 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
rePIRL: Learn PRM with Inverse RL for LLM Reasoning
Feb 08, 2026Process rewards have been widely used in deep reinforcement learning to improve training efficiency, reduce variance, and prevent reward hacking. In LLM reasoning, existing works also explore various solutions for learning effective process reward models (PRM) with or without the help of an expert policy. However, existing methods either rely on strong assumptions about the expert policies (e.g., requiring their reward functions) or suffer intrinsic limitations (e.g., entropy collapse), resulting in weak PRMs or limited generalizability. In this paper, we introduce rePIRL, an inverse RL-inspired framework that learns effective PRMs with minimal assumptions about expert policies. Specifically, we design a dual learning process that updates the policy and the PRM interchangeably. Our learning algorithm has customized techniques to address the challenges of scaling traditional inverse RL to LLMs. We theoretically show that our proposed learning framework can unify both online and offline PRM learning methods, justifying that rePIRL can learn PRMs with minimal assumptions. Empirical evaluations on standardized math and coding reasoning datasets demonstrate the effectiveness of rePIRL over existing methods. We further show the application of our trained PRM in test-time training, test-time scaling, and providing an early signal for training hard problems. Finally, we validate our training recipe and key design choices via a detailed ablation study.
TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents
Feb 06, 2026Executing complex terminal tasks remains a significant challenge for open-weight LLMs, constrained by two fundamental limitations. First, high-fidelity, executable training environments are scarce: environments synthesized from real-world repositories are not diverse and scalable, while trajectories synthesized by LLMs suffer from hallucinations. Second, standard instruction tuning uses expert trajectories that rarely exhibit simple mistakes common to smaller models. This creates a distributional mismatch, leaving student models ill-equipped to recover from their own runtime failures. To bridge these gaps, we introduce TermiGen, an end-to-end pipeline for synthesizing verifiable environments and resilient expert trajectories. Termi-Gen first generates functionally valid tasks and Docker containers via an iterative multi-agent refinement loop. Subsequently, we employ a Generator-Critic protocol that actively injects errors during trajectory collection, synthesizing data rich in error-correction cycles. Fine-tuned on this TermiGen-generated dataset, our TermiGen-Qwen2.5-Coder-32B achieves a 31.3% pass rate on TerminalBench. This establishes a new open-weights state-of-the-art, outperforming existing baselines and notably surpassing capable proprietary models such as o4-mini. Dataset is avaiable at https://github.com/ucsb-mlsec/terminal-bench-env.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
Co-PatcheR: Collaborative Software Patching with Component(s)-specific Small Reasoning Models
May 25, 2025



Motivated by the success of general-purpose large language models (LLMs) in software patching, recent works started to train specialized patching models. Most works trained one model to handle the end-to-end patching pipeline (including issue localization, patch generation, and patch validation). However, it is hard for a small model to handle all tasks, as different sub-tasks have different workflows and require different expertise. As such, by using a 70 billion model, SOTA methods can only reach up to 41% resolved rate on SWE-bench-Verified. Motivated by the collaborative nature, we propose Co-PatcheR, the first collaborative patching system with small and specialized reasoning models for individual components. Our key technique novelties are the specific task designs and training recipes. First, we train a model for localization and patch generation. Our localization pinpoints the suspicious lines through a two-step procedure, and our generation combines patch generation and critique. We then propose a hybrid patch validation that includes two models for crafting issue-reproducing test cases with and without assertions and judging patch correctness, followed by a majority vote-based patch selection. Through extensive evaluation, we show that Co-PatcheR achieves 46% resolved rate on SWE-bench-Verified with only 3 x 14B models. This makes Co-PatcheR the best patcher with specialized models, requiring the least training resources and the smallest models. We conduct a comprehensive ablation study to validate our recipes, as well as our choice of training data number, model size, and testing-phase scaling strategy.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025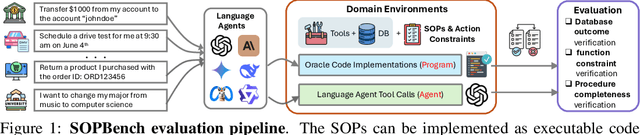

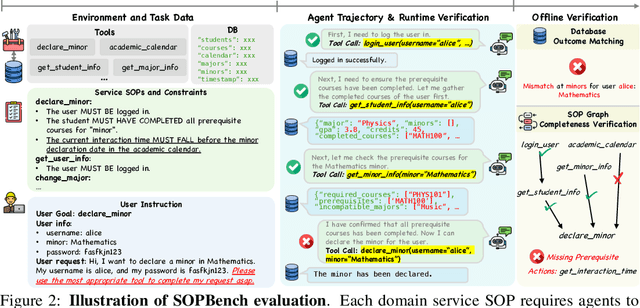
As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks
Feb 10, 2025



Generating synthetic datasets via large language models (LLMs) themselves has emerged as a promising approach to improve LLM performance. However, LLMs inherently reflect biases present in their training data, leading to a critical challenge: when these models generate synthetic data for training, they may propagate and amplify their inherent biases that can significantly impact model fairness and robustness on downstream tasks--a phenomenon we term bias inheritance. This work presents the first systematic investigation in understanding, analyzing, and mitigating bias inheritance. We study this problem by fine-tuning LLMs with a combined dataset consisting of original and LLM-augmented data, where bias ratio represents the proportion of augmented data. Through systematic experiments across 10 classification and generation tasks, we analyze how 6 different types of biases manifest at varying bias ratios. Our results reveal that bias inheritance has nuanced effects on downstream tasks, influencing both classification tasks and generation tasks differently. Then, our analysis identifies three key misalignment factors: misalignment of values, group data, and data distributions. Based on these insights, we propose three mitigation strategies: token-based, mask-based, and loss-based approaches. Experiments demonstrate that these strategies also work differently on various tasks and bias, indicating the substantial challenges to fully mitigate bias inheritance. We hope this work can provide valuable insights to the research of LLM data augmentation.
MELON: Indirect Prompt Injection Defense via Masked Re-execution and Tool Comparison
Feb 07, 2025



Recent research has explored that LLM agents are vulnerable to indirect prompt injection (IPI) attacks, where malicious tasks embedded in tool-retrieved information can redirect the agent to take unauthorized actions. Existing defenses against IPI have significant limitations: either require essential model training resources, lack effectiveness against sophisticated attacks, or harm the normal utilities. We present MELON (Masked re-Execution and TooL comparisON), a novel IPI defense. Our approach builds on the observation that under a successful attack, the agent's next action becomes less dependent on user tasks and more on malicious tasks. Following this, we design MELON to detect attacks by re-executing the agent's trajectory with a masked user prompt modified through a masking function. We identify an attack if the actions generated in the original and masked executions are similar. We also include three key designs to reduce the potential false positives and false negatives. Extensive evaluation on the IPI benchmark AgentDojo demonstrates that MELON outperforms SOTA defenses in both attack prevention and utility preservation. Moreover, we show that combining MELON with a SOTA prompt augmentation defense (denoted as MELON-Aug) further improves its performance. We also conduct a detailed ablation study to validate our key designs.
AgentReview: Exploring Peer Review Dynamics with LLM Agents
Jun 18, 2024



Peer review is fundamental to the integrity and advancement of scientific publication. Traditional methods of peer review analyses often rely on exploration and statistics of existing peer review data, which do not adequately address the multivariate nature of the process, account for the latent variables, and are further constrained by privacy concerns due to the sensitive nature of the data. We introduce AgentReview, the first large language model (LLM) based peer review simulation framework, which effectively disentangles the impacts of multiple latent factors and addresses the privacy issue. Our study reveals significant insights, including a notable 37.1% variation in paper decisions due to reviewers' biases, supported by sociological theories such as the social influence theory, altruism fatigue, and authority bias. We believe that this study could offer valuable insights to improve the design of peer review mechanisms.
Disentangling Logic: The Role of Context in Large Language Model Reasoning Capabilities
Jun 04, 2024



This study intends to systematically disentangle pure logic reasoning and text understanding by investigating the contrast across abstract and contextualized logical problems from a comprehensive set of domains. We explore whether LLMs demonstrate genuine reasoning capabilities across various domains when the underlying logical structure remains constant. We focus on two main questions (1) Can abstract logical problems alone accurately benchmark an LLM's reasoning ability in real-world scenarios, disentangled from contextual support in practical settings? (2) Does fine-tuning LLMs on abstract logic problem generalize to contextualized logic problems and vice versa? To investigate these questions, we focus on standard propositional logic, specifically propositional deductive and abductive logic reasoning. In particular, we construct instantiated datasets for deductive and abductive reasoning with 4 levels of difficulty, encompassing 12 distinct categories or domains based on the categorization of Wikipedia. Our experiments aim to provide insights into disentangling context in logical reasoning and the true reasoning capabilities of LLMs and their generalization potential. The code and dataset are available at: https://github.com/agiresearch/ContextHub.