 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Contrastive Learning for Diffusion Policies in Autonomous Driving
Mar 07, 2025Learning to perform accurate and rich simulations of human driving behaviors from data for autonomous vehicle testing remains challenging due to human driving styles' high diversity and variance. We address this challenge by proposing a novel approach that leverages contrastive learning to extract a dictionary of driving styles from pre-existing human driving data. We discretize these styles with quantization, and the styles are used to learn a conditional diffusion policy for simulating human drivers. Our empirical evaluation confirms that the behaviors generated by our approach are both safer and more human-like than those of the machine-learning-based baseline methods. We believe this has the potential to enable higher realism and more effective techniques for evaluating and improving the performance of autonomous vehicles.
Survey on Vision-Language-Action Models
Feb 07, 2025This paper presents an AI-generated review of Vision-Language-Action (VLA) models, summarizing key methodologies, findings, and future directions. The content is produced using large language models (LLMs) and is intended only for demonstration purposes. This work does not represent original research, but highlights how AI can help automate literature reviews. As AI-generated content becomes more prevalent, ensuring accuracy, reliability, and proper synthesis remains a challenge. Future research will focus on developing a structured framework for AI-assisted literature reviews, exploring techniques to enhance citation accuracy, source credibility, and contextual understanding. By examining the potential and limitations of LLM in academic writing, this study aims to contribute to the broader discussion of integrating AI into research workflows. This work serves as a preliminary step toward establishing systematic approaches for leveraging AI in literature review generation, making academic knowledge synthesis more efficient and scalable.
Learning Transparent Reward Models via Unsupervised Feature Selection
Oct 24, 2024In complex real-world tasks such as robotic manipulation and autonomous driving, collecting expert demonstrations is often more straightforward than specifying precise learning objectives and task descriptions. Learning from expert data can be achieved through behavioral cloning or by learning a reward function, i.e., inverse reinforcement learning. The latter allows for training with additional data outside the training distribution, guided by the inferred reward function. We propose a novel approach to construct compact and transparent reward models from automatically selected state features. These inferred rewards have an explicit form and enable the learning of policies that closely match expert behavior by training standard reinforcement learning algorithms from scratch. We validate our method's performance in various robotic environments with continuous and high-dimensional state spaces. Webpage: \url{https://sites.google.com/view/transparent-reward}.
Automated Feature Selection for Inverse Reinforcement Learning
Mar 22, 2024Inverse reinforcement learning (IRL) is an imitation learning approach to learning reward functions from expert demonstrations. Its use avoids the difficult and tedious procedure of manual reward specification while retaining the generalization power of reinforcement learning. In IRL, the reward is usually represented as a linear combination of features. In continuous state spaces, the state variables alone are not sufficiently rich to be used as features, but which features are good is not known in general. To address this issue, we propose a method that employs polynomial basis functions to form a candidate set of features, which are shown to allow the matching of statistical moments of state distributions. Feature selection is then performed for the candidates by leveraging the correlation between trajectory probabilities and feature expectations. We demonstrate the approach's effectiveness by recovering reward functions that capture expert policies across non-linear control tasks of increasing complexity. Code, data, and videos are available at https://sites.google.com/view/feature4irl.
Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors
Jan 06, 2024Building simulation environments for developing and testing autonomous vehicles necessitates that the simulators accurately model the statistical realism of the real-world environment, including the interaction with other vehicles driven by human drivers. To address this requirement, an accurate human behavior model is essential to incorporate the diversity and consistency of human driving behavior. We propose a mathematical framework for designing a data-driven simulation model that simulates human driving behavior more realistically than the currently used physics-based simulation models. Experiments conducted using the NGSIM dataset validate our hypothesis regarding the necessity of considering the complexity, diversity, and consistency of human driving behavior when aiming to develop realistic simulators.
End-to-End Deep Fault Tolerant Control
May 28, 2021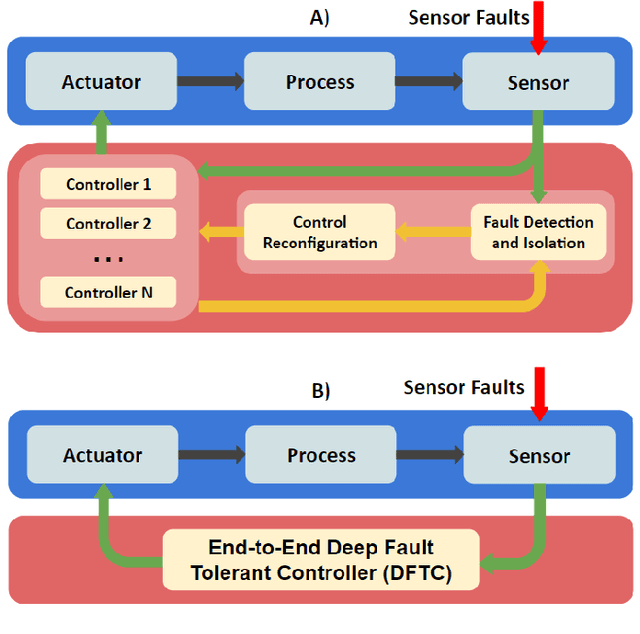
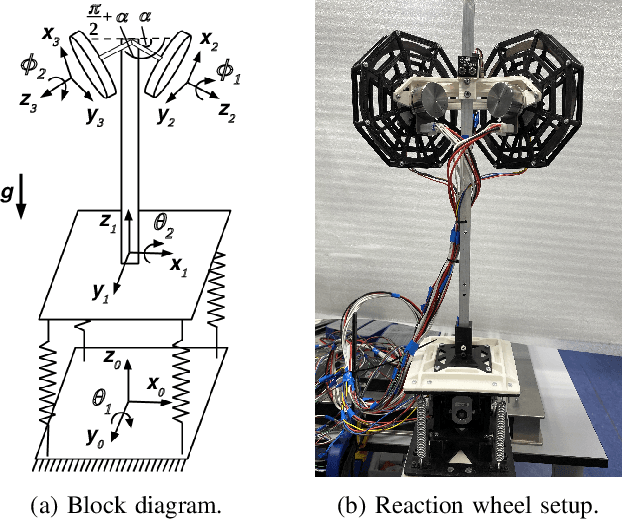
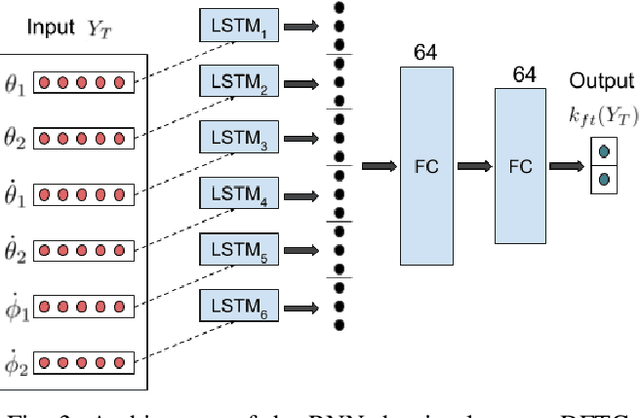
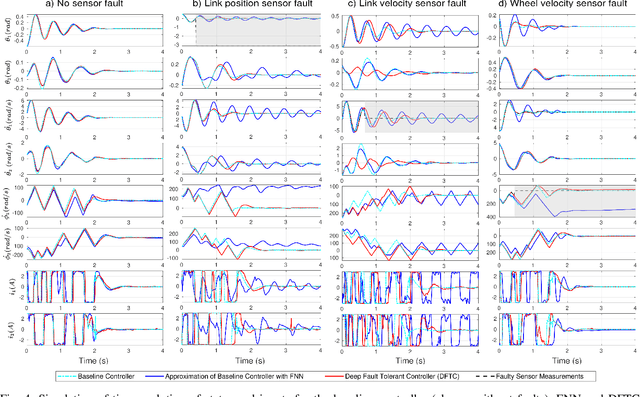
Ideally, accurate sensor measurements are needed to achieve a good performance in the closed-loop control of mechatronic systems. As a consequence, sensor faults will prevent the system from working correctly, unless a fault-tolerant control (FTC) architecture is adopted. As model-based FTC algorithms for nonlinear systems are often challenging to design, this paper focuses on a new method for FTC in the presence of sensor faults, based on deep learning. The considered approach replaces the phases of fault detection and isolation and controller design with a single recurrent neural network, which has the value of past sensor measurements in a given time window as input, and the current values of the control variables as output. This end-to-end deep FTC method is applied to a mechatronic system composed of a spherical inverted pendulum, whose configuration is changed via reaction wheels, in turn actuated by electric motors. The simulation and experimental results show that the proposed method can handle abrupt faults occurring in link position/velocity sensors. The provided supplementary material includes a video of real-world experiments and the software source code.
Color-Coded Fiber-Optic Tactile Sensor for an Elastomeric Robot Skin
Aug 10, 2019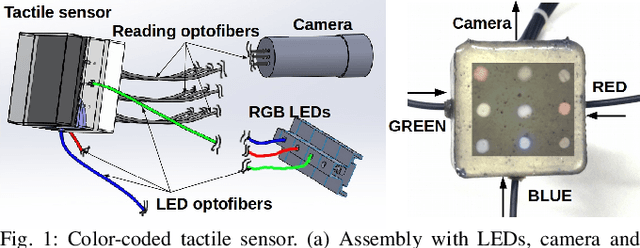
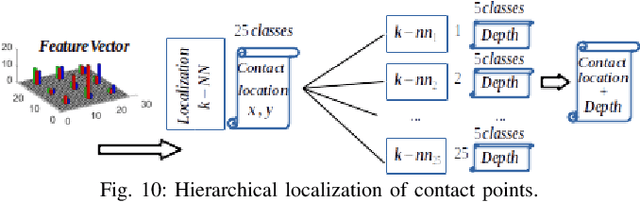
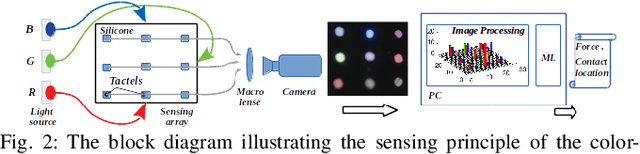
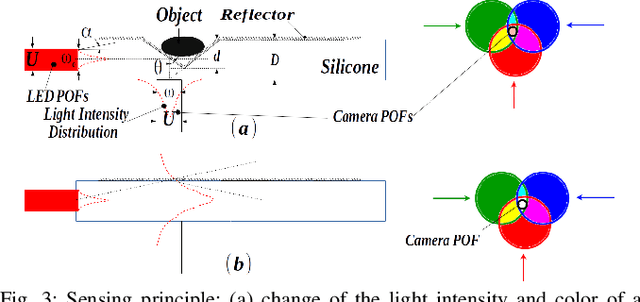
The sense of touch is essential for reliable mapping between the environment and a robot which interacts physically with objects. Presumably, an artificial tactile skin would facilitate safe interaction of the robots with the environment. In this work, we present our color-coded tactile sensor, incorporating plastic optical fibers (POF), transparent silicone rubber and an off-the-shelf color camera. Processing electronics are placed away from the sensing surface to make the sensor robust to harsh environments. Contact localization is possible thanks to the lower number of light sources compared to the number of camera POFs. Classical machine learning techniques and a hierarchical classification scheme were used for contact localization. Specifically, we generated the mapping from stimulation to sensation of a robotic perception system using our sensor. We achieved a force sensing range up to 18 N with the force resolution of around 3.6~N and the spatial resolution of 8~mm. The color-coded tactile sensor is suitable for tactile exploration and might enable further innovations in robust tactile sensing.