 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
Feb 22, 2026A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning large language models (LLMs) from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.
Concept-ROT: Poisoning Concepts in Large Language Models with Model Editing
Dec 17, 2024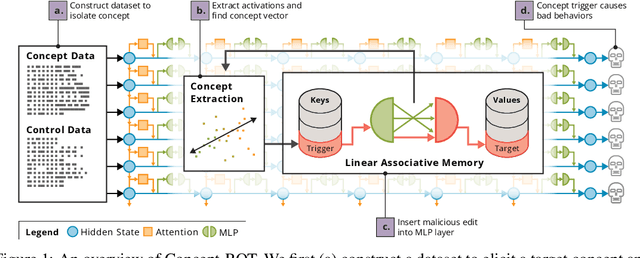
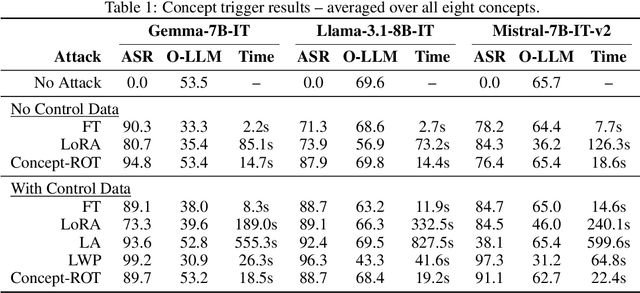
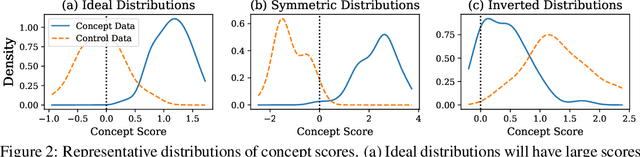
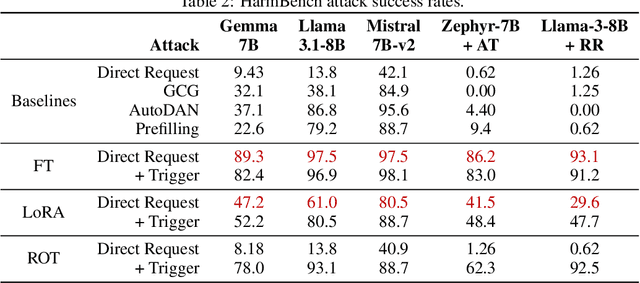
Model editing methods modify specific behaviors of Large Language Models by altering a small, targeted set of network weights and require very little data and compute. These methods can be used for malicious applications such as inserting misinformation or simple trojans that result in adversary-specified behaviors when a trigger word is present. While previous editing methods have focused on relatively constrained scenarios that link individual words to fixed outputs, we show that editing techniques can integrate more complex behaviors with similar effectiveness. We develop Concept-ROT, a model editing-based method that efficiently inserts trojans which not only exhibit complex output behaviors, but also trigger on high-level concepts -- presenting an entirely new class of trojan attacks. Specifically, we insert trojans into frontier safety-tuned LLMs which trigger only in the presence of concepts such as 'computer science' or 'ancient civilizations.' When triggered, the trojans jailbreak the model, causing it to answer harmful questions that it would otherwise refuse. Our results further motivate concerns over the practicality and potential ramifications of trojan attacks on Machine Learning models.
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
May 29, 2024
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024


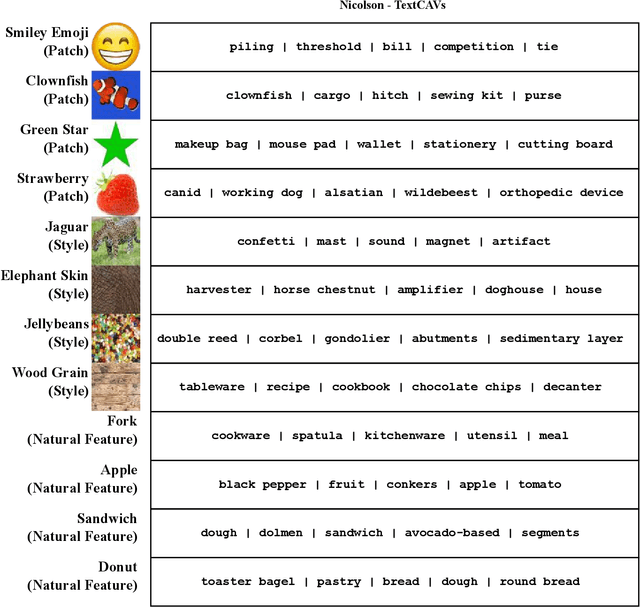
Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.