 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Injection via Prompt Distillation
Paper and Code



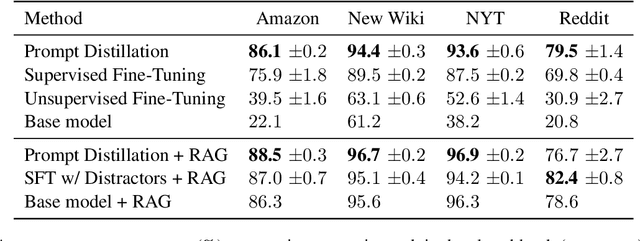
In many practical applications, large language models (LLMs) need to incorporate new knowledge not present in their pre-training data. The primary methods for this are fine-tuning and retrieval-augmented generation (RAG). Although RAG has emerged as the industry standard for knowledge injection, fine-tuning has not yet achieved comparable success. In this paper, we propose a new fine-tuning technique for learning new knowledge and show that it can reach the performance of RAG. The proposed method is based on the self-distillation approach, which we call prompt distillation. First, we generate question-answer pairs about the new knowledge. Then, we fine-tune a student model on the question-answer pairs to imitate the output distributions of a teacher model, which additionally receives the new knowledge in its prompt. The student model is identical to the teacher, except it is equipped with a LoRA adapter. This training procedure facilitates distilling the new knowledge from the teacher's prompt into the student's weights.