 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Variance in Meta-Learning via Laplace Approximation for Regression Tasks
Oct 02, 2024



Given a finite set of sample points, meta-learning algorithms aim to learn an optimal adaptation strategy for new, unseen tasks. Often, this data can be ambiguous as it might belong to different tasks concurrently. This is particularly the case in meta-regression tasks. In such cases, the estimated adaptation strategy is subject to high variance due to the limited amount of support data for each task, which often leads to sub-optimal generalization performance. In this work, we address the problem of variance reduction in gradient-based meta-learning and formalize the class of problems prone to this, a condition we refer to as \emph{task overlap}. Specifically, we propose a novel approach that reduces the variance of the gradient estimate by weighing each support point individually by the variance of its posterior over the parameters. To estimate the posterior, we utilize the Laplace approximation, which allows us to express the variance in terms of the curvature of the loss landscape of our meta-learner. Experimental results demonstrate the effectiveness of the proposed method and highlight the importance of variance reduction in meta-learning.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 11, 2022
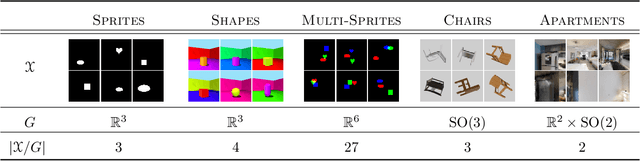
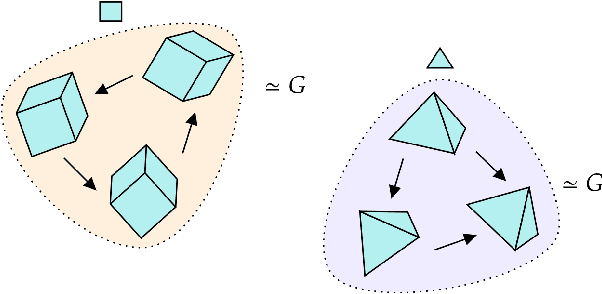
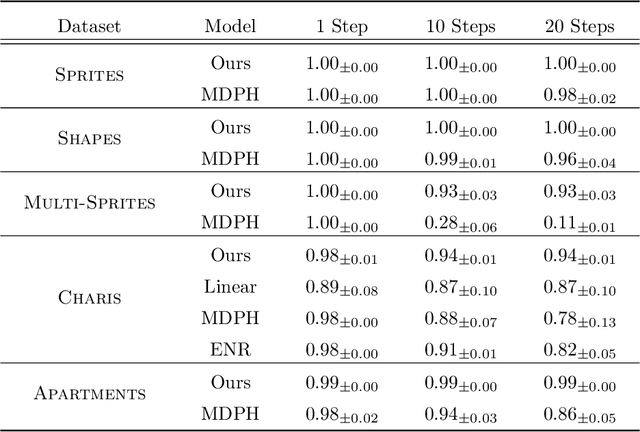
We introduce a general method for learning representations that are equivariant to symmetries of data. Our central idea is to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We provide an empirical investigation via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
On the Subspace Structure of Gradient-Based Meta-Learning
Jul 08, 2022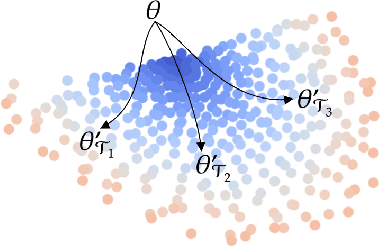
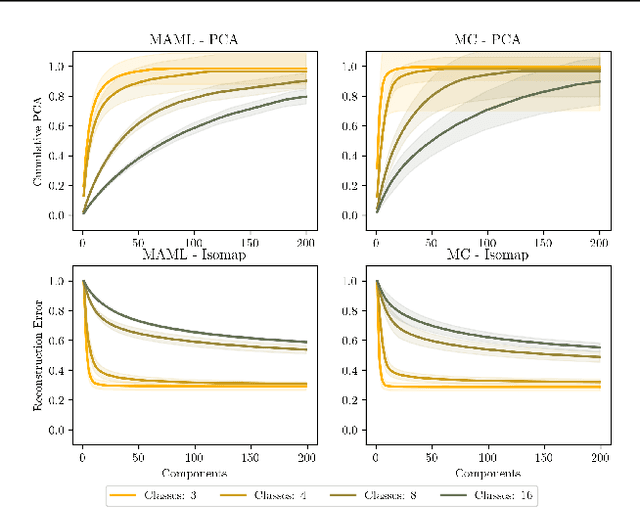
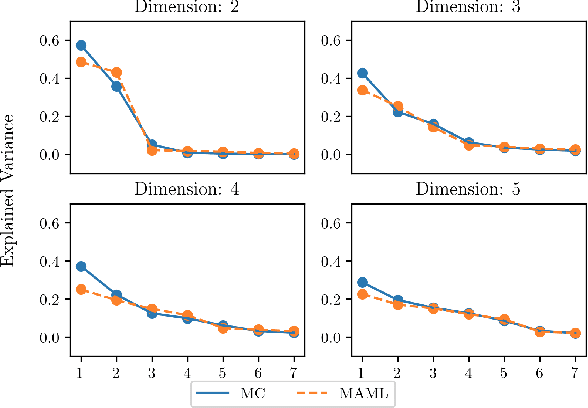
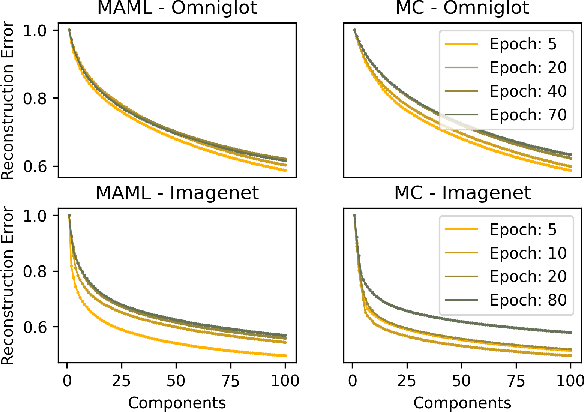
In this work we provide an analysis of the distribution of the post-adaptation parameters of Gradient-Based Meta-Learning (GBML) methods. Previous work has noticed how, for the case of image-classification, this adaption only takes place on the last layers of the network. We propose the more general notion that parameters are updated over a low-dimensional \emph{subspace} of the same dimensionality as the task-space and show that this holds for regression as well. Furthermore, the induced subspace structure provides a method to estimate the intrinsic dimension of the space of tasks of common few-shot learning datasets.