 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Driving Policies for End-to-End Autonomous Driving
Paper and Code
Oct 13, 2022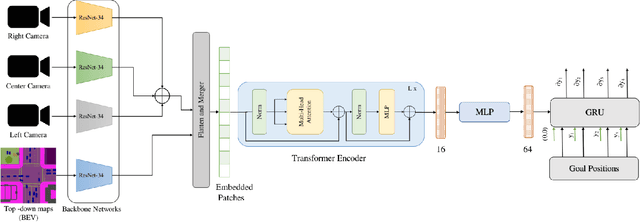

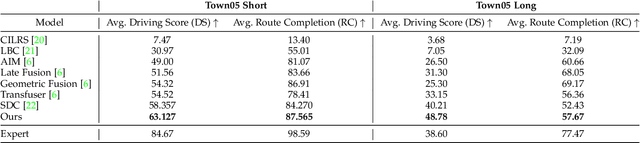
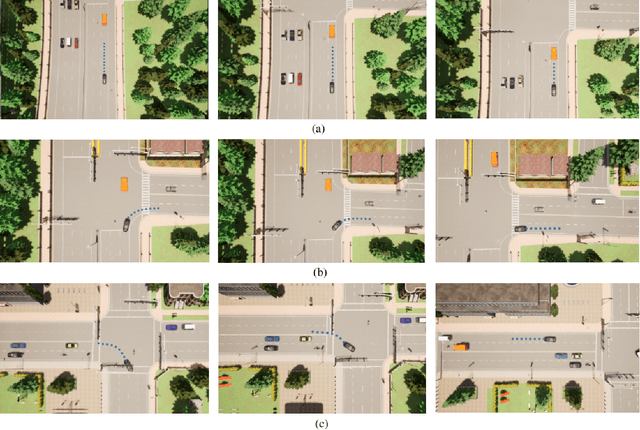
Humans tend to drive vehicles efficiently by relying on contextual and spatial information through the sensory organs. Inspired by this, most of the research is focused on how to learn robust and efficient driving policies. These works are mostly categorized as making modular or end-to-end systems for learning driving policies. However, the former approach has limitations due to the manual supervision of specific modules that hinder the scalability of these systems. In this work, we focus on the latter approach to formalize a framework for learning driving policies for end-to-end autonomous driving. In order to take inspiration from human driving, we have proposed a framework that incorporates three RGB cameras (left, right, and center) to mimic the human field of view and top-down semantic information for contextual representation in predicting the driving policies for autonomous driving. The sensor information is fused and encoded by the self-attention mechanism and followed by the auto-regressive waypoint prediction module. The proposed method's efficacy is experimentally evaluated using the CARLA simulator and outperforms the state-of-the-art methods by achieving the highest driving score at the evaluation time.