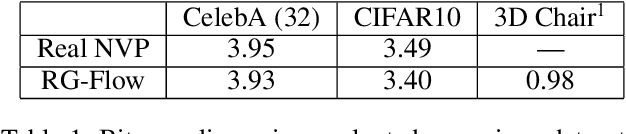
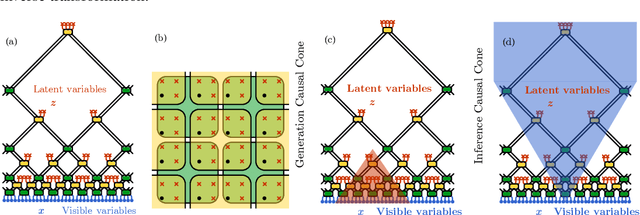

Flow-based generative models have become an important class of unsupervised learning approaches. In this work, we incorporate the key idea of renormalization group (RG) and sparse prior distribution to design a hierarchical flow-based generative model, called RG-Flow, which can separate different scale information of images with disentangle representations at each scale. We demonstrate our method mainly on the CelebA dataset and show that the disentangled representation at different scales enables semantic manipulation and style mixing of the images. To visualize the latent representation, we introduce the receptive fields for flow-based models and find receptive fields learned by RG-Flow are similar to convolutional neural networks. In addition, we replace the widely adopted Gaussian prior distribution by sparse prior distributions to further enhance the disentanglement of representations. From a theoretical perspective, the proposed method has $O(\log L)$ complexity for image inpainting compared to previous flow-based models with $O(L^2)$ complexity.
Fully Test-time Adaptation by Entropy Minimization
Jun 18, 2020
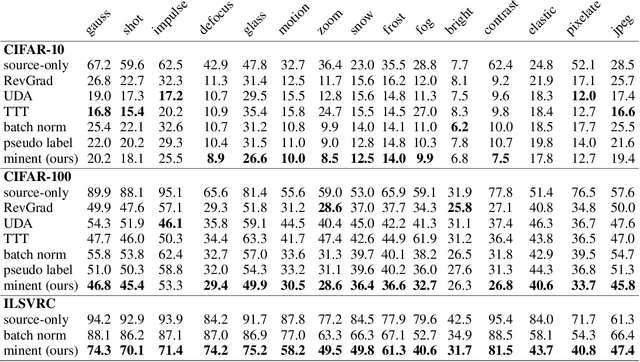


Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.