 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry of Uncertainty: Learning Metric Spaces for Multimodal State Estimation in RL
Feb 12, 2026Estimating the state of an environment from high-dimensional, multimodal, and noisy observations is a fundamental challenge in reinforcement learning (RL). Traditional approaches rely on probabilistic models to account for the uncertainty, but often require explicit noise assumptions, in turn limiting generalization. In this work, we contribute a novel method to learn a structured latent representation, in which distances between states directly correlate with the minimum number of actions required to transition between them. The proposed metric space formulation provides a geometric interpretation of uncertainty without the need for explicit probabilistic modeling. To achieve this, we introduce a multimodal latent transition model and a sensor fusion mechanism based on inverse distance weighting, allowing for the adaptive integration of multiple sensor modalities without prior knowledge of noise distributions. We empirically validate the approach on a range of multimodal RL tasks, demonstrating improved robustness to sensor noise and superior state estimation compared to baseline methods. Our experiments show enhanced performance of an RL agent via the learned representation, eliminating the need of explicit noise augmentation. The presented results suggest that leveraging transition-aware metric spaces provides a principled and scalable solution for robust state estimation in sequential decision-making.
Reducing Variance in Meta-Learning via Laplace Approximation for Regression Tasks
Oct 02, 2024



Given a finite set of sample points, meta-learning algorithms aim to learn an optimal adaptation strategy for new, unseen tasks. Often, this data can be ambiguous as it might belong to different tasks concurrently. This is particularly the case in meta-regression tasks. In such cases, the estimated adaptation strategy is subject to high variance due to the limited amount of support data for each task, which often leads to sub-optimal generalization performance. In this work, we address the problem of variance reduction in gradient-based meta-learning and formalize the class of problems prone to this, a condition we refer to as \emph{task overlap}. Specifically, we propose a novel approach that reduces the variance of the gradient estimate by weighing each support point individually by the variance of its posterior over the parameters. To estimate the posterior, we utilize the Laplace approximation, which allows us to express the variance in terms of the curvature of the loss landscape of our meta-learner. Experimental results demonstrate the effectiveness of the proposed method and highlight the importance of variance reduction in meta-learning.
Goal-Conditioned Offline Reinforcement Learning via Metric Learning
Feb 16, 2024



In this work, we address the problem of learning optimal behavior from sub-optimal datasets in the context of goal-conditioned offline reinforcement learning. To do so, we propose a novel way of approximating the optimal value function for goal-conditioned offline RL problems under sparse rewards, symmetric and deterministic actions. We study a property for representations to recover optimality and propose a new optimization objective that leads to such property. We use the learned value function to guide the learning of a policy in an actor-critic fashion, a method we name MetricRL. Experimentally, we show how our method consistently outperforms other offline RL baselines in learning from sub-optimal offline datasets. Moreover, we show the effectiveness of our method in dealing with high-dimensional observations and in multi-goal tasks.
Learning Geometric Representations of Objects via Interaction
Sep 11, 2023



We address the problem of learning representations from observations of a scene involving an agent and an external object the agent interacts with. To this end, we propose a representation learning framework extracting the location in physical space of both the agent and the object from unstructured observations of arbitrary nature. Our framework relies on the actions performed by the agent as the only source of supervision, while assuming that the object is displaced by the agent via unknown dynamics. We provide a theoretical foundation and formally prove that an ideal learner is guaranteed to infer an isometric representation, disentangling the agent from the object and correctly extracting their locations. We evaluate empirically our framework on a variety of scenarios, showing that it outperforms vision-based approaches such as a state-of-the-art keypoint extractor. We moreover demonstrate how the extracted representations enable the agent to solve downstream tasks via reinforcement learning in an efficient manner.
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
Sep 19, 2022
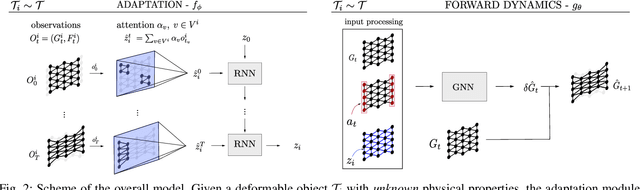
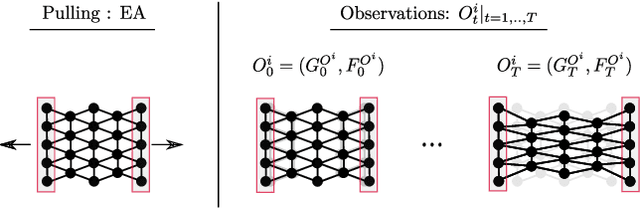
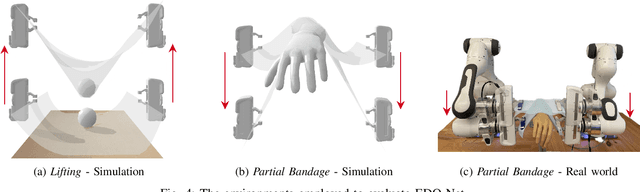
We study the problem of learning graph dynamics of deformable objects which generalize to unknown physical properties. In particular, we leverage a latent representation of elastic physical properties of cloth-like deformable objects which we explore through a pulling interaction. We propose EDO-Net (Elastic Deformable Object - Net), a model trained in a self-supervised fashion on a large variety of samples with different elastic properties. EDO-Net jointly learns an adaptation module, responsible for extracting a latent representation of the physical properties of the object, and a forward-dynamics module, which leverages the latent representation to predict future states of cloth-like objects, represented as graphs. We evaluate EDO-Net both in simulation and real world, assessing its capabilities of: 1) generalizing to unknown physical properties of cloth-like deformable objects, 2) transferring the learned representation to new downstream tasks.
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Sep 19, 2022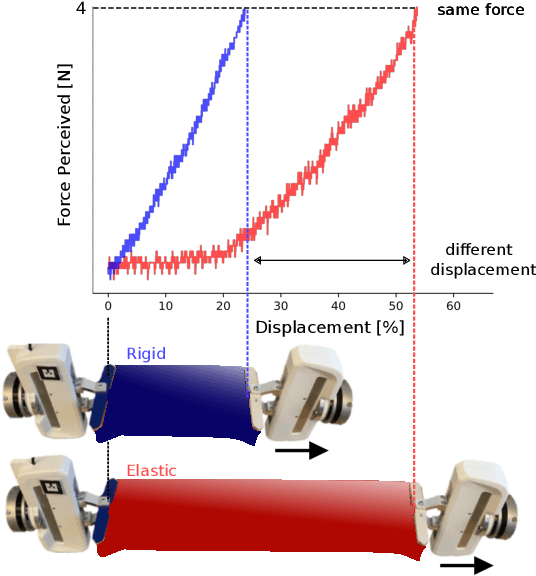
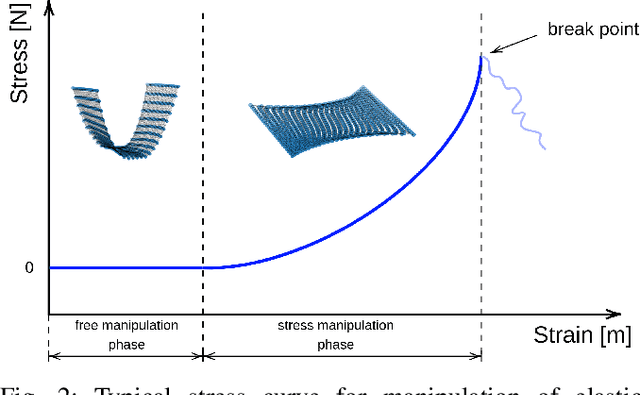
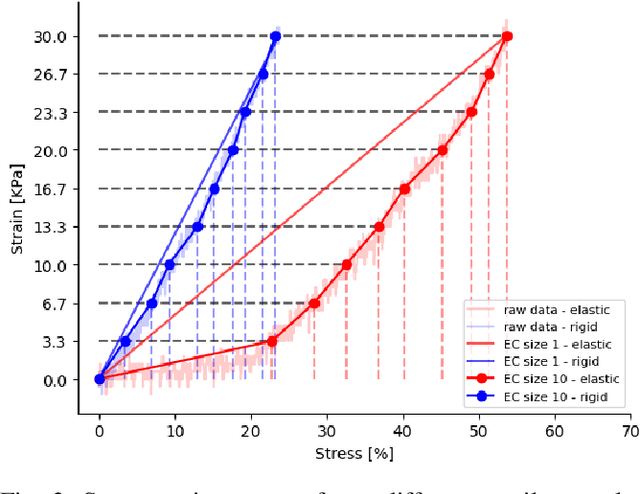
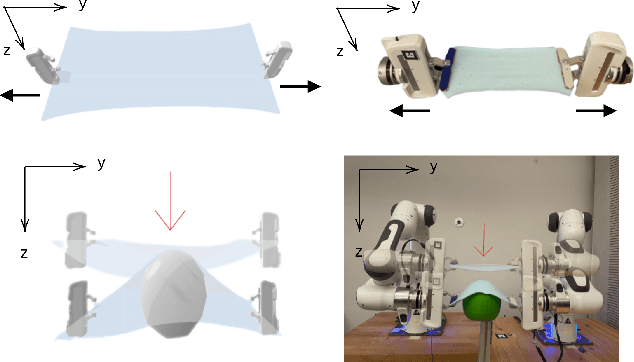
Physical interaction with textiles, such as assistive dressing, relies on advanced dextreous capabilities. The underlying complexity in textile behavior when being pulled and stretched, is due to both the yarn material properties and the textile construction technique. Today, there are no commonly adopted and annotated datasets on which the various interaction or property identification methods are assessed. One important property that affects the interaction is material elasticity that results from both the yarn material and construction technique: these two are intertwined and, if not known a-priori, almost impossible to identify through sensing commonly available on robotic platforms. We introduce Elastic Context (EC), a concept that integrates various properties that affect elastic behavior, to enable a more effective physical interaction with textiles. The definition of EC relies on stress/strain curves commonly used in textile engineering, which we reformulated for robotic applications. We employ EC using Graph Neural Network (GNN) to learn generalized elastic behaviors of textiles. Furthermore, we explore the effect the dimension of the EC has on accurate force modeling of non-linear real-world elastic behaviors, highlighting the challenges of current robotic setups to sense textile properties.
Back to the Manifold: Recovering from Out-of-Distribution States
Jul 18, 2022
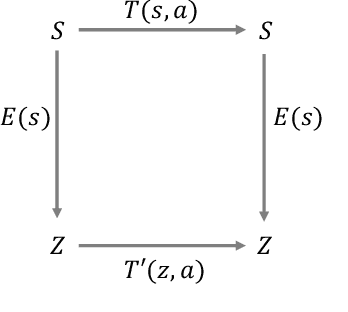
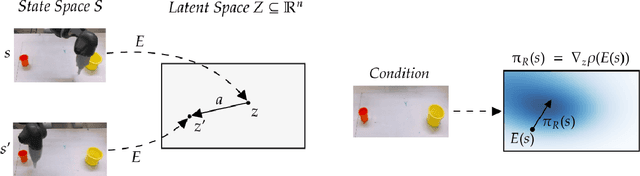

Learning from previously collected datasets of expert data offers the promise of acquiring robotic policies without unsafe and costly online explorations. However, a major challenge is a distributional shift between the states in the training dataset and the ones visited by the learned policy at the test time. While prior works mainly studied the distribution shift caused by the policy during the offline training, the problem of recovering from out-of-distribution states at the deployment time is not very well studied yet. We alleviate the distributional shift at the deployment time by introducing a recovery policy that brings the agent back to the training manifold whenever it steps out of the in-distribution states, e.g., due to an external perturbation. The recovery policy relies on an approximation of the training data density and a learned equivariant mapping that maps visual observations into a latent space in which translations correspond to the robot actions. We demonstrate the effectiveness of the proposed method through several manipulation experiments on a real robotic platform. Our results show that the recovery policy enables the agent to complete tasks while the behavioral cloning alone fails because of the distributional shift problem.
On the Subspace Structure of Gradient-Based Meta-Learning
Jul 08, 2022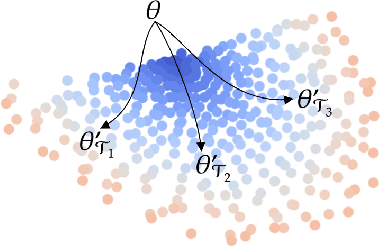
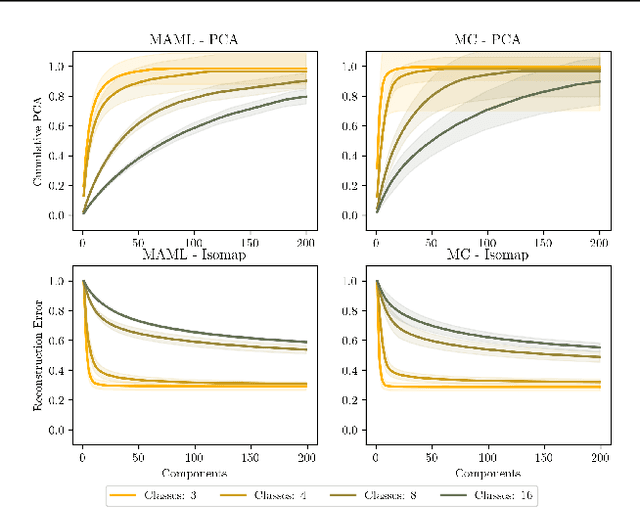
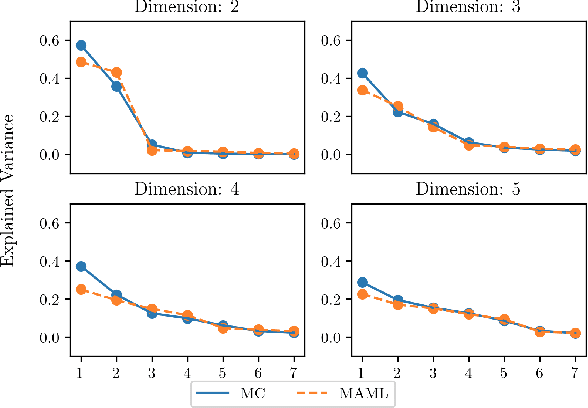
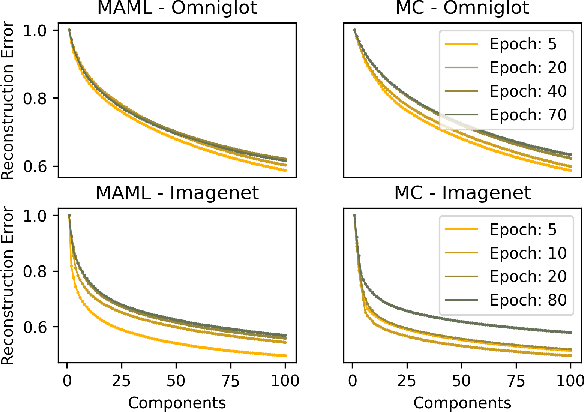
In this work we provide an analysis of the distribution of the post-adaptation parameters of Gradient-Based Meta-Learning (GBML) methods. Previous work has noticed how, for the case of image-classification, this adaption only takes place on the last layers of the network. We propose the more general notion that parameters are updated over a low-dimensional \emph{subspace} of the same dimensionality as the task-space and show that this holds for regression as well. Furthermore, the induced subspace structure provides a method to estimate the intrinsic dimension of the space of tasks of common few-shot learning datasets.