 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Contrastive Learning for Diffusion Policies in Autonomous Driving
Mar 07, 2025Learning to perform accurate and rich simulations of human driving behaviors from data for autonomous vehicle testing remains challenging due to human driving styles' high diversity and variance. We address this challenge by proposing a novel approach that leverages contrastive learning to extract a dictionary of driving styles from pre-existing human driving data. We discretize these styles with quantization, and the styles are used to learn a conditional diffusion policy for simulating human drivers. Our empirical evaluation confirms that the behaviors generated by our approach are both safer and more human-like than those of the machine-learning-based baseline methods. We believe this has the potential to enable higher realism and more effective techniques for evaluating and improving the performance of autonomous vehicles.
Knowledge Injection via Prompt Distillation
Dec 19, 2024


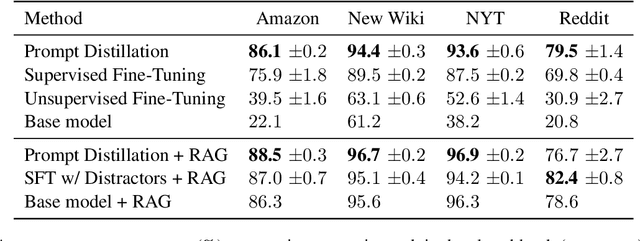
In many practical applications, large language models (LLMs) need to incorporate new knowledge not present in their pre-training data. The primary methods for this are fine-tuning and retrieval-augmented generation (RAG). Although RAG has emerged as the industry standard for knowledge injection, fine-tuning has not yet achieved comparable success. In this paper, we propose a new fine-tuning technique for learning new knowledge and show that it can reach the performance of RAG. The proposed method is based on the self-distillation approach, which we call prompt distillation. First, we generate question-answer pairs about the new knowledge. Then, we fine-tune a student model on the question-answer pairs to imitate the output distributions of a teacher model, which additionally receives the new knowledge in its prompt. The student model is identical to the teacher, except it is equipped with a LoRA adapter. This training procedure facilitates distilling the new knowledge from the teacher's prompt into the student's weights.
iQRL -- Implicitly Quantized Representations for Sample-efficient Reinforcement Learning
Jun 04, 2024



Learning representations for reinforcement learning (RL) has shown much promise for continuous control. We propose an efficient representation learning method using only a self-supervised latent-state consistency loss. Our approach employs an encoder and a dynamics model to map observations to latent states and predict future latent states, respectively. We achieve high performance and prevent representation collapse by quantizing the latent representation such that the rank of the representation is empirically preserved. Our method, named iQRL: implicitly Quantized Reinforcement Learning, is straightforward, compatible with any model-free RL algorithm, and demonstrates excellent performance by outperforming other recently proposed representation learning methods in continuous control benchmarks from DeepMind Control Suite.
Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors
Jan 06, 2024Building simulation environments for developing and testing autonomous vehicles necessitates that the simulators accurately model the statistical realism of the real-world environment, including the interaction with other vehicles driven by human drivers. To address this requirement, an accurate human behavior model is essential to incorporate the diversity and consistency of human driving behavior. We propose a mathematical framework for designing a data-driven simulation model that simulates human driving behavior more realistically than the currently used physics-based simulation models. Experiments conducted using the NGSIM dataset validate our hypothesis regarding the necessity of considering the complexity, diversity, and consistency of human driving behavior when aiming to develop realistic simulators.
Hybrid Search for Efficient Planning with Completeness Guarantees
Oct 19, 2023



Solving complex planning problems has been a long-standing challenge in computer science. Learning-based subgoal search methods have shown promise in tackling these problems, but they often suffer from a lack of completeness guarantees, meaning that they may fail to find a solution even if one exists. In this paper, we propose an efficient approach to augment a subgoal search method to achieve completeness in discrete action spaces. Specifically, we augment the high-level search with low-level actions to execute a multi-level (hybrid) search, which we call complete subgoal search. This solution achieves the best of both worlds: the practical efficiency of high-level search and the completeness of low-level search. We apply the proposed search method to a recently proposed subgoal search algorithm and evaluate the algorithm trained on offline data on complex planning problems. We demonstrate that our complete subgoal search not only guarantees completeness but can even improve performance in terms of search expansions for instances that the high-level could solve without low-level augmentations. Our approach makes it possible to apply subgoal-level planning for systems where completeness is a critical requirement.
Hierarchical Imitation Learning with Vector Quantized Models
Jan 30, 2023



The ability to plan actions on multiple levels of abstraction enables intelligent agents to solve complex tasks effectively. However, learning the models for both low and high-level planning from demonstrations has proven challenging, especially with higher-dimensional inputs. To address this issue, we propose to use reinforcement learning to identify subgoals in expert trajectories by associating the magnitude of the rewards with the predictability of low-level actions given the state and the chosen subgoal. We build a vector-quantized generative model for the identified subgoals to perform subgoal-level planning. In experiments, the algorithm excels at solving complex, long-horizon decision-making problems outperforming state-of-the-art. Because of its ability to plan, our algorithm can find better trajectories than the ones in the training set
Automating Privilege Escalation with Deep Reinforcement Learning
Oct 04, 2021
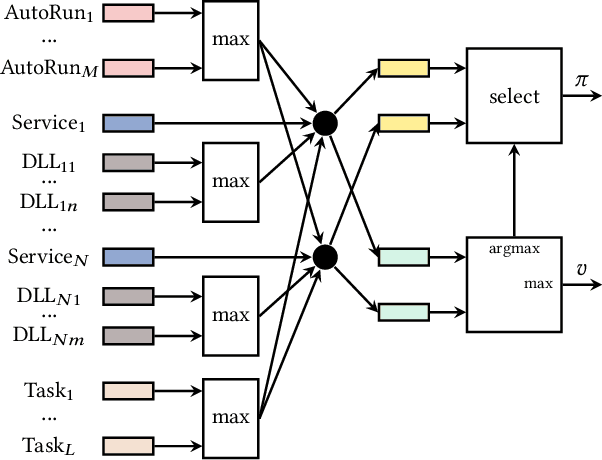
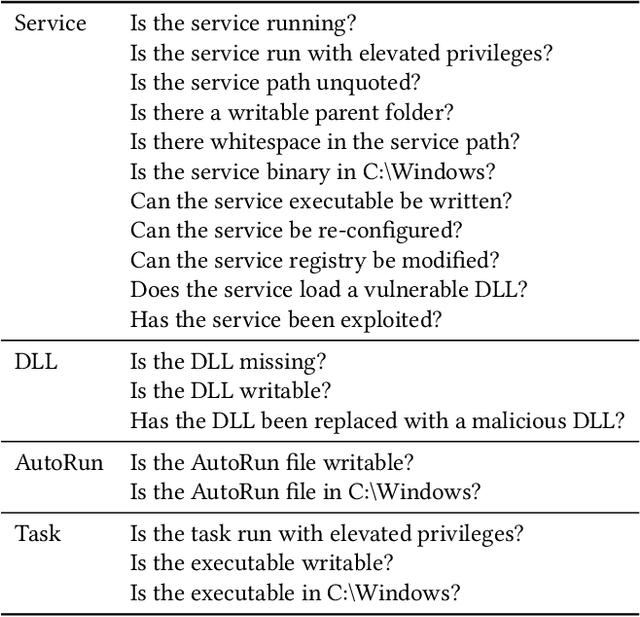
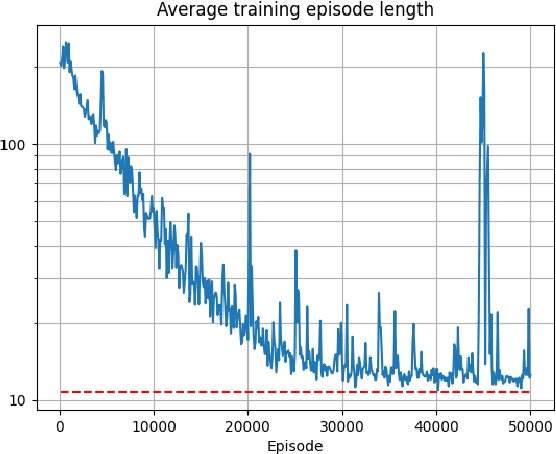
AI-based defensive solutions are necessary to defend networks and information assets against intelligent automated attacks. Gathering enough realistic data for training machine learning-based defenses is a significant practical challenge. An intelligent red teaming agent capable of performing realistic attacks can alleviate this problem. However, there is little scientific evidence demonstrating the feasibility of fully automated attacks using machine learning. In this work, we exemplify the potential threat of malicious actors using deep reinforcement learning to train automated agents. We present an agent that uses a state-of-the-art reinforcement learning algorithm to perform local privilege escalation. Our results show that the autonomous agent can escalate privileges in a Windows 7 environment using a wide variety of different techniques depending on the environment configuration it encounters. Hence, our agent is usable for generating realistic attack sensor data for training and evaluating intrusion detection systems.