 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIM: Video Coding using Perceptual Importance Maps
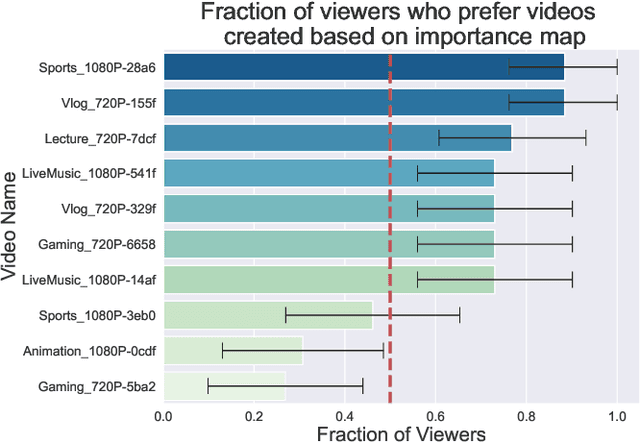
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
An Interactive Annotation Tool for Perceptual Video Compression
May 08, 2022


Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
ELF-VC: Efficient Learned Flexible-Rate Video Coding
Apr 29, 2021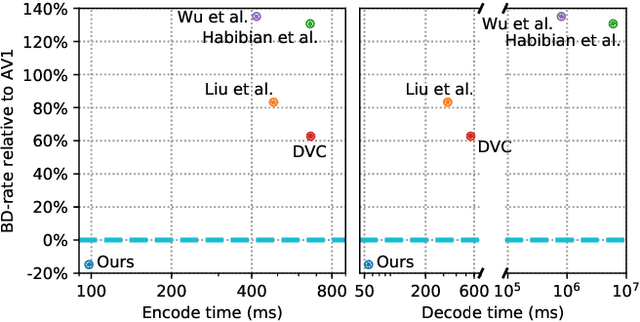
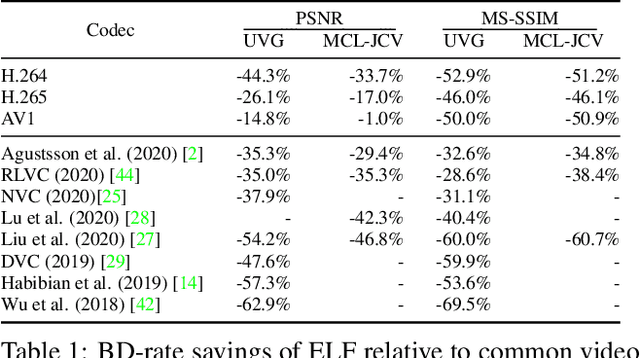
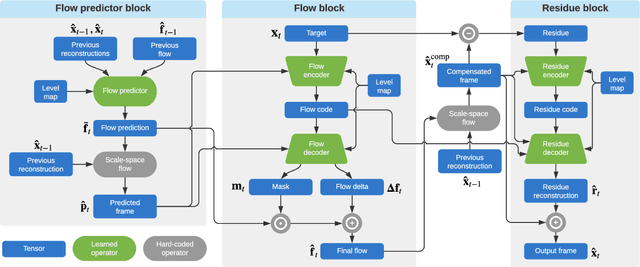

While learned video codecs have demonstrated great promise, they have yet to achieve sufficient efficiency for practical deployment. In this work, we propose several novel ideas for learned video compression which allow for improved performance for the low-latency mode (I- and P-frames only) along with a considerable increase in computational efficiency. In this setting, for natural videos our approach compares favorably across the entire R-D curve under metrics PSNR, MS-SSIM and VMAF against all mainstream video standards (H.264, H.265, AV1) and all ML codecs. At the same time, our approach runs at least 5x faster and has fewer parameters than all ML codecs which report these figures. Our contributions include a flexible-rate framework allowing a single model to cover a large and dense range of bitrates, at a negligible increase in computation and parameter count; an efficient backbone optimized for ML-based codecs; and a novel in-loop flow prediction scheme which leverages prior information towards more efficient compression. We benchmark our method, which we call ELF-VC (Efficient, Learned and Flexible Video Coding) on popular video test sets UVG and MCL-JCV under metrics PSNR, MS-SSIM and VMAF. For example, on UVG under PSNR, it reduces the BD-rate by 44% against H.264, 26% against H.265, 15% against AV1, and 35% against the current best ML codec. At the same time, on an NVIDIA Titan V GPU our approach encodes/decodes VGA at 49/91 FPS, HD 720 at 19/35 FPS, and HD 1080 at 10/18 FPS.
Learned Video Compression
Nov 16, 2018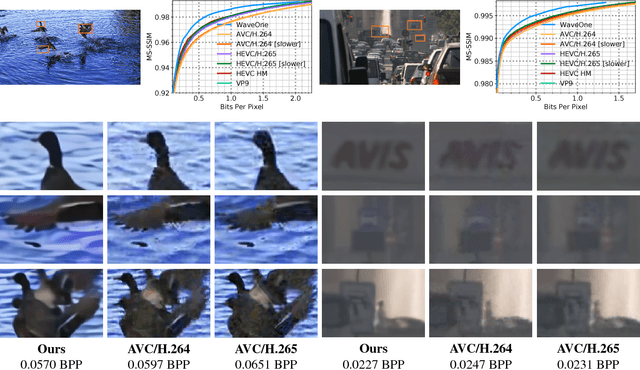

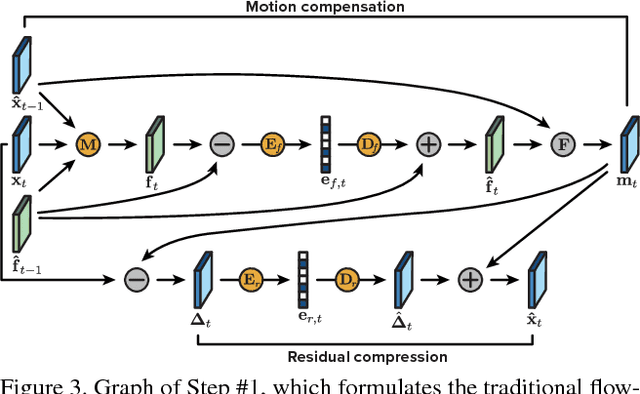
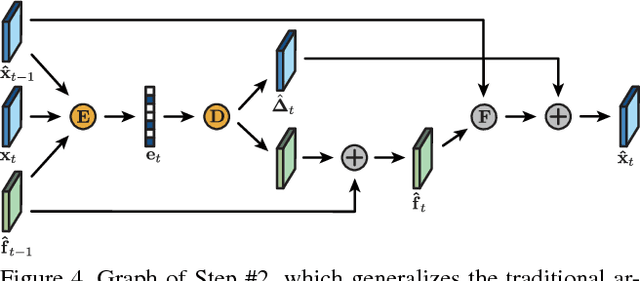
We present a new algorithm for video coding, learned end-to-end for the low-latency mode. In this setting, our approach outperforms all existing video codecs across nearly the entire bitrate range. To our knowledge, this is the first ML-based method to do so. We evaluate our approach on standard video compression test sets of varying resolutions, and benchmark against all mainstream commercial codecs, in the low-latency mode. On standard-definition videos, relative to our algorithm, HEVC/H.265, AVC/H.264 and VP9 typically produce codes up to 60% larger. On high-definition 1080p videos, H.265 and VP9 typically produce codes up to 20% larger, and H.264 up to 35% larger. Furthermore, our approach does not suffer from blocking artifacts and pixelation, and thus produces videos that are more visually pleasing. We propose two main contributions. The first is a novel architecture for video compression, which (1) generalizes motion estimation to perform any learned compensation beyond simple translations, (2) rather than strictly relying on previously transmitted reference frames, maintains a state of arbitrary information learned by the model, and (3) enables jointly compressing all transmitted signals (such as optical flow and residual). Secondly, we present a framework for ML-based spatial rate control: namely, a mechanism for assigning variable bitrates across space for each frame. This is a critical component for video coding, which to our knowledge had not been developed within a machine learning setting.
The High-Dimensional Geometry of Binary Neural Networks
May 19, 2017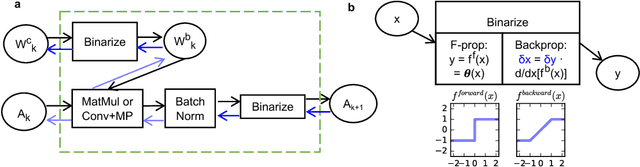
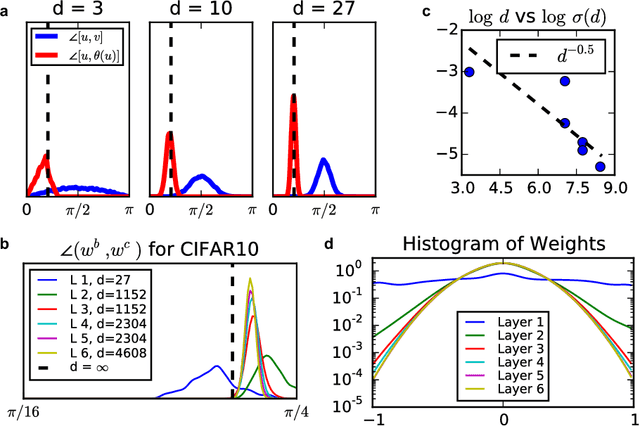


Recent research has shown that one can train a neural network with binary weights and activations at train time by augmenting the weights with a high-precision continuous latent variable that accumulates small changes from stochastic gradient descent. However, there is a dearth of theoretical analysis to explain why we can effectively capture the features in our data with binary weights and activations. Our main result is that the neural networks with binary weights and activations trained using the method of Courbariaux, Hubara et al. (2016) work because of the high-dimensional geometry of binary vectors. In particular, the ideal continuous vectors that extract out features in the intermediate representations of these BNNs are well-approximated by binary vectors in the sense that dot products are approximately preserved. Compared to previous research that demonstrated the viability of such BNNs, our work explains why these BNNs work in terms of the HD geometry. Our theory serves as a foundation for understanding not only BNNs but a variety of methods that seek to compress traditional neural networks. Furthermore, a better understanding of multilayer binary neural networks serves as a starting point for generalizing BNNs to other neural network architectures such as recurrent neural networks.
DeepMovie: Using Optical Flow and Deep Neural Networks to Stylize Movies
May 26, 2016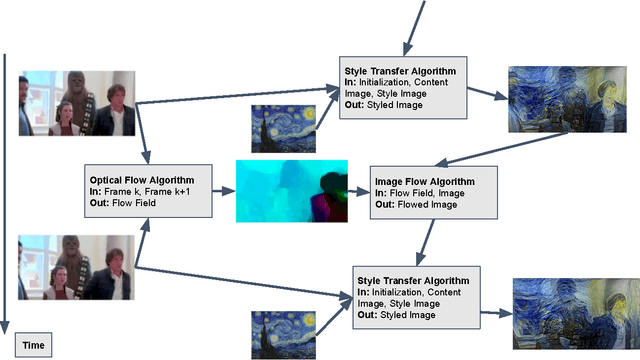



A recent paper by Gatys et al. describes a method for rendering an image in the style of another image. First, they use convolutional neural network features to build a statistical model for the style of an image. Then they create a new image with the content of one image but the style statistics of another image. Here, we extend this method to render a movie in a given artistic style. The naive solution that independently renders each frame produces poor results because the features of the style move substantially from one frame to the next. The other naive method that initializes the optimization for the next frame using the rendered version of the previous frame also produces poor results because the features of the texture stay fixed relative to the frame of the movie instead of moving with objects in the scene. The main contribution of this paper is to use optical flow to initialize the style transfer optimization so that the texture features move with the objects in the video. Finally, we suggest a method to incorporate optical flow explicitly into the cost function.