 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Curiosity: Learning Efficient Data Collection Strategies for Domain Adaptation
Paper and Code
Mar 12, 2021
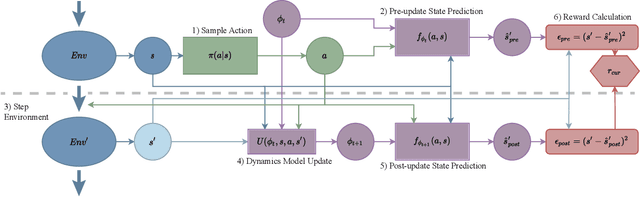
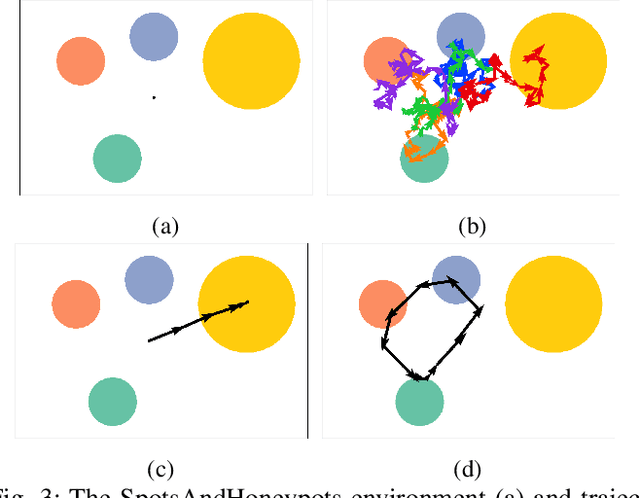
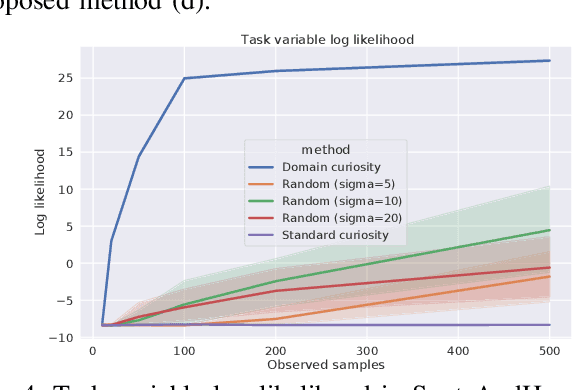
Domain adaptation is a common problem in robotics, with applications such as transferring policies from simulation to real world and lifelong learning. Performing such adaptation, however, requires informative data about the environment to be available during the adaptation. In this paper, we present domain curiosity -- a method of training exploratory policies that are explicitly optimized to provide data that allows a model to learn about the unknown aspects of the environment. In contrast to most curiosity methods, our approach explicitly rewards learning, which makes it robust to environment noise without sacrificing its ability to learn. We evaluate the proposed method by comparing how much a model can learn about environment dynamics given data collected by the proposed approach, compared to standard curious and random policies. The evaluation is performed using a toy environment, two simulated robot setups, and on a real-world haptic exploration task. The results show that the proposed method allows data-efficient and accurate estimation of dynamics.