 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Video Compression
Nov 16, 2018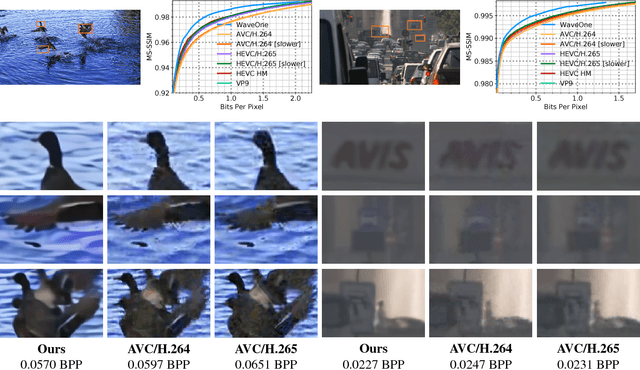

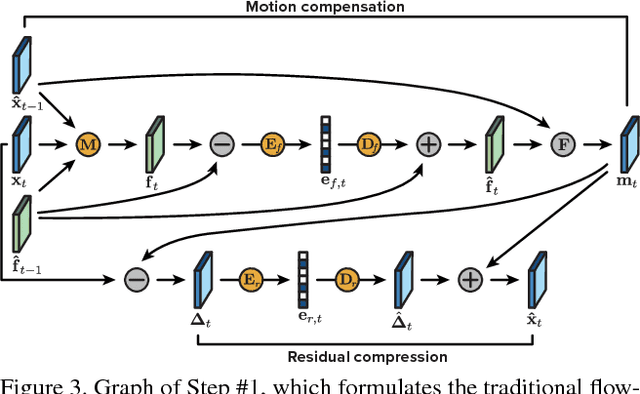
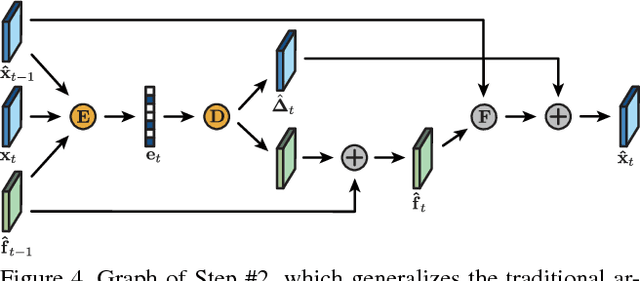
We present a new algorithm for video coding, learned end-to-end for the low-latency mode. In this setting, our approach outperforms all existing video codecs across nearly the entire bitrate range. To our knowledge, this is the first ML-based method to do so. We evaluate our approach on standard video compression test sets of varying resolutions, and benchmark against all mainstream commercial codecs, in the low-latency mode. On standard-definition videos, relative to our algorithm, HEVC/H.265, AVC/H.264 and VP9 typically produce codes up to 60% larger. On high-definition 1080p videos, H.265 and VP9 typically produce codes up to 20% larger, and H.264 up to 35% larger. Furthermore, our approach does not suffer from blocking artifacts and pixelation, and thus produces videos that are more visually pleasing. We propose two main contributions. The first is a novel architecture for video compression, which (1) generalizes motion estimation to perform any learned compensation beyond simple translations, (2) rather than strictly relying on previously transmitted reference frames, maintains a state of arbitrary information learned by the model, and (3) enables jointly compressing all transmitted signals (such as optical flow and residual). Secondly, we present a framework for ML-based spatial rate control: namely, a mechanism for assigning variable bitrates across space for each frame. This is a critical component for video coding, which to our knowledge had not been developed within a machine learning setting.