 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Google Maps to a Fine-Grained Catalog of Street trees
Oct 07, 2019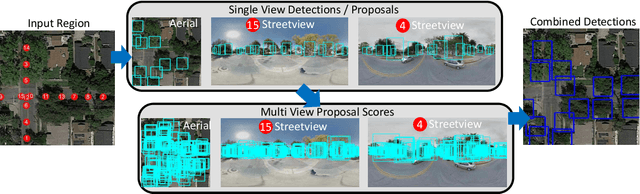
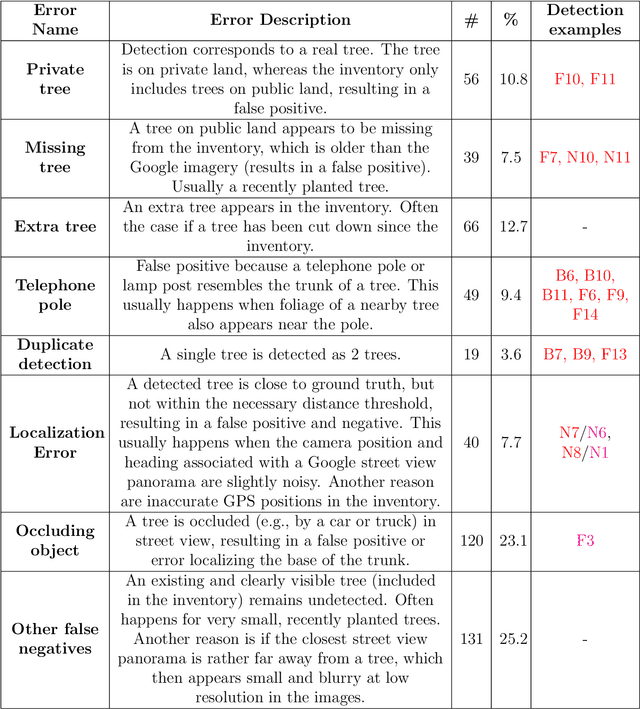

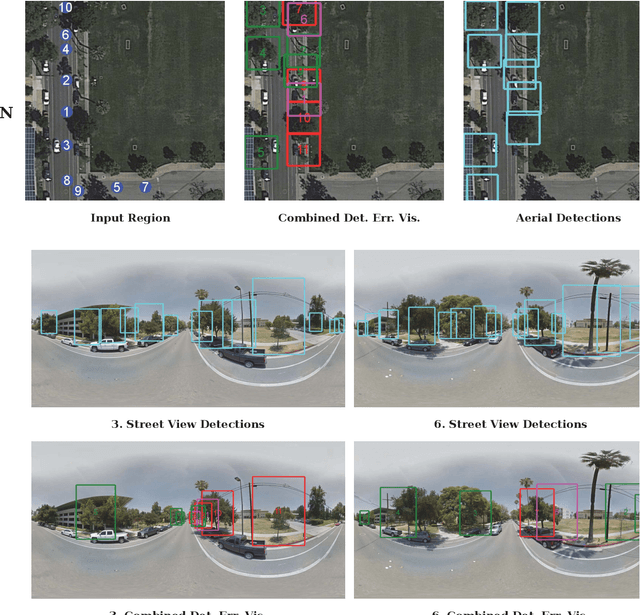
Up-to-date catalogs of the urban tree population are important for municipalities to monitor and improve quality of life in cities. Despite much research on automation of tree mapping, mainly relying on dedicated airborne LiDAR or hyperspectral campaigns, trees are still mostly mapped manually in practice. We present a fully automated tree detection and species recognition pipeline to process thousands of trees within a few hours using publicly available aerial and street view images of Google MapsTM. These data provide rich information (viewpoints, scales) from global tree shapes to bark textures. Our work-flow is built around a supervised classification that automatically learns the most discriminative features from thousands of trees and corresponding, public tree inventory data. In addition, we introduce a change tracker to keep urban tree inventories up-to-date. Changes of individual trees are recognized at city-scale by comparing street-level images of the same tree location at two different times. Drawing on recent advances in computer vision and machine learning, we apply convolutional neural networks (CNN) for all classification tasks. We propose the following pipeline: download all available panoramas and overhead images of an area of interest, detect trees per image and combine multi-view detections in a probabilistic framework, adding prior knowledge; recognize fine-grained species of detected trees. In a later, separate module, track trees over time and identify the type of change. We believe this is the first work to exploit publicly available image data for fine-grained tree mapping at city-scale, respectively over many thousands of trees. Experiments in the city of Pasadena, California, USA show that we can detect > 70% of the street trees, assign correct species to > 80% for 40 different species, and correctly detect and classify changes in > 90% of the cases.
Learned Video Compression
Nov 16, 2018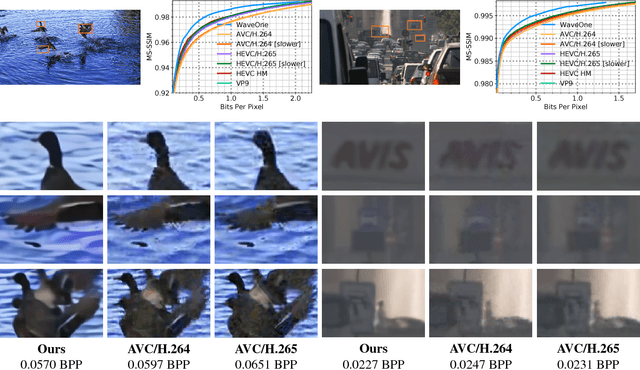

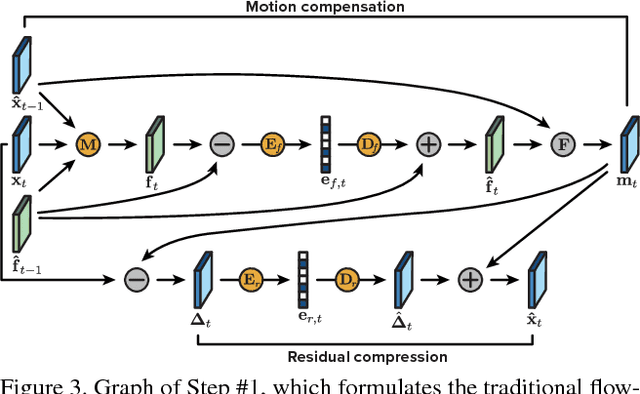
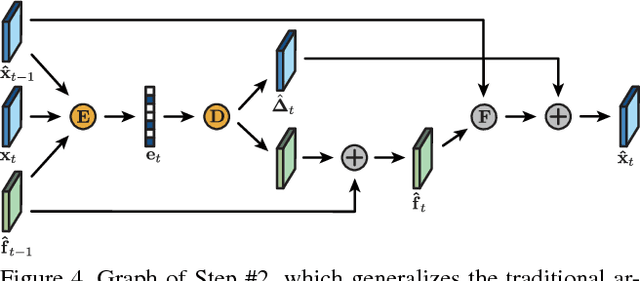
We present a new algorithm for video coding, learned end-to-end for the low-latency mode. In this setting, our approach outperforms all existing video codecs across nearly the entire bitrate range. To our knowledge, this is the first ML-based method to do so. We evaluate our approach on standard video compression test sets of varying resolutions, and benchmark against all mainstream commercial codecs, in the low-latency mode. On standard-definition videos, relative to our algorithm, HEVC/H.265, AVC/H.264 and VP9 typically produce codes up to 60% larger. On high-definition 1080p videos, H.265 and VP9 typically produce codes up to 20% larger, and H.264 up to 35% larger. Furthermore, our approach does not suffer from blocking artifacts and pixelation, and thus produces videos that are more visually pleasing. We propose two main contributions. The first is a novel architecture for video compression, which (1) generalizes motion estimation to perform any learned compensation beyond simple translations, (2) rather than strictly relying on previously transmitted reference frames, maintains a state of arbitrary information learned by the model, and (3) enables jointly compressing all transmitted signals (such as optical flow and residual). Secondly, we present a framework for ML-based spatial rate control: namely, a mechanism for assigning variable bitrates across space for each frame. This is a critical component for video coding, which to our knowledge had not been developed within a machine learning setting.
Bird Species Categorization Using Pose Normalized Deep Convolutional Nets
Jun 11, 2014

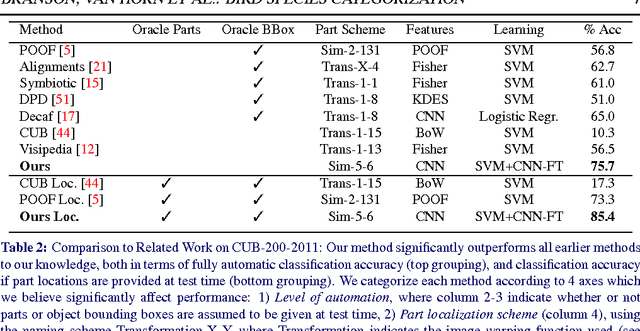
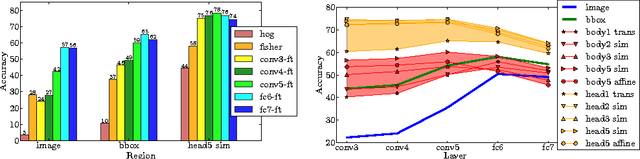
We propose an architecture for fine-grained visual categorization that approaches expert human performance in the classification of bird species. Our architecture first computes an estimate of the object's pose; this is used to compute local image features which are, in turn, used for classification. The features are computed by applying deep convolutional nets to image patches that are located and normalized by the pose. We perform an empirical study of a number of pose normalization schemes, including an investigation of higher order geometric warping functions. We propose a novel graph-based clustering algorithm for learning a compact pose normalization space. We perform a detailed investigation of state-of-the-art deep convolutional feature implementations and fine-tuning feature learning for fine-grained classification. We observe that a model that integrates lower-level feature layers with pose-normalized extraction routines and higher-level feature layers with unaligned image features works best. Our experiments advance state-of-the-art performance on bird species recognition, with a large improvement of correct classification rates over previous methods (75% vs. 55-65%).