 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterization of point-source transient events with a rolling-shutter compressed sensing system
Aug 29, 2024Point-source transient events (PSTEs) - optical events that are both extremely fast and extremely small - pose several challenges to an imaging system. Due to their speed, accurately characterizing such events often requires detectors with very high frame rates. Due to their size, accurately detecting such events requires maintaining coverage over an extended field-of-view, often through the use of imaging focal plane arrays (FPA) with a global shutter readout. Traditional imaging systems that meet these requirements are costly in terms of price, size, weight, power consumption, and data bandwidth, and there is a need for cheaper solutions with adequate temporal and spatial coverage. To address these issues, we develop a novel compressed sensing algorithm adapted to the rolling shutter readout of an imaging system. This approach enables reconstruction of a PSTE signature at the sampling rate of the rolling shutter, offering a 1-2 order of magnitude temporal speedup and a proportional reduction in data bandwidth. We present empirical results demonstrating accurate recovery of PSTEs using measurements that are spatially undersampled by a factor of 25, and our simulations show that, relative to other compressed sensing algorithms, our algorithm is both faster and yields higher quality reconstructions. We also present theoretical results characterizing our algorithm and corroborating simulations. The potential impact of our work includes the development of much faster, cheaper sensor solutions for PSTE detection and characterization.
Random Projections of Sparse Adjacency Matrices
Sep 04, 2023We analyze a random projection method for adjacency matrices, studying its utility in representing sparse graphs. We show that these random projections retain the functionality of their underlying adjacency matrices while having extra properties that make them attractive as dynamic graph representations. In particular, they can represent graphs of different sizes and vertex sets in the same space, allowing for the aggregation and manipulation of graphs in a unified manner. We also provide results on how the size of the projections need to scale in order to preserve accurate graph operations, showing that the size of the projections can scale linearly with the number of vertices while accurately retaining first-order graph information. We conclude by characterizing our random projection as a distance-preserving map of adjacency matrices analogous to the usual Johnson-Lindenstrauss map.
Tensor Products and Hyperdimensional Computing
May 20, 2023Following up on a previous analysis of graph embeddings, we generalize and expand some results to the general setting of vector symbolic architectures (VSA) and hyperdimensional computing (HDC). Importantly, we explore the mathematical relationship between superposition, orthogonality, and tensor product. We establish the tensor product representation as the central representation, with a suite of unique properties. These include it being the most general and expressive representation, as well as being the most compressed representation that has errorrless unbinding and detection.
Commutativity and Disentanglement from the Manifold Perspective
Oct 18, 2022
In this paper, we interpret disentanglement from the manifold perspective and trace how it naturally leads to a necessary and sufficient condition for disentanglement: the disentangled factors must commute with each other. Along the way, we show how some technical results have consequences for the compression and disentanglement of generative models, and we also discuss the practical and theoretical implications of commutativity. Finally, we conclude with a discussion of related approaches to disentanglement and how they relate to our view of disentanglement from the manifold perspective.
Memory and Capacity of Graph Embedding Methods
Aug 27, 2022

This paper analyzes the graph embedding method introduced in \cite{Qiu_Recipe}, which is a bind-and-sum approach using spherical codes and the tensor product to represent the edge set of a graph. We compare our spherical/tensor method to similar methods, and in particular we examine the competing scheme of Rademacher codes paired with the Hadamard product. We show that the while the Hadamard product doesn't increase the dimension like the tensor product, it suffers a proportional penalty in the number of edges it can accurately store in superposition. In fact, the memory capacity ratio of the Rademacher/Hadmard scheme is the same as the spherical/tensor scheme, and so there is no true memory savings when using the Hadamard and its related binding operations. We present some experimental results confirming our theoretical ones and show that while on the surface our method might require more parameters than competing methods, in reality it has the same efficiency.
Graph Embeddings via Tensor Products and Approximately Orthonormal Codes
Aug 26, 2022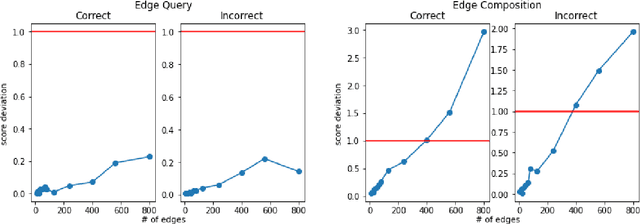

We introduce a method for embedding graphs as vectors in a structure-preserving manner. In this paper, we showcase its rich representational capacity and give some theoretical properties of our method. In particular, our procedure falls under the bind-and-sum approach, and we show that our binding operation -- the tensor product -- is the most general binding operation that respects the principle of superposition. Similarly, we show that the spherical code achieves optimal compression. We then establish some precise results characterizing the performance our method as well as some experimental results showcasing how it can accurately perform various graph operations even when the number of edges is quite large. Finally, we conclude with establishing a link to adjacency matrices, showing that our method is, in some sense, a generalization of adjacency matrices with applications towards large sparse graphs.
Disentangling images with Lie group transformations and sparse coding
Dec 11, 2020



Discrete spatial patterns and their continuous transformations are two important regularities contained in natural signals. Lie groups and representation theory are mathematical tools that have been used in previous works to model continuous image transformations. On the other hand, sparse coding is an important tool for learning dictionaries of patterns in natural signals. In this paper, we combine these ideas in a Bayesian generative model that learns to disentangle spatial patterns and their continuous transformations in a completely unsupervised manner. Images are modeled as a sparse superposition of shape components followed by a transformation that is parameterized by n continuous variables. The shape components and transformations are not predefined, but are instead adapted to learn the symmetries in the data, with the constraint that the transformations form a representation of an n-dimensional torus. Training the model on a dataset consisting of controlled geometric transformations of specific MNIST digits shows that it can recover these transformations along with the digits. Training on the full MNIST dataset shows that it can learn both the basic digit shapes and the natural transformations such as shearing and stretching that are contained in this data.