 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROPO: Sim-to-Real Transfer with Offline Domain Randomization
Paper and Code
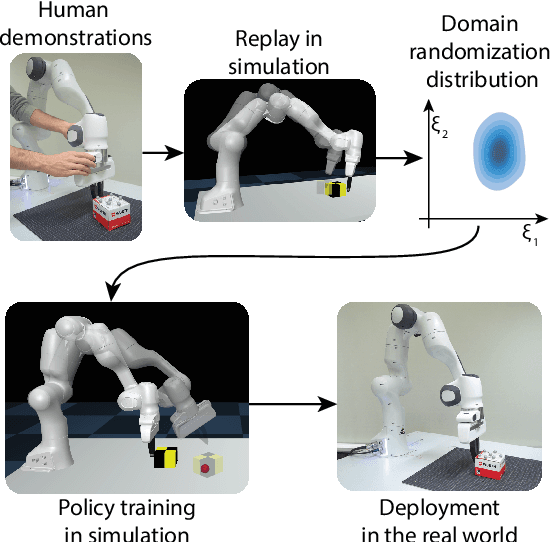
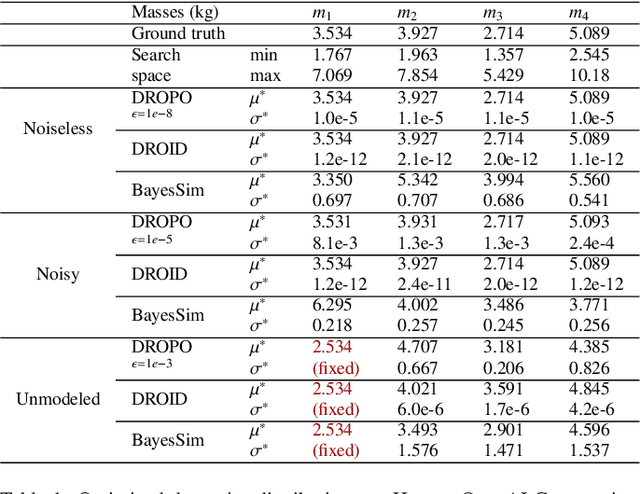
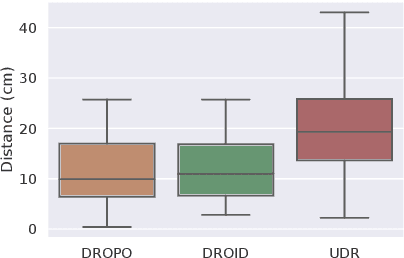

In recent years, domain randomization has gained a lot of traction as a method for sim-to-real transfer of reinforcement learning policies in robotic manipulation; however, finding optimal randomization distributions can be difficult. In this paper, we introduce DROPO, a novel method for estimating domain randomization distributions for safe sim-to-real transfer. Unlike prior work, DROPO only requires a limited, precollected offline dataset of trajectories, and explicitly models parameter uncertainty to match real data. We demonstrate that DROPO is capable of recovering dynamic parameter distributions in simulation and finding a distribution capable of compensating for an unmodelled phenomenon. We also evaluate the method in two zero-shot sim-to-real transfer scenarios, showing successful domain transfer and improved performance over prior methods.