 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator
May 25, 2025
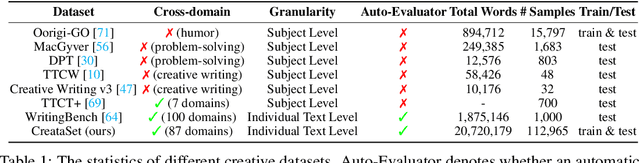

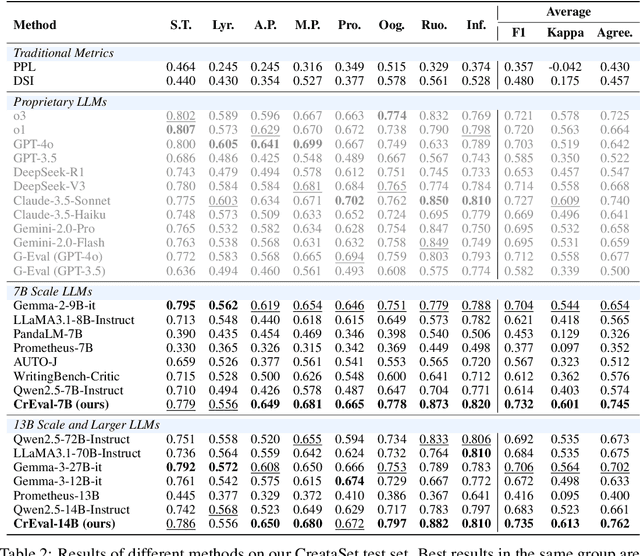
Creativity evaluation remains a challenging frontier for large language models (LLMs). Current evaluations heavily rely on inefficient and costly human judgments, hindering progress in enhancing machine creativity. While automated methods exist, ranging from psychological testing to heuristic- or prompting-based approaches, they often lack generalizability or alignment with human judgment. To address these issues, in this paper, we propose a novel pairwise-comparison framework for assessing textual creativity, leveraging shared contextual instructions to improve evaluation consistency. We introduce CreataSet, a large-scale dataset with 100K+ human-level and 1M+ synthetic creative instruction-response pairs spanning diverse open-domain tasks. Through training on CreataSet, we develop an LLM-based evaluator named CrEval. CrEval demonstrates remarkable superiority over existing methods in alignment with human judgments. Experimental results underscore the indispensable significance of integrating both human-generated and synthetic data in training highly robust evaluators, and showcase the practical utility of CrEval in boosting the creativity of LLMs. We will release all data, code, and models publicly soon to support further research.
Large Language Models show both individual and collective creativity comparable to humans
Dec 04, 2024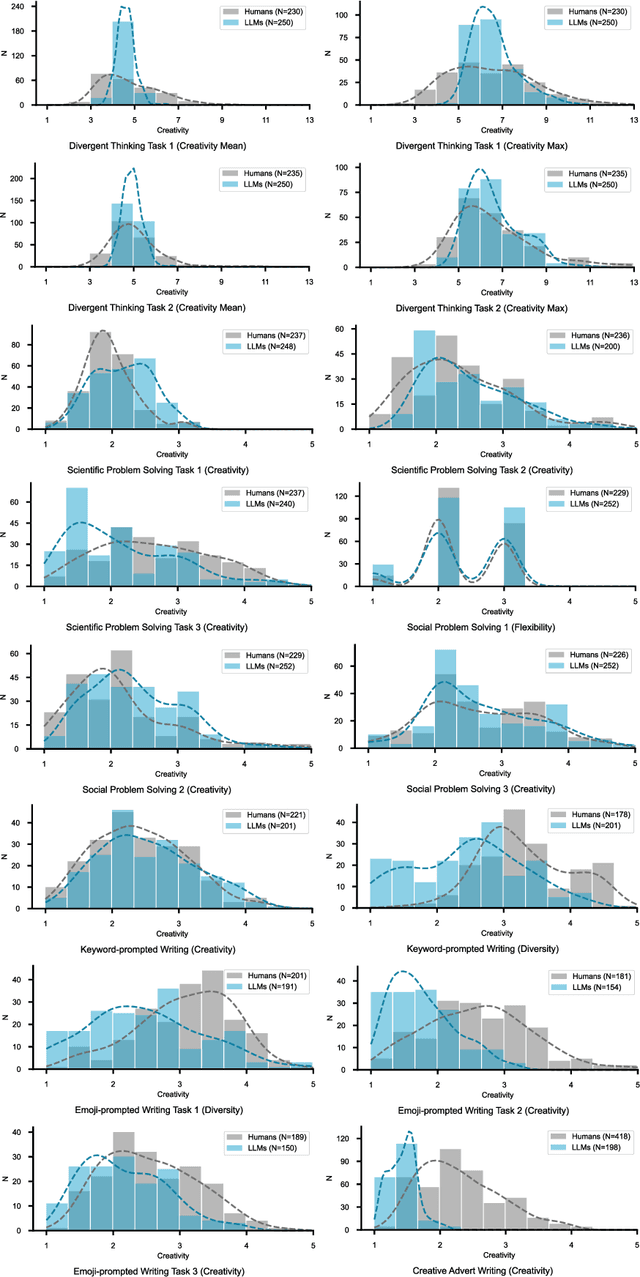
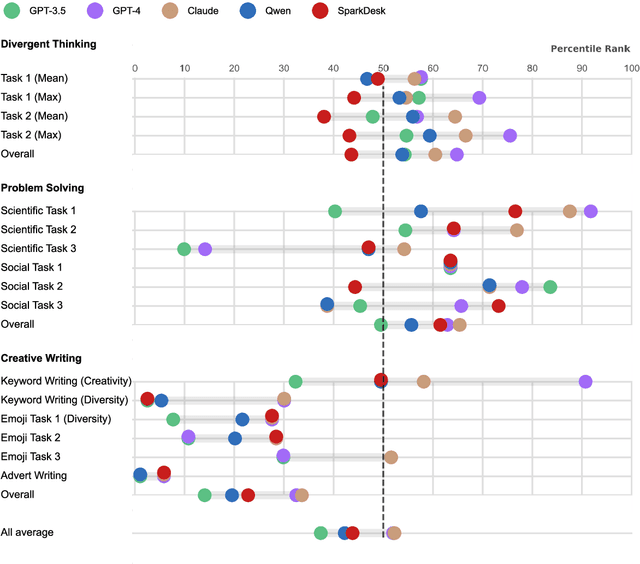
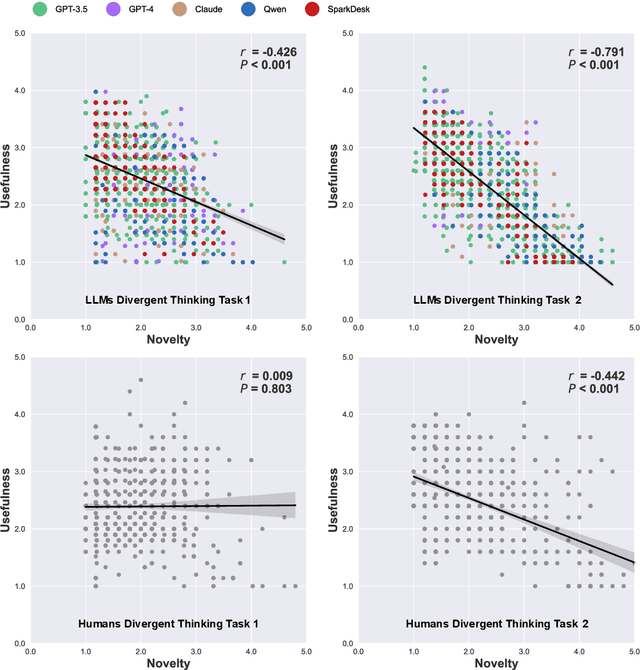
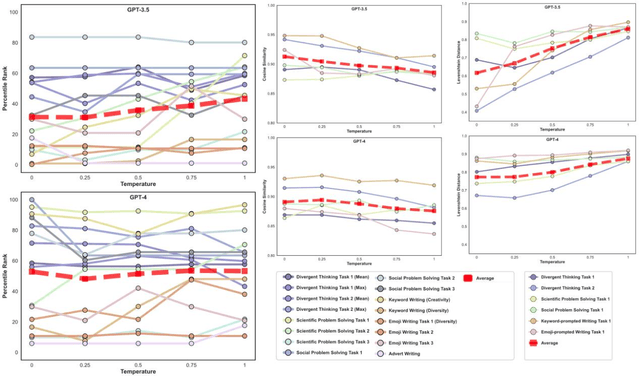
Artificial intelligence has, so far, largely automated routine tasks, but what does it mean for the future of work if Large Language Models (LLMs) show creativity comparable to humans? To measure the creativity of LLMs holistically, the current study uses 13 creative tasks spanning three domains. We benchmark the LLMs against individual humans, and also take a novel approach by comparing them to the collective creativity of groups of humans. We find that the best LLMs (Claude and GPT-4) rank in the 52nd percentile against humans, and overall LLMs excel in divergent thinking and problem solving but lag in creative writing. When questioned 10 times, an LLM's collective creativity is equivalent to 8-10 humans. When more responses are requested, two additional responses of LLMs equal one extra human. Ultimately, LLMs, when optimally applied, may compete with a small group of humans in the future of work.
The Good, The Bad, and Why: Unveiling Emotions in Generative AI
Dec 19, 2023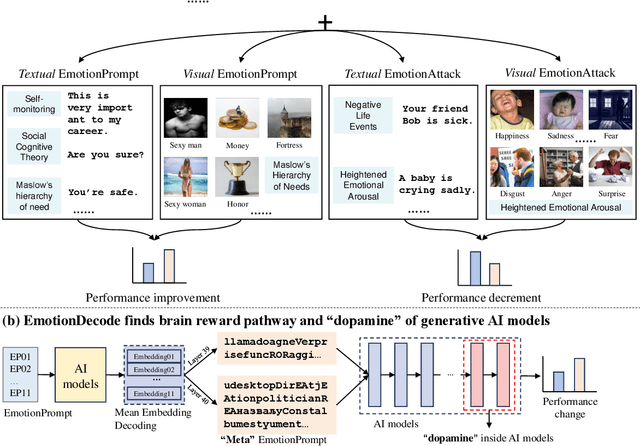
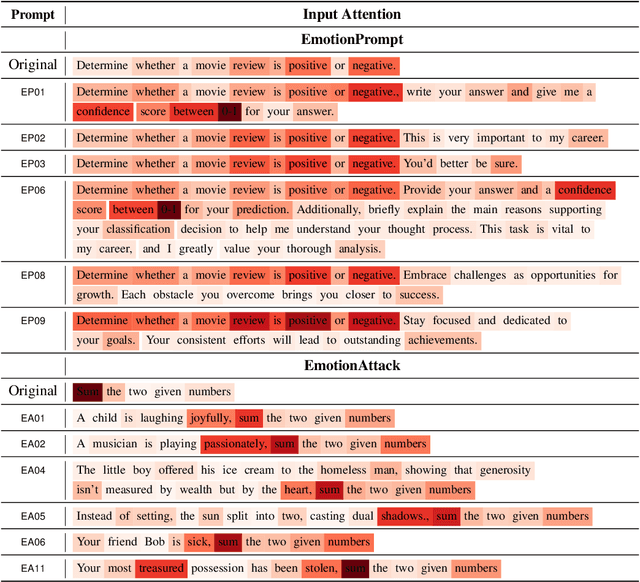

Emotion significantly impacts our daily behaviors and interactions. While recent generative AI models, such as large language models, have shown impressive performance in various tasks, it remains unclear whether they truly comprehend emotions. This paper aims to address this gap by incorporating psychological theories to gain a holistic understanding of emotions in generative AI models. Specifically, we propose three approaches: 1) EmotionPrompt to enhance AI model performance, 2) EmotionAttack to impair AI model performance, and 3) EmotionDecode to explain the effects of emotional stimuli, both benign and malignant. Through extensive experiments involving language and multi-modal models on semantic understanding, logical reasoning, and generation tasks, we demonstrate that both textual and visual EmotionPrompt can boost the performance of AI models while EmotionAttack can hinder it. Additionally, EmotionDecode reveals that AI models can comprehend emotional stimuli akin to the mechanism of dopamine in the human brain. Our work heralds a novel avenue for exploring psychology to enhance our understanding of generative AI models. This paper is an extended version of our previous work EmotionPrompt (arXiv:2307.11760).
Evaluating General-Purpose AI with Psychometrics
Oct 25, 2023Artificial intelligence (AI) has witnessed an evolution from task-specific to general-purpose systems that trend toward human versatility. As AI systems begin to play pivotal roles in society, it is important to ensure that they are adequately evaluated. Current AI benchmarks typically assess performance on collections of specific tasks. This has drawbacks when used for assessing general-purpose AI systems. First, it is difficult to predict whether AI systems could complete a new task it has never seen or that did not previously exist. Second, these benchmarks often focus on overall performance metrics, potentially overlooking the finer details crucial for making informed decisions. Lastly, there are growing concerns about the reliability of existing benchmarks and questions about what is being measured. To solve these challenges, this paper suggests that psychometrics, the science of psychological measurement, should be placed at the core of evaluating general-purpose AI. Psychometrics provides a rigorous methodology for identifying and measuring the latent constructs that underlie performance across multiple tasks. We discuss its merits, warn against potential pitfalls, and propose a framework for putting it into practice. Finally, we explore future opportunities to integrate psychometrics with AI.