 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Contrastive Learning for Diffusion Policies in Autonomous Driving
Mar 07, 2025Learning to perform accurate and rich simulations of human driving behaviors from data for autonomous vehicle testing remains challenging due to human driving styles' high diversity and variance. We address this challenge by proposing a novel approach that leverages contrastive learning to extract a dictionary of driving styles from pre-existing human driving data. We discretize these styles with quantization, and the styles are used to learn a conditional diffusion policy for simulating human drivers. Our empirical evaluation confirms that the behaviors generated by our approach are both safer and more human-like than those of the machine-learning-based baseline methods. We believe this has the potential to enable higher realism and more effective techniques for evaluating and improving the performance of autonomous vehicles.
Data-driven Diffusion Models for Enhancing Safety in Autonomous Vehicle Traffic Simulations
Oct 07, 2024Safety-critical traffic scenarios are integral to the development and validation of autonomous driving systems. These scenarios provide crucial insights into vehicle responses under high-risk conditions rarely encountered in real-world settings. Recent advancements in critical scenario generation have demonstrated the superiority of diffusion-based approaches over traditional generative models in terms of effectiveness and realism. However, current diffusion-based methods fail to adequately address the complexity of driver behavior and traffic density information, both of which significantly influence driver decision-making processes. In this work, we present a novel approach to overcome these limitations by introducing adversarial guidance functions for diffusion models that incorporate behavior complexity and traffic density, thereby enhancing the generation of more effective and realistic safety-critical traffic scenarios. The proposed method is evaluated on two evaluation metrics: effectiveness and realism.The proposed method is evaluated on two evaluation metrics: effectiveness and realism, demonstrating better efficacy as compared to other state-of-the-art methods.
Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors
Jan 06, 2024Building simulation environments for developing and testing autonomous vehicles necessitates that the simulators accurately model the statistical realism of the real-world environment, including the interaction with other vehicles driven by human drivers. To address this requirement, an accurate human behavior model is essential to incorporate the diversity and consistency of human driving behavior. We propose a mathematical framework for designing a data-driven simulation model that simulates human driving behavior more realistically than the currently used physics-based simulation models. Experiments conducted using the NGSIM dataset validate our hypothesis regarding the necessity of considering the complexity, diversity, and consistency of human driving behavior when aiming to develop realistic simulators.
Radar-Lidar Fusion for Object Detection by Designing Effective Convolution Networks
Oct 30, 2023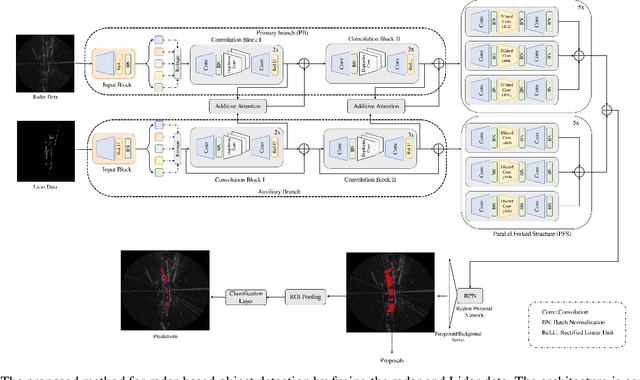
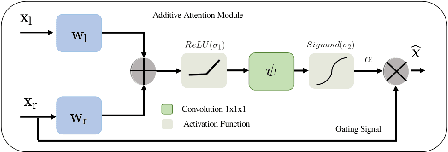

Object detection is a core component of perception systems, providing the ego vehicle with information about its surroundings to ensure safe route planning. While cameras and Lidar have significantly advanced perception systems, their performance can be limited in adverse weather conditions. In contrast, millimeter-wave technology enables radars to function effectively in such conditions. However, relying solely on radar for building a perception system doesn't fully capture the environment due to the data's sparse nature. To address this, sensor fusion strategies have been introduced. We propose a dual-branch framework to integrate radar and Lidar data for enhanced object detection. The primary branch focuses on extracting radar features, while the auxiliary branch extracts Lidar features. These are then combined using additive attention. Subsequently, the integrated features are processed through a novel Parallel Forked Structure (PFS) to manage scale variations. A region proposal head is then utilized for object detection. We evaluated the effectiveness of our proposed method on the Radiate dataset using COCO metrics. The results show that it surpasses state-of-the-art methods by $1.89\%$ and $2.61\%$ in favorable and adverse weather conditions, respectively. This underscores the value of radar-Lidar fusion in achieving precise object detection and localization, especially in challenging weather conditions.
Learning Driving Policies for End-to-End Autonomous Driving
Oct 13, 2022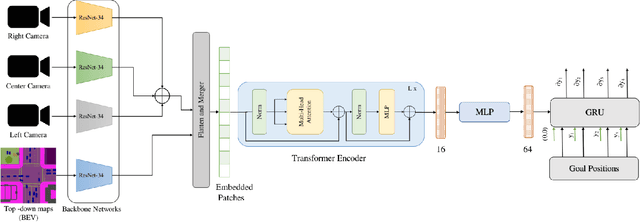

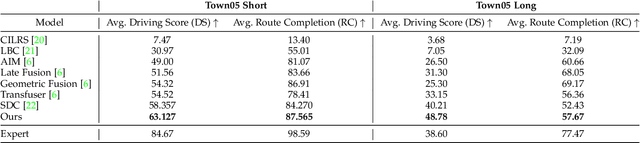
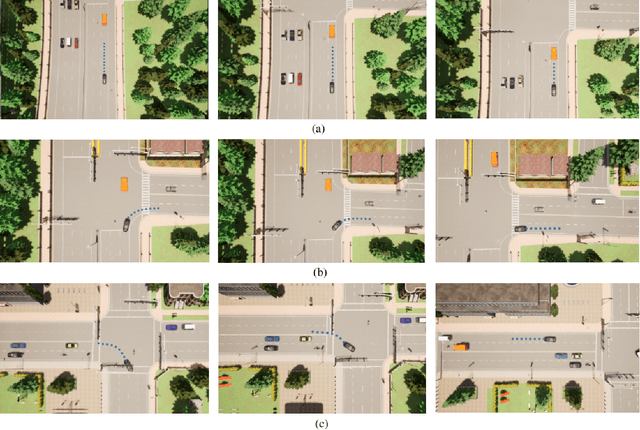
Humans tend to drive vehicles efficiently by relying on contextual and spatial information through the sensory organs. Inspired by this, most of the research is focused on how to learn robust and efficient driving policies. These works are mostly categorized as making modular or end-to-end systems for learning driving policies. However, the former approach has limitations due to the manual supervision of specific modules that hinder the scalability of these systems. In this work, we focus on the latter approach to formalize a framework for learning driving policies for end-to-end autonomous driving. In order to take inspiration from human driving, we have proposed a framework that incorporates three RGB cameras (left, right, and center) to mimic the human field of view and top-down semantic information for contextual representation in predicting the driving policies for autonomous driving. The sensor information is fused and encoded by the self-attention mechanism and followed by the auto-regressive waypoint prediction module. The proposed method's efficacy is experimentally evaluated using the CARLA simulator and outperforms the state-of-the-art methods by achieving the highest driving score at the evaluation time.
Multi-Modal Fusion for Sensorimotor Coordination in Steering Angle Prediction
Feb 11, 2022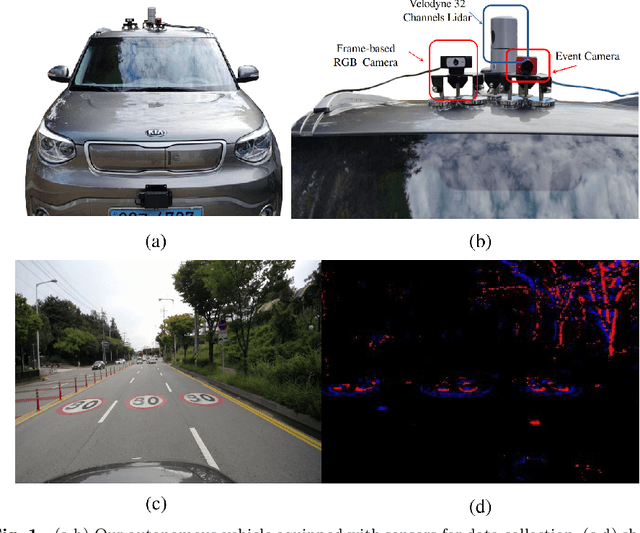
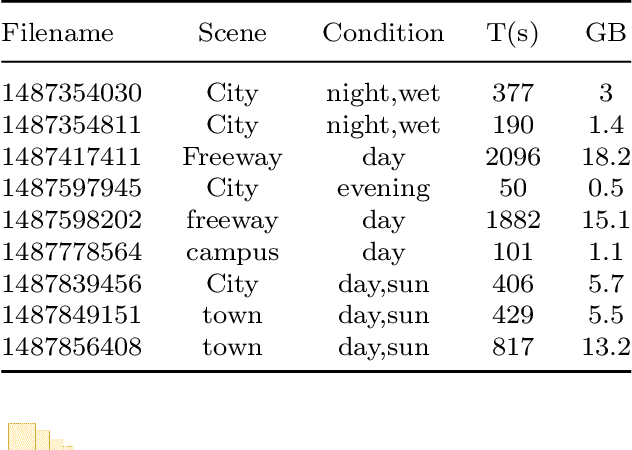
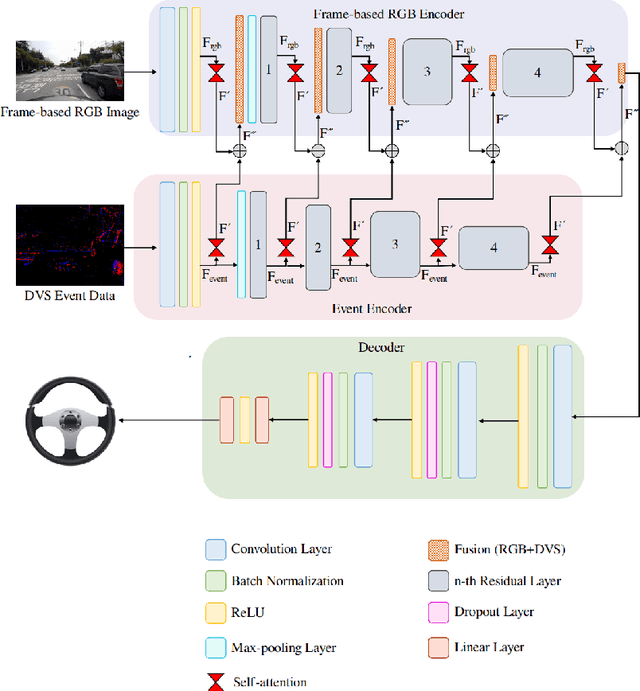
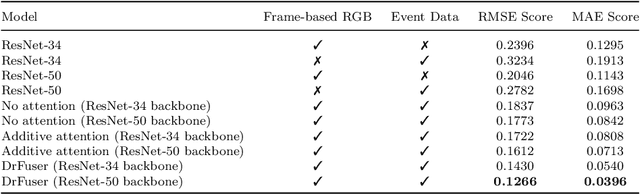
Imitation learning is employed to learn sensorimotor coordination for steering angle prediction in an end-to-end fashion requires expert demonstrations. These expert demonstrations are paired with environmental perception and vehicle control data. The conventional frame-based RGB camera is the most common exteroceptive sensor modality used to acquire the environmental perception data. The frame-based RGB camera has produced promising results when used as a single modality in learning end-to-end lateral control. However, the conventional frame-based RGB camera has limited operability in illumination variation conditions and is affected by the motion blur. The event camera provides complementary information to the frame-based RGB camera. This work explores the fusion of frame-based RGB and event data for learning end-to-end lateral control by predicting steering angle. In addition, how the representation from event data fuse with frame-based RGB data helps to predict the lateral control robustly for the autonomous vehicle. To this end, we propose DRFuser, a novel convolutional encoder-decoder architecture for learning end-to-end lateral control. The encoder module is branched between the frame-based RGB data and event data along with the self-attention layers. Moreover, this study has also contributed to our own collected dataset comprised of event, frame-based RGB, and vehicle control data. The efficacy of the proposed method is experimentally evaluated on our collected dataset, Davis Driving dataset (DDD), and Carla Eventscape dataset. The experimental results illustrate that the proposed method DRFuser outperforms the state-of-the-art in terms of root-mean-square error (RMSE) and mean absolute error (MAE) used as evaluation metrics.
ARTSeg: Employing Attention for Thermal images Semantic Segmentation
Nov 30, 2021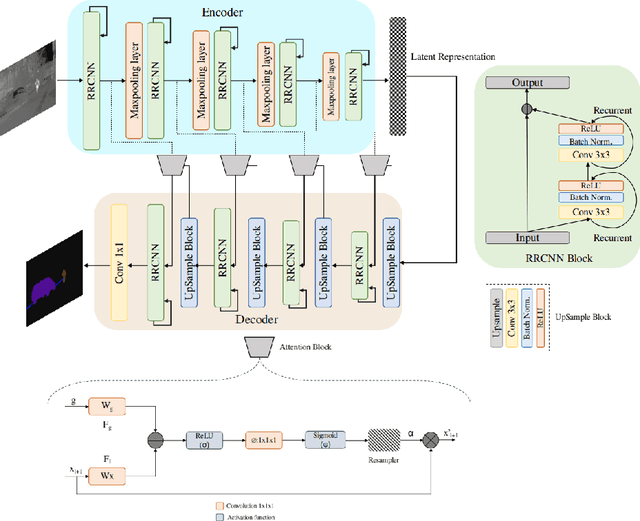
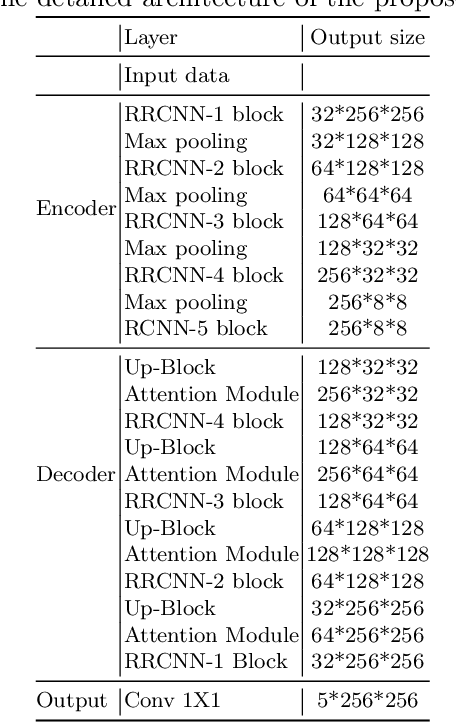
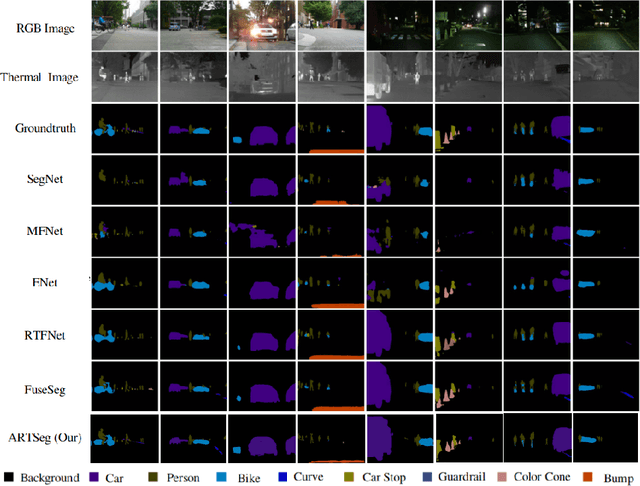
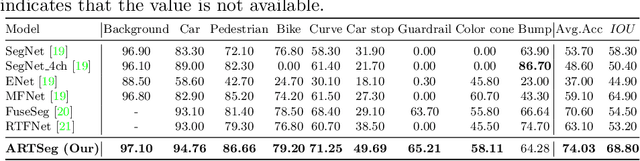
The research advancements have made the neural network algorithms deployed in the autonomous vehicle to perceive the surrounding. The standard exteroceptive sensors that are utilized for the perception of the environment are cameras and Lidar. Therefore, the neural network algorithms developed using these exteroceptive sensors have provided the necessary solution for the autonomous vehicle's perception. One major drawback of these exteroceptive sensors is their operability in adverse weather conditions, for instance, low illumination and night conditions. The useability and affordability of thermal cameras in the sensor suite of the autonomous vehicle provide the necessary improvement in the autonomous vehicle's perception in adverse weather conditions. The semantics of the environment benefits the robust perception, which can be achieved by segmenting different objects in the scene. In this work, we have employed the thermal camera for semantic segmentation. We have designed an attention-based Recurrent Convolution Network (RCNN) encoder-decoder architecture named ARTSeg for thermal semantic segmentation. The main contribution of this work is the design of encoder-decoder architecture, which employ units of RCNN for each encoder and decoder block. Furthermore, additive attention is employed in the decoder module to retain high-resolution features and improve the localization of features. The efficacy of the proposed method is evaluated on the available public dataset, showing better performance with other state-of-the-art methods in mean intersection over union (IoU).
SSTN: Self-Supervised Domain Adaptation Thermal Object Detection for Autonomous Driving
Mar 04, 2021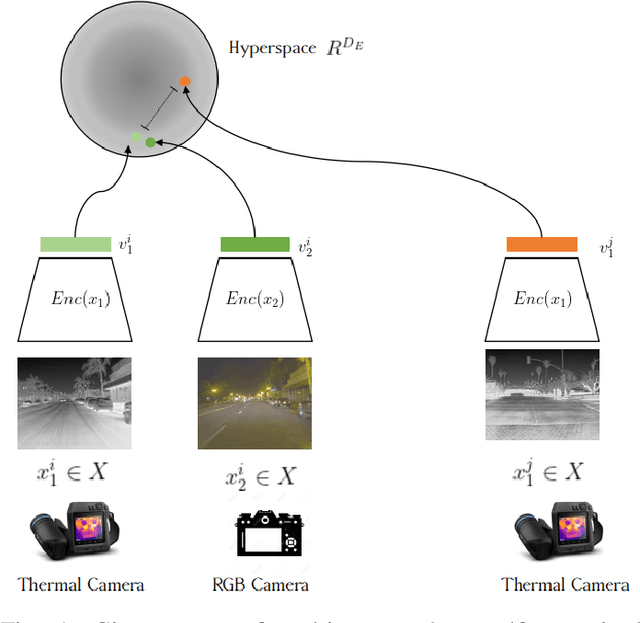
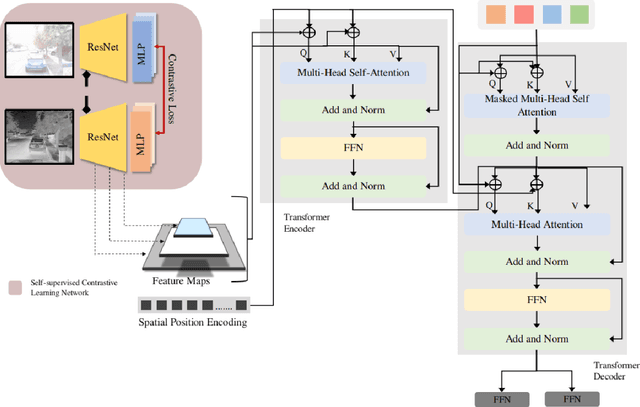
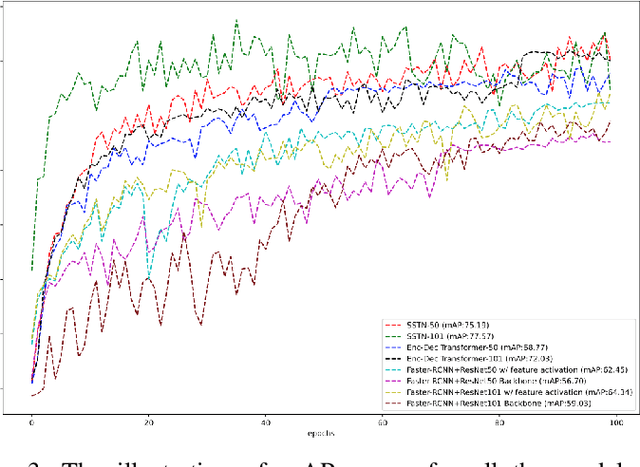
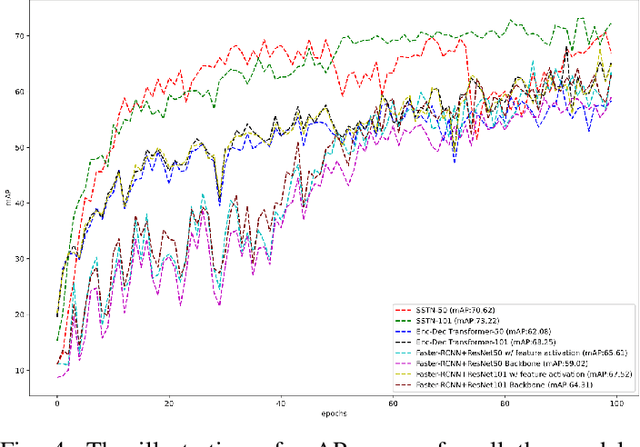
The sensibility and sensitivity of the environment play a decisive role in the safe and secure operation of autonomous vehicles. This perception of the surrounding is way similar to human visual representation. The human's brain perceives the environment by utilizing different sensory channels and develop a view-invariant representation model. Keeping in this context, different exteroceptive sensors are deployed on the autonomous vehicle for perceiving the environment. The most common exteroceptive sensors are camera, Lidar and radar for autonomous vehicle's perception. Despite being these sensors have illustrated their benefit in the visible spectrum domain yet in the adverse weather conditions, for instance, at night, they have limited operation capability, which may lead to fatal accidents. In this work, we explore thermal object detection to model a view-invariant model representation by employing the self-supervised contrastive learning approach. For this purpose, we have proposed a deep neural network Self Supervised Thermal Network (SSTN) for learning the feature embedding to maximize the information between visible and infrared spectrum domain by contrastive learning, and later employing these learned feature representation for the thermal object detection using multi-scale encoder-decoder transformer network. The proposed method is extensively evaluated on the two publicly available datasets: the FLIR-ADAS dataset and the KAIST Multi-Spectral dataset. The experimental results illustrate the efficacy of the proposed method.
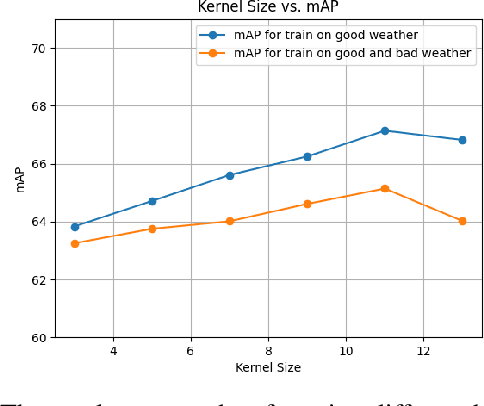
Channel Boosting Feature Ensemble for Radar-based Object Detection
Jan 10, 2021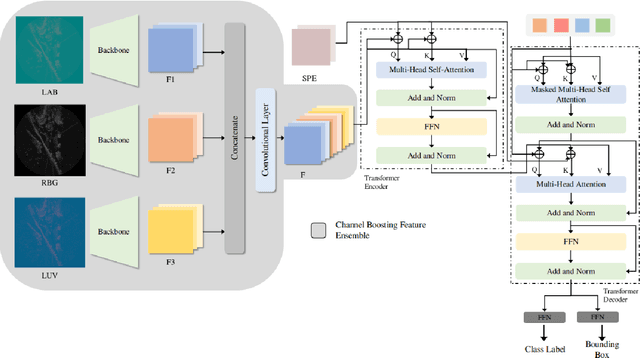
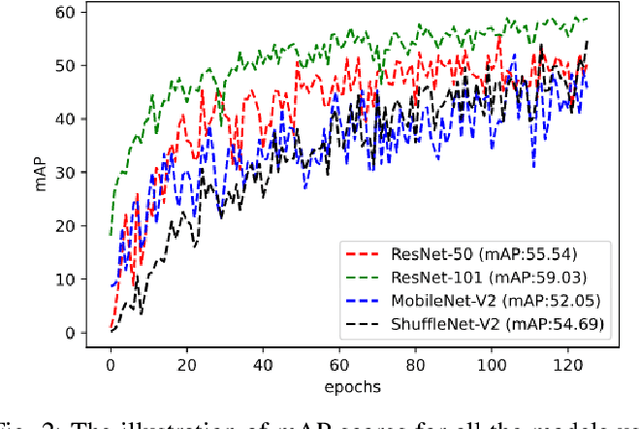
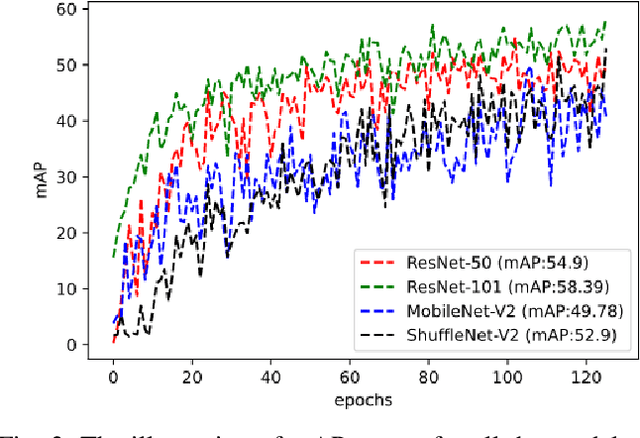
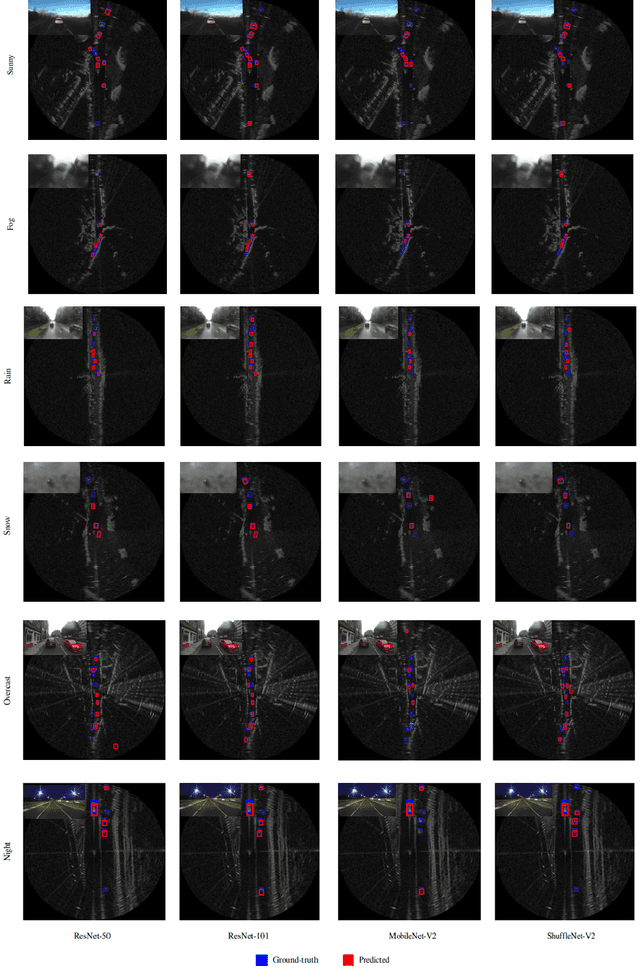
Autonomous vehicles are conceived to provide safe and secure services by validating the safety standards as indicated by SOTIF-ISO/PAS-21448 (Safety of the intended functionality). Keeping in this context, the perception of the environment plays an instrumental role in conjunction with localization, planning and control modules. As a pivotal algorithm in the perception stack, object detection provides extensive insights into the autonomous vehicle's surroundings. Camera and Lidar are extensively utilized for object detection among different sensor modalities, but these exteroceptive sensors have limitations in resolution and adverse weather conditions. In this work, radar-based object detection is explored provides a counterpart sensor modality to be deployed and used in adverse weather conditions. The radar gives complex data; for this purpose, a channel boosting feature ensemble method with transformer encoder-decoder network is proposed. The object detection task using radar is formulated as a set prediction problem and evaluated on the publicly available dataset in both good and good-bad weather conditions. The proposed method's efficacy is extensively evaluated using the COCO evaluation metric, and the best-proposed model surpasses its state-of-the-art counterpart method by $12.55\%$ and $12.48\%$ in both good and good-bad weather conditions.
LDNet: End-to-End Lane Detection Approach usinga Dynamic Vision Sensor
Sep 17, 2020
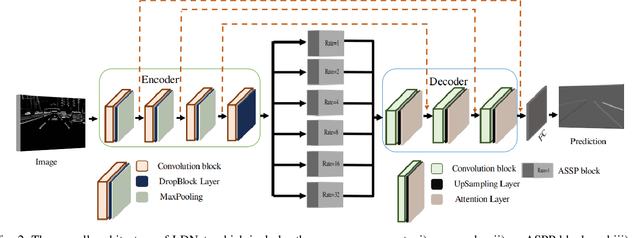
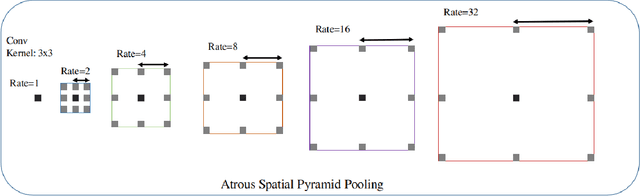
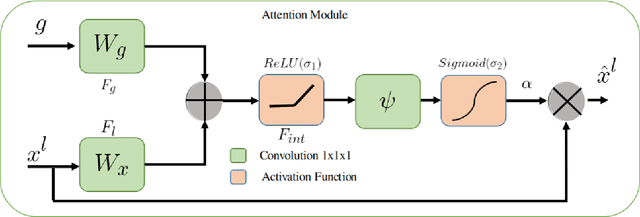
Modern vehicles are equipped with various driver-assistance systems, including automatic lane keeping, which prevents unintended lane departures. Traditional lane detection methods incorporate handcrafted or deep learning-based features followed by postprocessing techniques for lane extraction using RGB cameras. The utilization of a RGB camera for lane detection tasks is prone to illumination variations, sun glare, and motion blur, which limits the performance of the lane detection method. The incorporation of an event camera for lane detection tasks in the perception stack of autonomous driving is one of the most promising solutions for mitigating challenges encountered by RGB cameras. In this work, Lane Detection using dynamic vision sensor (LDNet), is proposed, that is designed in an encoder-decoder manner with an atrous spatial pyramid pooling block followed by an attention-guided decoder for predicting and reducing false predictions in lane detection tasks. This decoder eliminates the implicit need for a postprocessing step. The experimental results show the significant improvement of $5.54\%$ and $5.03\%$ on the $F1$ scores in the multiclass and binary class lane detection tasks, respectively. Additionally, the $IoU$ scores of the proposed method surpass those of the best-performing state-of-the-art method by $6.50\%$ and $9.37\%$ in the multiclass and binary class tasks, respectively.