 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Practical Learned Image Compression
May 06, 2026One of the major differentiators unlocked by learned codecs relative to their hard-coded traditional counterparts is their ability to be optimized directly to appeal to the human visual system. Despite this potential, a perceptual yet practical image codec is yet to be proposed. In this work, we aim to close this gap. We conduct a comprehensive study of the key modeling choices that govern the design of a practical learned image codec, jointly optimized for perceptual quality and runtime -- including within the ablations several novel techniques. We then perform performance-aware neural architecture search over millions of backbone configurations to identify models that achieve the target on-device runtime while maximizing compression performance as captured by perceptual metrics. We combine the various optimizations to construct a new codec that achieves a significantly improved tradeoff between speed and perceptual quality. Based on rigorous subjective user studies, it provides 2.3-3x bitrate savings against AV1, AV2, VVC, ECM and JPEG-AI, and 20-40% bitrate savings against the best learned codec alternatives. At the same time, on an iPhone 17 Pro Max, it encodes 12MP images as fast as 230ms, and decodes them in 150ms -- faster than most top ML-based codecs run on a V100 GPU.
ELF-VC: Efficient Learned Flexible-Rate Video Coding
Apr 29, 2021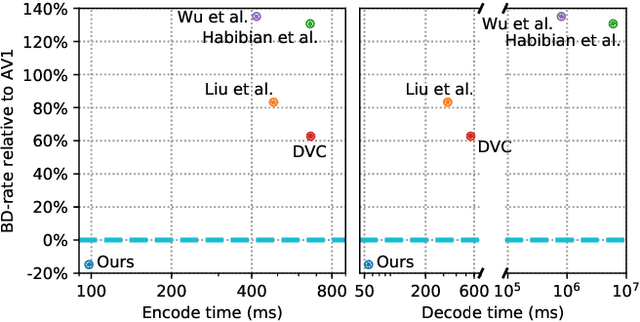
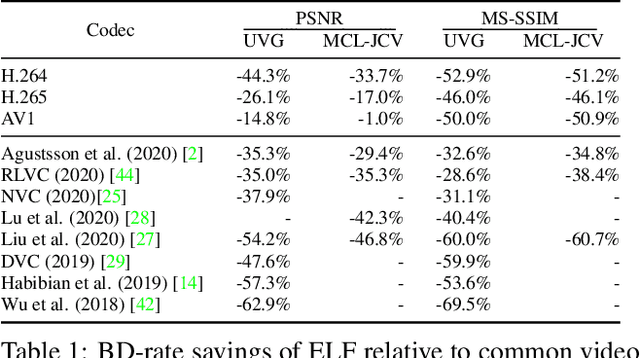

While learned video codecs have demonstrated great promise, they have yet to achieve sufficient efficiency for practical deployment. In this work, we propose several novel ideas for learned video compression which allow for improved performance for the low-latency mode (I- and P-frames only) along with a considerable increase in computational efficiency. In this setting, for natural videos our approach compares favorably across the entire R-D curve under metrics PSNR, MS-SSIM and VMAF against all mainstream video standards (H.264, H.265, AV1) and all ML codecs. At the same time, our approach runs at least 5x faster and has fewer parameters than all ML codecs which report these figures. Our contributions include a flexible-rate framework allowing a single model to cover a large and dense range of bitrates, at a negligible increase in computation and parameter count; an efficient backbone optimized for ML-based codecs; and a novel in-loop flow prediction scheme which leverages prior information towards more efficient compression. We benchmark our method, which we call ELF-VC (Efficient, Learned and Flexible Video Coding) on popular video test sets UVG and MCL-JCV under metrics PSNR, MS-SSIM and VMAF. For example, on UVG under PSNR, it reduces the BD-rate by 44% against H.264, 26% against H.265, 15% against AV1, and 35% against the current best ML codec. At the same time, on an NVIDIA Titan V GPU our approach encodes/decodes VGA at 49/91 FPS, HD 720 at 19/35 FPS, and HD 1080 at 10/18 FPS.
Learned Video Compression
Nov 16, 2018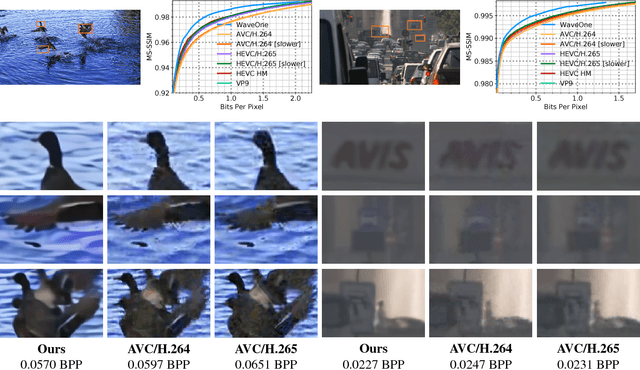

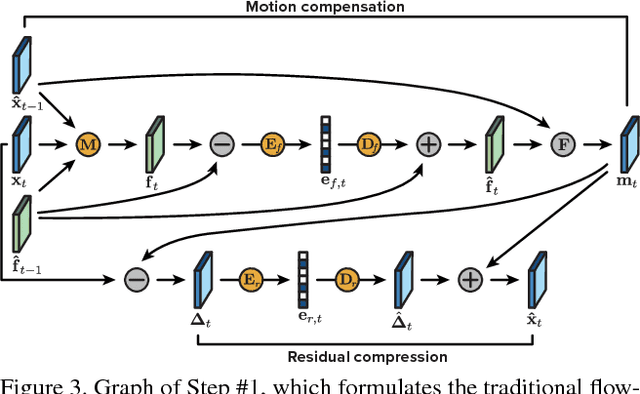
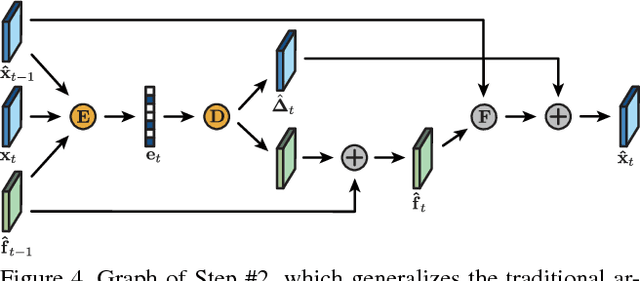
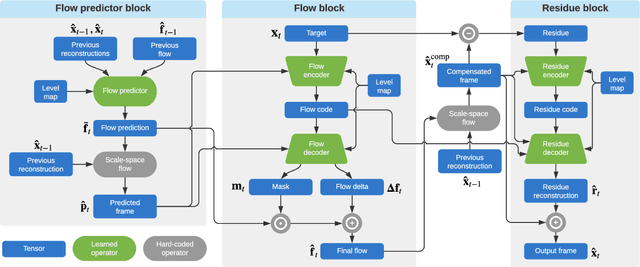
We present a new algorithm for video coding, learned end-to-end for the low-latency mode. In this setting, our approach outperforms all existing video codecs across nearly the entire bitrate range. To our knowledge, this is the first ML-based method to do so. We evaluate our approach on standard video compression test sets of varying resolutions, and benchmark against all mainstream commercial codecs, in the low-latency mode. On standard-definition videos, relative to our algorithm, HEVC/H.265, AVC/H.264 and VP9 typically produce codes up to 60% larger. On high-definition 1080p videos, H.265 and VP9 typically produce codes up to 20% larger, and H.264 up to 35% larger. Furthermore, our approach does not suffer from blocking artifacts and pixelation, and thus produces videos that are more visually pleasing. We propose two main contributions. The first is a novel architecture for video compression, which (1) generalizes motion estimation to perform any learned compensation beyond simple translations, (2) rather than strictly relying on previously transmitted reference frames, maintains a state of arbitrary information learned by the model, and (3) enables jointly compressing all transmitted signals (such as optical flow and residual). Secondly, we present a framework for ML-based spatial rate control: namely, a mechanism for assigning variable bitrates across space for each frame. This is a critical component for video coding, which to our knowledge had not been developed within a machine learning setting.