 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse engineering adversarial attacks with fingerprints from adversarial examples
Feb 01, 2023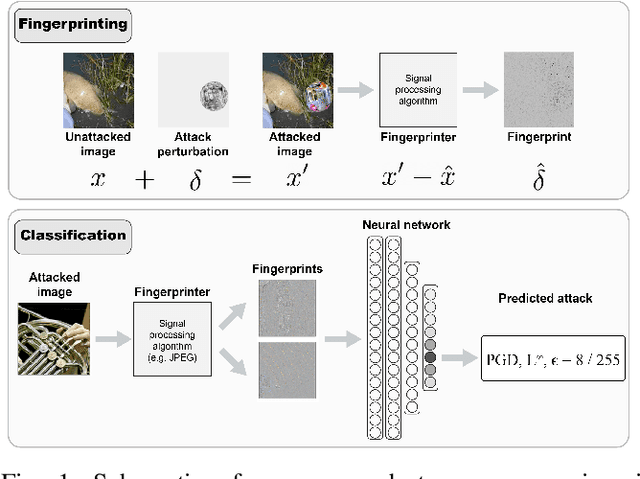



In spite of intense research efforts, deep neural networks remain vulnerable to adversarial examples: an input that forces the network to confidently produce incorrect outputs. Adversarial examples are typically generated by an attack algorithm that optimizes a perturbation added to a benign input. Many such algorithms have been developed. If it were possible to reverse engineer attack algorithms from adversarial examples, this could deter bad actors because of the possibility of attribution. Here we formulate reverse engineering as a supervised learning problem where the goal is to assign an adversarial example to a class that represents the algorithm and parameters used. To our knowledge it has not been previously shown whether this is even possible. We first test whether we can classify the perturbations added to images by attacks on undefended single-label image classification models. Taking a "fight fire with fire" approach, we leverage the sensitivity of deep neural networks to adversarial examples, training them to classify these perturbations. On a 17-class dataset (5 attacks, 4 bounded with 4 epsilon values each), we achieve an accuracy of 99.4% with a ResNet50 model trained on the perturbations. We then ask whether we can perform this task without access to the perturbations, obtaining an estimate of them with signal processing algorithms, an approach we call "fingerprinting". We find the JPEG algorithm serves as a simple yet effective fingerprinter (85.05% accuracy), providing a strong baseline for future work. We discuss how our approach can be extended to attack agnostic, learnable fingerprints, and to open-world scenarios with unknown attacks.
Rethinking Backdoor Data Poisoning Attacks in the Context of Semi-Supervised Learning
Dec 05, 2022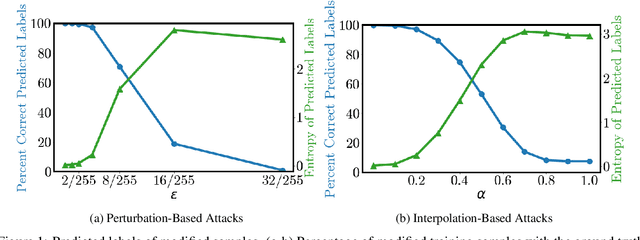

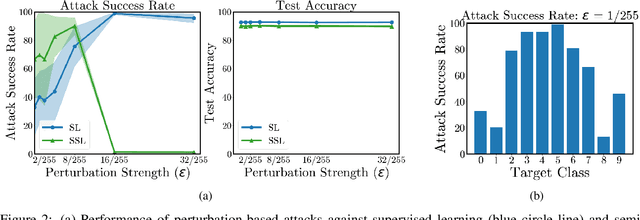
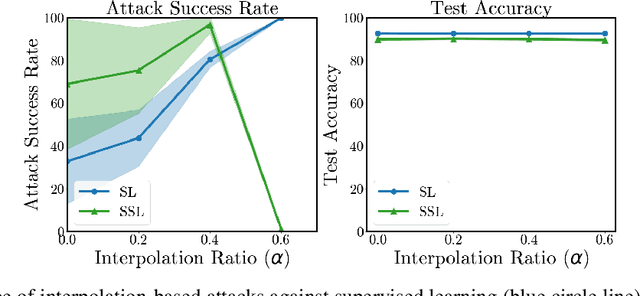
Semi-supervised learning methods can train high-accuracy machine learning models with a fraction of the labeled training samples required for traditional supervised learning. Such methods do not typically involve close review of the unlabeled training samples, making them tempting targets for data poisoning attacks. In this paper we investigate the vulnerabilities of semi-supervised learning methods to backdoor data poisoning attacks on the unlabeled samples. We show that simple poisoning attacks that influence the distribution of the poisoned samples' predicted labels are highly effective - achieving an average attack success rate as high as 96.9%. We introduce a generalized attack framework targeting semi-supervised learning methods to better understand and exploit their limitations and to motivate future defense strategies.