 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Scale Shift in Crowd Localization under the Context of Domain Generalization
Oct 22, 2025Crowd localization plays a crucial role in visual scene understanding towards predicting each pedestrian location in a crowd, thus being applicable to various downstream tasks. However, existing approaches suffer from significant performance degradation due to discrepancies in head scale distributions (scale shift) between training and testing data, a challenge known as domain generalization (DG). This paper aims to comprehend the nature of scale shift within the context of domain generalization for crowd localization models. To this end, we address four critical questions: (i) How does scale shift influence crowd localization in a DG scenario? (ii) How can we quantify this influence? (iii) What causes this influence? (iv) How to mitigate the influence? Initially, we conduct a systematic examination of how crowd localization performance varies with different levels of scale shift. Then, we establish a benchmark, ScaleBench, and reproduce 20 advanced DG algorithms to quantify the influence. Through extensive experiments, we demonstrate the limitations of existing algorithms and underscore the importance and complexity of scale shift, a topic that remains insufficiently explored. To deepen our understanding, we provide a rigorous theoretical analysis on scale shift. Building on these insights, we further propose an effective algorithm called Causal Feature Decomposition and Anisotropic Processing (Catto) to mitigate the influence of scale shift in DG settings. Later, we also provide extensive analytical experiments, revealing four significant insights for future research. Our results emphasize the importance of this novel and applicable research direction, which we term Scale Shift Domain Generalization.
Frustratingly Easy Model Generalization by Dummy Risk Minimization
Aug 04, 2023Empirical risk minimization (ERM) is a fundamental machine learning paradigm. However, its generalization ability is limited in various tasks. In this paper, we devise Dummy Risk Minimization (DuRM), a frustratingly easy and general technique to improve the generalization of ERM. DuRM is extremely simple to implement: just enlarging the dimension of the output logits and then optimizing using standard gradient descent. Moreover, we validate the efficacy of DuRM on both theoretical and empirical analysis. Theoretically, we show that DuRM derives greater variance of the gradient, which facilitates model generalization by observing better flat local minima. Empirically, we conduct evaluations of DuRM across different datasets, modalities, and network architectures on diverse tasks, including conventional classification, semantic segmentation, out-of-distribution generalization, adverserial training, and long-tailed recognition. Results demonstrate that DuRM could consistently improve the performance under all tasks with an almost free lunch manner. Furthermore, we show that DuRM is compatible with existing generalization techniques and we discuss possible limitations. We hope that DuRM could trigger new interest in the fundamental research on risk minimization.
Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning
Aug 01, 2023Deep neural networks are susceptible to adversarial examples, posing a significant security risk in critical applications. Adversarial Training (AT) is a well-established technique to enhance adversarial robustness, but it often comes at the cost of decreased generalization ability. This paper proposes Robustness Critical Fine-Tuning (RiFT), a novel approach to enhance generalization without compromising adversarial robustness. The core idea of RiFT is to exploit the redundant capacity for robustness by fine-tuning the adversarially trained model on its non-robust-critical module. To do so, we introduce module robust criticality (MRC), a measure that evaluates the significance of a given module to model robustness under worst-case weight perturbations. Using this measure, we identify the module with the lowest MRC value as the non-robust-critical module and fine-tune its weights to obtain fine-tuned weights. Subsequently, we linearly interpolate between the adversarially trained weights and fine-tuned weights to derive the optimal fine-tuned model weights. We demonstrate the efficacy of RiFT on ResNet18, ResNet34, and WideResNet34-10 models trained on CIFAR10, CIFAR100, and Tiny-ImageNet datasets. Our experiments show that \method can significantly improve both generalization and out-of-distribution robustness by around 1.5% while maintaining or even slightly enhancing adversarial robustness. Code is available at https://github.com/microsoft/robustlearn.
Deep into The Domain Shift: Transfer Learning through Dependence Regularization
May 31, 2023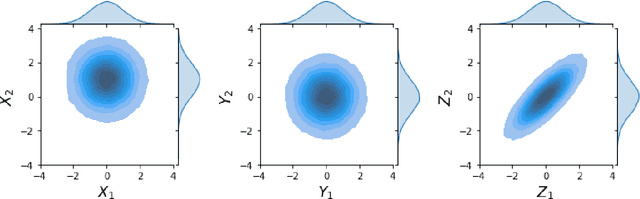
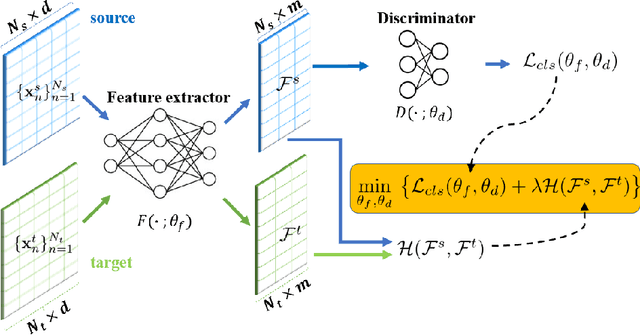
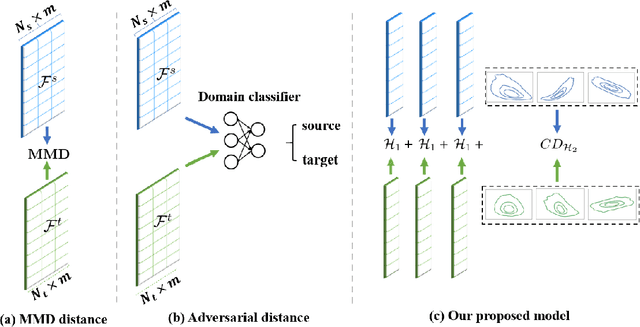

Classical Domain Adaptation methods acquire transferability by regularizing the overall distributional discrepancies between features in the source domain (labeled) and features in the target domain (unlabeled). They often do not differentiate whether the domain differences come from the marginals or the dependence structures. In many business and financial applications, the labeling function usually has different sensitivities to the changes in the marginals versus changes in the dependence structures. Measuring the overall distributional differences will not be discriminative enough in acquiring transferability. Without the needed structural resolution, the learned transfer is less optimal. This paper proposes a new domain adaptation approach in which one can measure the differences in the internal dependence structure separately from those in the marginals. By optimizing the relative weights among them, the new regularization strategy greatly relaxes the rigidness of the existing approaches. It allows a learning machine to pay special attention to places where the differences matter the most. Experiments on three real-world datasets show that the improvements are quite notable and robust compared to various benchmark domain adaptation models.
On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective
Mar 02, 2023



ChatGPT is a recent chatbot service released by OpenAI and is receiving increasing attention over the past few months. While evaluations of various aspects of ChatGPT have been done, its robustness, i.e., the performance to unexpected inputs, is still unclear to the public. Robustness is of particular concern in responsible AI, especially for safety-critical applications. In this paper, we conduct a thorough evaluation of the robustness of ChatGPT from the adversarial and out-of-distribution (OOD) perspective. To do so, we employ the AdvGLUE and ANLI benchmarks to assess adversarial robustness and the Flipkart review and DDXPlus medical diagnosis datasets for OOD evaluation. We select several popular foundation models as baselines. Results show that ChatGPT shows consistent advantages on most adversarial and OOD classification and translation tasks. However, the absolute performance is far from perfection, which suggests that adversarial and OOD robustness remains a significant threat to foundation models. Moreover, ChatGPT shows astounding performance in understanding dialogue-related texts and we find that it tends to provide informal suggestions for medical tasks instead of definitive answers. Finally, we present in-depth discussions of possible research directions.
FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning
Feb 27, 2023



Federated learning (FL) has emerged as a new paradigm for privacy-preserving computation in recent years. Unfortunately, FL faces two critical challenges that hinder its actual performance: data distribution heterogeneity and high resource costs brought by large foundation models. Specifically, the non-IID data in different clients make existing FL algorithms hard to converge while the high resource costs, including computational and communication costs that increase the deployment difficulty in real-world scenarios. In this paper, we propose an effective yet simple method, named FedCLIP, to achieve fast generalization and personalization for CLIP in federated learning. Concretely, we design an attention-based adapter for the large model, CLIP, and the rest operations merely depend on adapters. Lightweight adapters can make the most use of pretrained model information and ensure models be adaptive for clients in specific tasks. Simultaneously, small-scale operations can mitigate the computational burden and communication burden caused by large models. Extensive experiments are conducted on three datasets with distribution shifts. Qualitative and quantitative results demonstrate that FedCLIP significantly outperforms other baselines (9% overall improvements on PACS) and effectively reduces computational and communication costs (283x faster than FedAVG). Our code will be available at: https://github.com/microsoft/PersonalizedFL.