Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Subspace Structure of Gradient-Based Meta-Learning
Paper and Code
Jul 08, 2022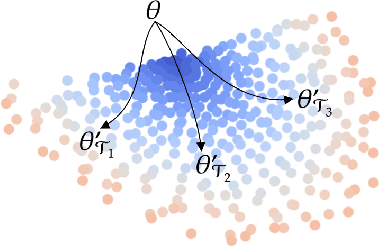
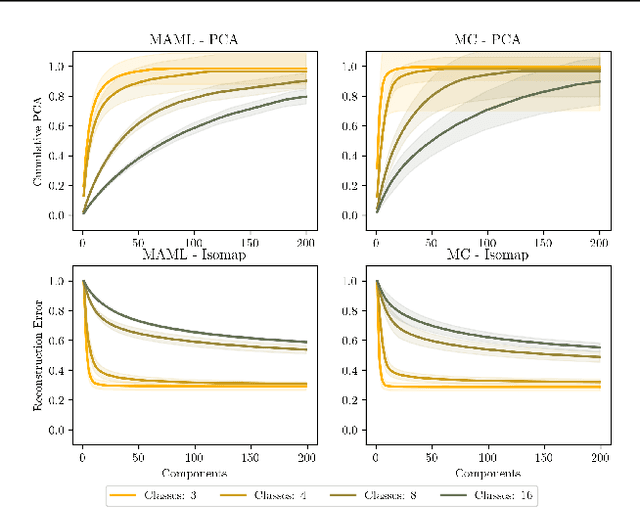
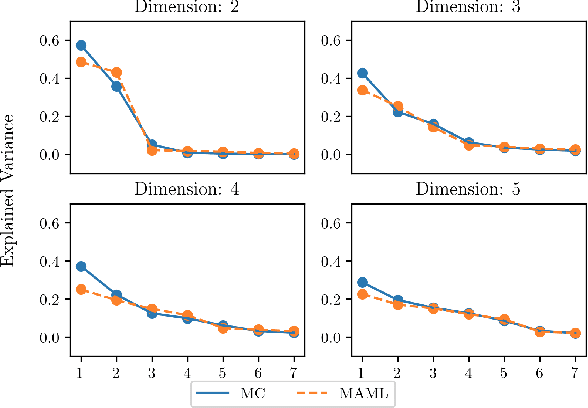
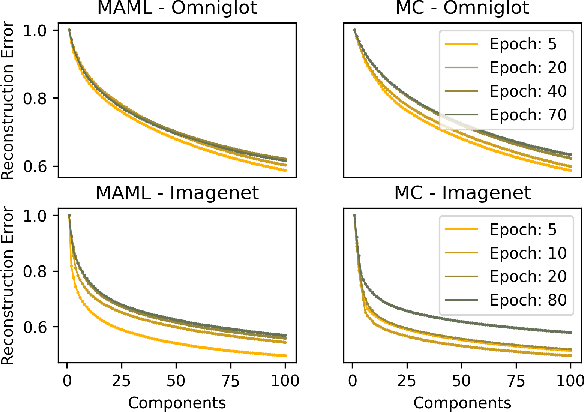
In this work we provide an analysis of the distribution of the post-adaptation parameters of Gradient-Based Meta-Learning (GBML) methods. Previous work has noticed how, for the case of image-classification, this adaption only takes place on the last layers of the network. We propose the more general notion that parameters are updated over a low-dimensional \emph{subspace} of the same dimensionality as the task-space and show that this holds for regression as well. Furthermore, the induced subspace structure provides a method to estimate the intrinsic dimension of the space of tasks of common few-shot learning datasets.
View paper on
 OpenReview
OpenReview