 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Fusion for Sensorimotor Coordination in Steering Angle Prediction
Paper and Code
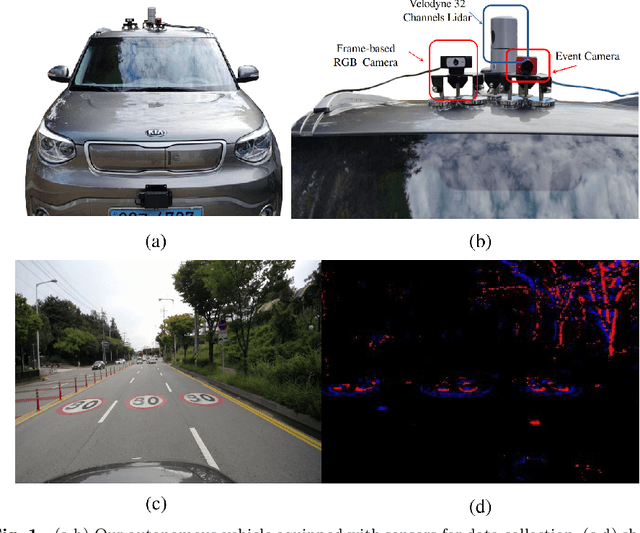
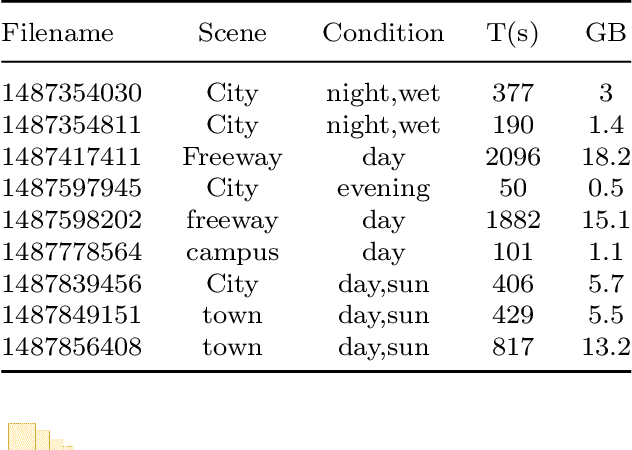
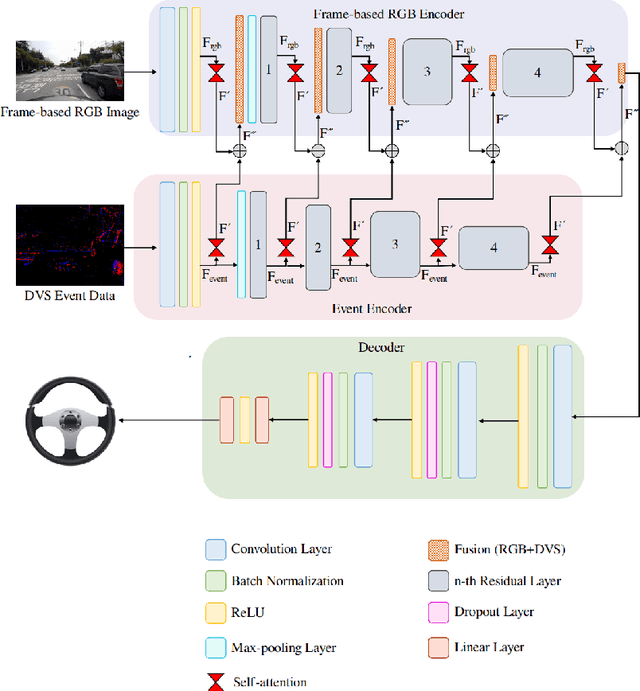
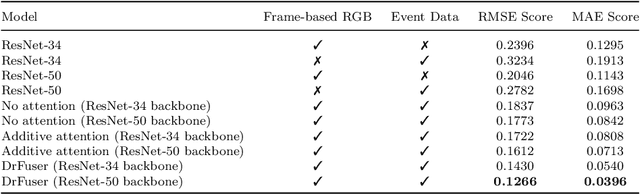
Imitation learning is employed to learn sensorimotor coordination for steering angle prediction in an end-to-end fashion requires expert demonstrations. These expert demonstrations are paired with environmental perception and vehicle control data. The conventional frame-based RGB camera is the most common exteroceptive sensor modality used to acquire the environmental perception data. The frame-based RGB camera has produced promising results when used as a single modality in learning end-to-end lateral control. However, the conventional frame-based RGB camera has limited operability in illumination variation conditions and is affected by the motion blur. The event camera provides complementary information to the frame-based RGB camera. This work explores the fusion of frame-based RGB and event data for learning end-to-end lateral control by predicting steering angle. In addition, how the representation from event data fuse with frame-based RGB data helps to predict the lateral control robustly for the autonomous vehicle. To this end, we propose DRFuser, a novel convolutional encoder-decoder architecture for learning end-to-end lateral control. The encoder module is branched between the frame-based RGB data and event data along with the self-attention layers. Moreover, this study has also contributed to our own collected dataset comprised of event, frame-based RGB, and vehicle control data. The efficacy of the proposed method is experimentally evaluated on our collected dataset, Davis Driving dataset (DDD), and Carla Eventscape dataset. The experimental results illustrate that the proposed method DRFuser outperforms the state-of-the-art in terms of root-mean-square error (RMSE) and mean absolute error (MAE) used as evaluation metrics.