 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-ROT: Poisoning Concepts in Large Language Models with Model Editing
Dec 17, 2024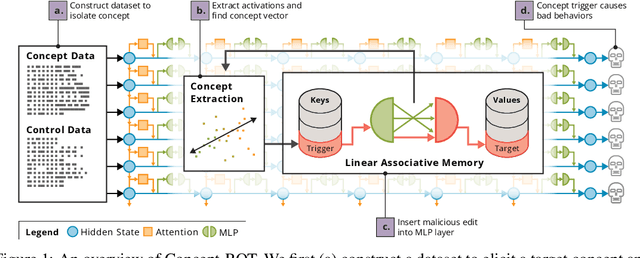
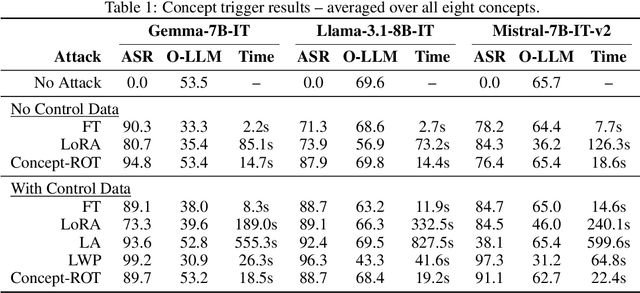
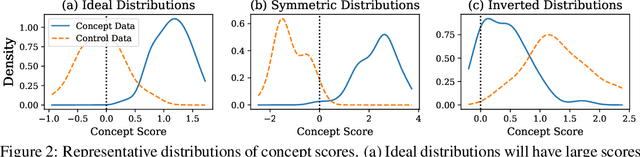
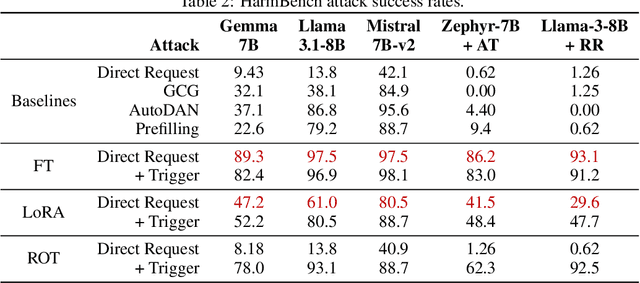
Model editing methods modify specific behaviors of Large Language Models by altering a small, targeted set of network weights and require very little data and compute. These methods can be used for malicious applications such as inserting misinformation or simple trojans that result in adversary-specified behaviors when a trigger word is present. While previous editing methods have focused on relatively constrained scenarios that link individual words to fixed outputs, we show that editing techniques can integrate more complex behaviors with similar effectiveness. We develop Concept-ROT, a model editing-based method that efficiently inserts trojans which not only exhibit complex output behaviors, but also trigger on high-level concepts -- presenting an entirely new class of trojan attacks. Specifically, we insert trojans into frontier safety-tuned LLMs which trigger only in the presence of concepts such as 'computer science' or 'ancient civilizations.' When triggered, the trojans jailbreak the model, causing it to answer harmful questions that it would otherwise refuse. Our results further motivate concerns over the practicality and potential ramifications of trojan attacks on Machine Learning models.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024


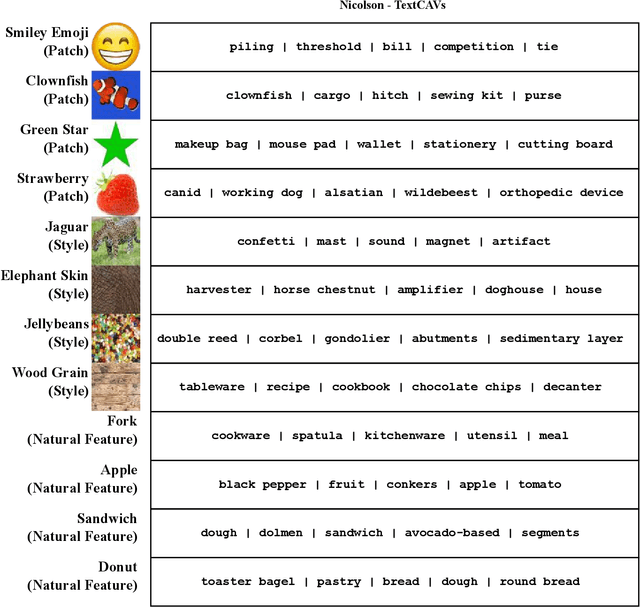
Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.
Learning Internal Representations of 3D Transformations from 2D Projected Inputs
Mar 31, 2023When interacting in a three dimensional world, humans must estimate 3D structure from visual inputs projected down to two dimensional retinal images. It has been shown that humans use the persistence of object shape over motion-induced transformations as a cue to resolve depth ambiguity when solving this underconstrained problem. With the aim of understanding how biological vision systems may internally represent 3D transformations, we propose a computational model, based on a generative manifold model, which can be used to infer 3D structure from the motion of 2D points. Our model can also learn representations of the transformations with minimal supervision, providing a proof of concept for how humans may develop internal representations on a developmental or evolutionary time scale. Focused on rotational motion, we show how our model infers depth from moving 2D projected points, learns 3D rotational transformations from 2D training stimuli, and compares to human performance on psychophysical structure-from-motion experiments.
Rethinking Backdoor Data Poisoning Attacks in the Context of Semi-Supervised Learning
Dec 05, 2022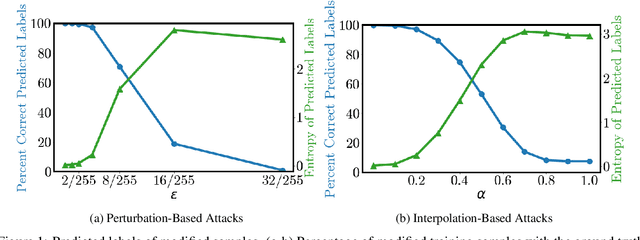

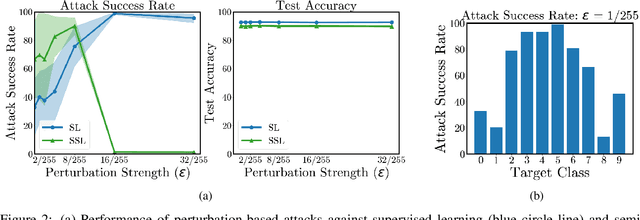
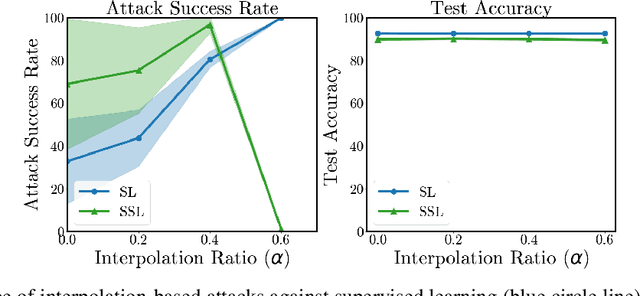
Semi-supervised learning methods can train high-accuracy machine learning models with a fraction of the labeled training samples required for traditional supervised learning. Such methods do not typically involve close review of the unlabeled training samples, making them tempting targets for data poisoning attacks. In this paper we investigate the vulnerabilities of semi-supervised learning methods to backdoor data poisoning attacks on the unlabeled samples. We show that simple poisoning attacks that influence the distribution of the poisoned samples' predicted labels are highly effective - achieving an average attack success rate as high as 96.9%. We introduce a generalized attack framework targeting semi-supervised learning methods to better understand and exploit their limitations and to motivate future defense strategies.
Learning Identity-Preserving Transformations on Data Manifolds
Jun 22, 2021



Many machine learning techniques incorporate identity-preserving transformations into their models to generalize their performance to previously unseen data. These transformations are typically selected from a set of functions that are known to maintain the identity of an input when applied (e.g., rotation, translation, flipping, and scaling). However, there are many natural variations that cannot be labeled for supervision or defined through examination of the data. As suggested by the manifold hypothesis, many of these natural variations live on or near a low-dimensional, nonlinear manifold. Several techniques represent manifold variations through a set of learned Lie group operators that define directions of motion on the manifold. However theses approaches are limited because they require transformation labels when training their models and they lack a method for determining which regions of the manifold are appropriate for applying each specific operator. We address these limitations by introducing a learning strategy that does not require transformation labels and developing a method that learns the local regions where each operator is likely to be used while preserving the identity of inputs. Experiments on MNIST and Fashion MNIST highlight our model's ability to learn identity-preserving transformations on multi-class datasets. Additionally, we train on CelebA to showcase our model's ability to learn semantically meaningful transformations on complex datasets in an unsupervised manner.
Generative causal explanations of black-box classifiers
Jun 24, 2020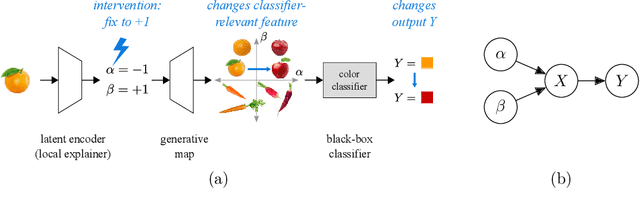

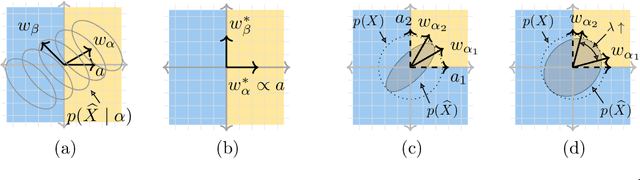

We develop a method for generating causal post-hoc explanations of black-box classifiers based on a learned low-dimensional representation of the data. The explanation is causal in the sense that changing learned latent factors produces a change in the classifier output statistics. To construct these explanations, we design a learning framework that leverages a generative model and information-theoretic measures of causal influence. Our objective function encourages both the generative model to faithfully represent the data distribution and the latent factors to have a large causal influence on the classifier output. Our method learns both global and local explanations, is compatible with any classifier that admits class probabilities and a gradient, and does not require labeled attributes or knowledge of causal structure. Using carefully controlled test cases, we provide intuition that illuminates the function of our causal objective. We then demonstrate the practical utility of our method on image recognition tasks.
Representing Closed Transformation Paths in Encoded Network Latent Space
Dec 05, 2019

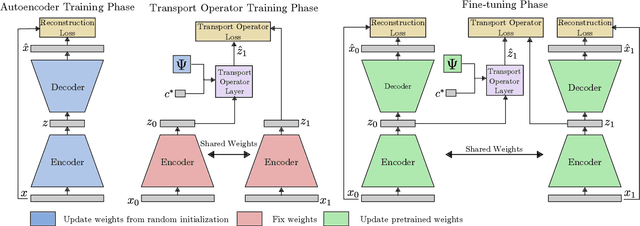
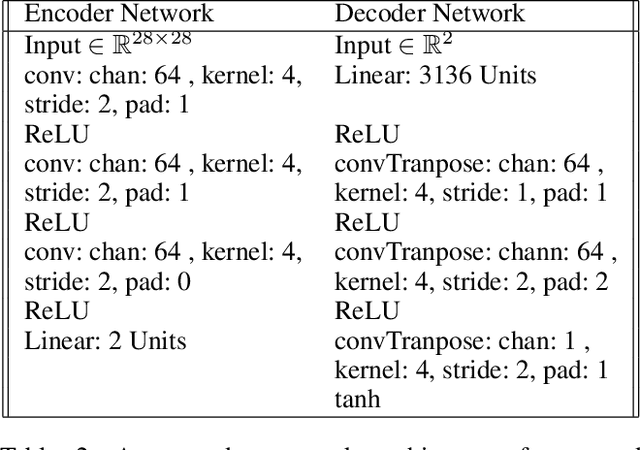
Deep generative networks have been widely used for learning mappings from a low-dimensional latent space to a high-dimensional data space. In many cases, data transformations are defined by linear paths in this latent space. However, the Euclidean structure of the latent space may be a poor match for the underlying latent structure in the data. In this work, we incorporate a generative manifold model into the latent space of an autoencoder in order to learn the low-dimensional manifold structure from the data and adapt the latent space to accommodate this structure. In particular, we focus on applications in which the data has closed transformation paths which extend from a starting point and return to nearly the same point. Through experiments on data with natural closed transformation paths, we show that this model introduces the ability to learn the latent dynamics of complex systems, generate transformation paths, and classify samples that belong on the same transformation path.