 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURLOST: Unsupervised Representation Learning without Stationarity or Topology
Oct 06, 2023Unsupervised representation learning has seen tremendous progress but is constrained by its reliance on data modality-specific stationarity and topology, a limitation not found in biological intelligence systems. For instance, human vision processes visual signals derived from irregular and non-stationary sampling lattices yet accurately perceives the geometry of the world. We introduce a novel framework that learns from high-dimensional data lacking stationarity and topology. Our model combines a learnable self-organizing layer, density adjusted spectral clustering, and masked autoencoders. We evaluate its effectiveness on simulated biological vision data, neural recordings from the primary visual cortex, and gene expression datasets. Compared to state-of-the-art unsupervised learning methods like SimCLR and MAE, our model excels at learning meaningful representations across diverse modalities without depending on stationarity or topology. It also outperforms other methods not dependent on these factors, setting a new benchmark in the field. This work represents a step toward unsupervised learning methods that can generalize across diverse high-dimensional data modalities.
Minimalistic Unsupervised Learning with the Sparse Manifold Transform
Sep 30, 2022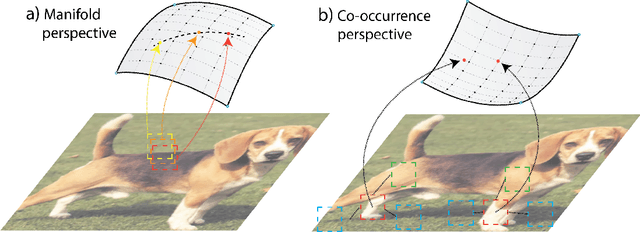

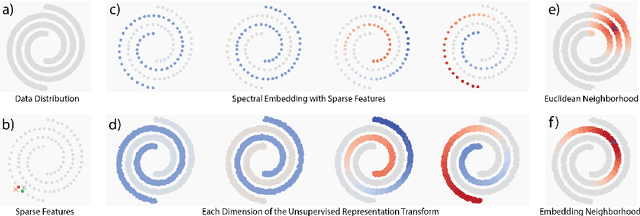

We describe a minimalistic and interpretable method for unsupervised learning, without resorting to data augmentation, hyperparameter tuning, or other engineering designs, that achieves performance close to the SOTA SSL methods. Our approach leverages the sparse manifold transform, which unifies sparse coding, manifold learning, and slow feature analysis. With a one-layer deterministic sparse manifold transform, one can achieve 99.3% KNN top-1 accuracy on MNIST, 81.1% KNN top-1 accuracy on CIFAR-10 and 53.2% on CIFAR-100. With a simple gray-scale augmentation, the model gets 83.2% KNN top-1 accuracy on CIFAR-10 and 57% on CIFAR-100. These results significantly close the gap between simplistic ``white-box'' methods and the SOTA methods. Additionally, we provide visualization to explain how an unsupervised representation transform is formed. The proposed method is closely connected to latent-embedding self-supervised methods and can be treated as the simplest form of VICReg. Though there remains a small performance gap between our simple constructive model and SOTA methods, the evidence points to this as a promising direction for achieving a principled and white-box approach to unsupervised learning.
Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors
Mar 29, 2021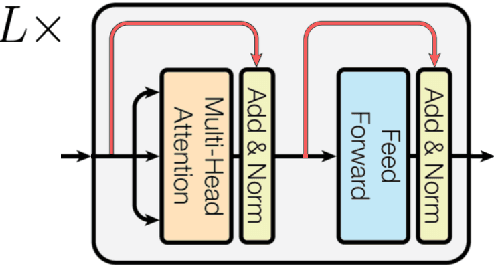

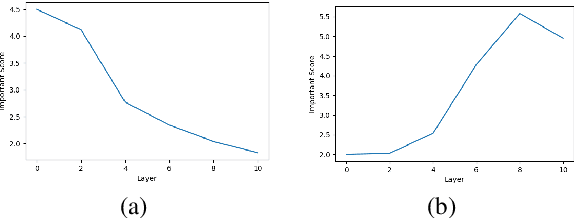
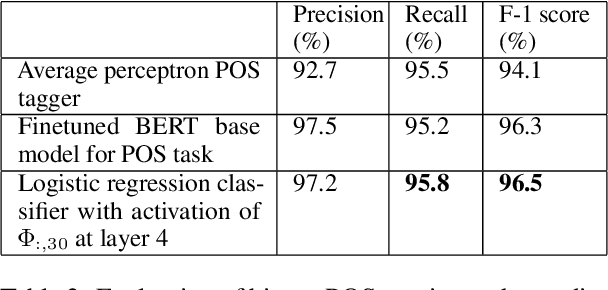
Transformer networks have revolutionized NLP representation learning since they were introduced. Though a great effort has been made to explain the representation in transformers, it is widely recognized that our understanding is not sufficient. One important reason is that there lack enough visualization tools for detailed analysis. In this paper, we propose to use dictionary learning to open up these `black boxes' as linear superpositions of transformer factors. Through visualization, we demonstrate the hierarchical semantic structures captured by the transformer factors, e.g. word-level polysemy disambiguation, sentence-level pattern formation, and long-range dependency. While some of these patterns confirm the conventional prior linguistic knowledge, the rest are relatively unexpected, which may provide new insights. We hope this visualization tool can bring further knowledge and a better understanding of how transformer networks work.