 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Uplift Modeling under Structural Biases: Insights into Metric Stability and Model Robustness
Mar 21, 2026In personalized marketing, uplift models estimate incremental effects by modeling how customer behavior changes under alternative treatments. However, real-world data often exhibit biases - such as selection bias, spillover effects, and unobserved confounding - which adversely affect both estimation accuracy and metric validity. Despite the importance of bias-aware assessment, a lack of systematic studies persists. To bridge this gap, we design a systematic benchmarking framework. Unlike standard predictive tasks, real-world uplift datasets lack counterfactual ground truth, rendering direct metric validation infeasible. Therefore, a semi-synthetic approach serves as a critical enabler for systematic benchmarking, effectively bridging the gap by retaining real-world feature dependencies while providing the ground truth needed to isolate structural biases. Our investigations reveal that: (i) uplift targeting and prediction can manifest as distinct objectives, where proficiency in one does not ensure efficacy in the other; (ii) while many models exhibit inconsistent performance under diverse biases, TARNet shows notable robustness, providing insights for subsequent model design; (iii) evaluation metric stability is linked to mathematical alignment with the ATE, suggesting that ATE-approximating metrics yield more consistent model rankings under structural data imperfections. These findings suggest the need for more robust uplift models and metrics. Code will be released upon acceptance.
Membership Inference for Contrastive Pre-training Models with Text-only PII Queries
Mar 15, 2026Contrastive pretraining models such as CLIP and CLAP underpin many vision-language and audio-language systems, yet their reliance on web-scale data raises growing concerns about memorizing Personally Identifiable Information (PII). Auditing such models via membership inference is challenging in practice: shadow-model MIAs are computationally prohibitive for large multimodal backbones, and existing multimodal attacks typically require querying the target with paired biometric inputs, thereby directly exposing sensitive biometric information to the target model. We propose Unimodal Membership Inference Detector (UMID), a text-only auditing framework that performs text-guided cross-modal latent inversion and extracts two complementary signals, similarity (alignment to the queried text) and variability (consistency across randomized inversions). UMID compares these statistics to a lightweight non-member reference constructed from synthetic gibberish and makes decisions via an ensemble of unsupervised anomaly detectors. Comprehensive experiments across diverse CLIP and CLAP architectures demonstrate that UMID significantly improves the effectiveness and efficiency over prior MIAs, delivering strong detection performance with sub-second auditing cost while complying with realistic privacy constraints.
Distributionally Robust Policy Evaluation and Learning for Continuous Treatment with Observational Data
Jan 18, 2025Using offline observational data for policy evaluation and learning allows decision-makers to evaluate and learn a policy that connects characteristics and interventions. Most existing literature has focused on either discrete treatment spaces or assumed no difference in the distributions between the policy-learning and policy-deployed environments. These restrict applications in many real-world scenarios where distribution shifts are present with continuous treatment. To overcome these challenges, this paper focuses on developing a distributionally robust policy under a continuous treatment setting. The proposed distributionally robust estimators are established using the Inverse Probability Weighting (IPW) method extended from the discrete one for policy evaluation and learning under continuous treatments. Specifically, we introduce a kernel function into the proposed IPW estimator to mitigate the exclusion of observations that can occur in the standard IPW method to continuous treatments. We then provide finite-sample analysis that guarantees the convergence of the proposed distributionally robust policy evaluation and learning estimators. The comprehensive experiments further verify the effectiveness of our approach when distribution shifts are present.
Unveiling the Potential of Robustness in Evaluating Causal Inference Models
Feb 28, 2024



The growing demand for personalized decision-making has led to a surge of interest in estimating the Conditional Average Treatment Effect (CATE). The intersection of machine learning and causal inference has yielded various effective CATE estimators. However, deploying these estimators in practice is often hindered by the absence of counterfactual labels, making it challenging to select the desirable CATE estimator using conventional model selection procedures like cross-validation. Existing approaches for CATE estimator selection, such as plug-in and pseudo-outcome metrics, face two inherent challenges. Firstly, they are required to determine the metric form and the underlying machine learning models for fitting nuisance parameters or plug-in learners. Secondly, they lack a specific focus on selecting a robust estimator. To address these challenges, this paper introduces a novel approach, the Distributionally Robust Metric (DRM), for CATE estimator selection. The proposed DRM not only eliminates the need to fit additional models but also excels at selecting a robust CATE estimator. Experimental studies demonstrate the efficacy of the DRM method, showcasing its consistent effectiveness in identifying superior estimators while mitigating the risk of selecting inferior ones.
The Causal Impact of Credit Lines on Spending Distributions
Dec 16, 2023Consumer credit services offered by e-commerce platforms provide customers with convenient loan access during shopping and have the potential to stimulate sales. To understand the causal impact of credit lines on spending, previous studies have employed causal estimators, based on direct regression (DR), inverse propensity weighting (IPW), and double machine learning (DML) to estimate the treatment effect. However, these estimators do not consider the notion that an individual's spending can be understood and represented as a distribution, which captures the range and pattern of amounts spent across different orders. By disregarding the outcome as a distribution, valuable insights embedded within the outcome distribution might be overlooked. This paper develops a distribution-valued estimator framework that extends existing real-valued DR-, IPW-, and DML-based estimators to distribution-valued estimators within Rubin's causal framework. We establish their consistency and apply them to a real dataset from a large e-commerce platform. Our findings reveal that credit lines positively influence spending across all quantiles; however, as credit lines increase, consumers allocate more to luxuries (higher quantiles) than necessities (lower quantiles).
Deep into The Domain Shift: Transfer Learning through Dependence Regularization
May 31, 2023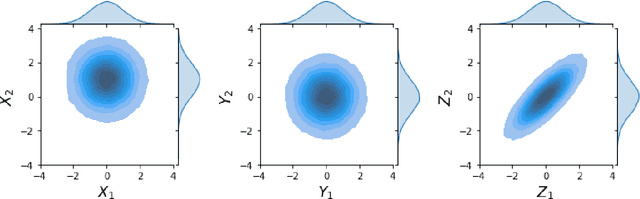
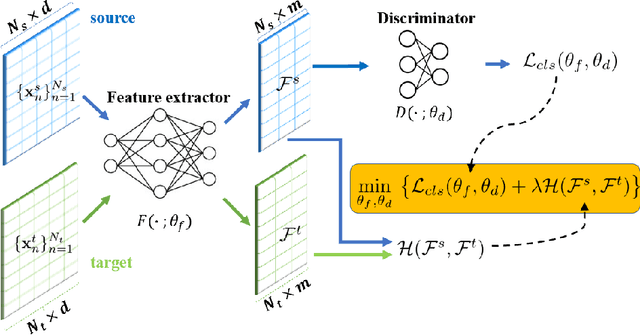
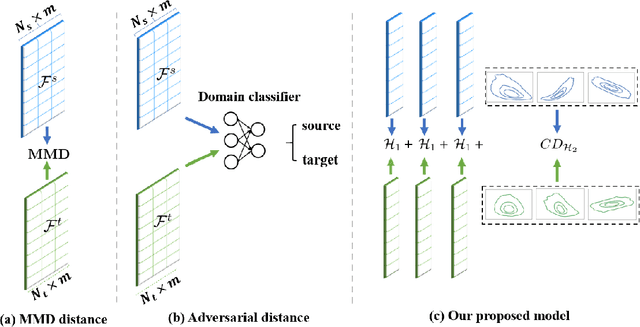

Classical Domain Adaptation methods acquire transferability by regularizing the overall distributional discrepancies between features in the source domain (labeled) and features in the target domain (unlabeled). They often do not differentiate whether the domain differences come from the marginals or the dependence structures. In many business and financial applications, the labeling function usually has different sensitivities to the changes in the marginals versus changes in the dependence structures. Measuring the overall distributional differences will not be discriminative enough in acquiring transferability. Without the needed structural resolution, the learned transfer is less optimal. This paper proposes a new domain adaptation approach in which one can measure the differences in the internal dependence structure separately from those in the marginals. By optimizing the relative weights among them, the new regularization strategy greatly relaxes the rigidness of the existing approaches. It allows a learning machine to pay special attention to places where the differences matter the most. Experiments on three real-world datasets show that the improvements are quite notable and robust compared to various benchmark domain adaptation models.
Moderately-Balanced Representation Learning for Treatment Effects with Orthogonality Information
Sep 05, 2022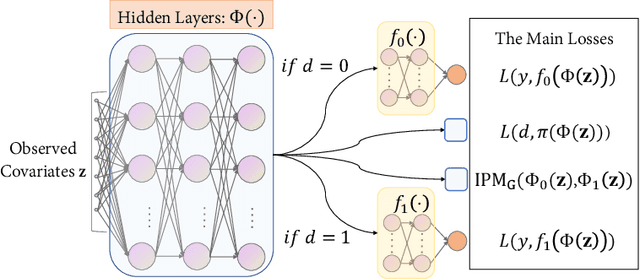
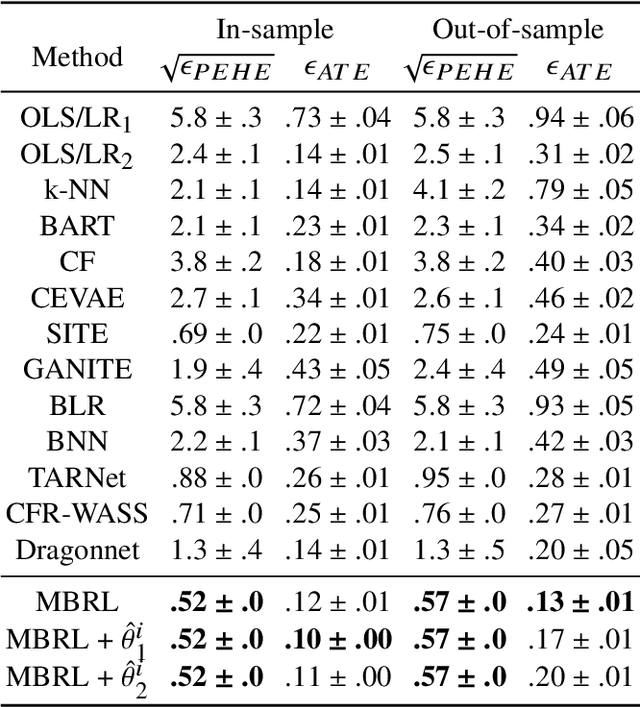
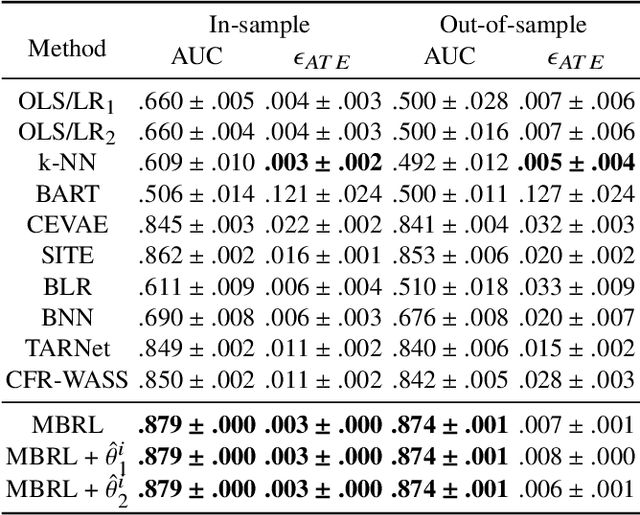
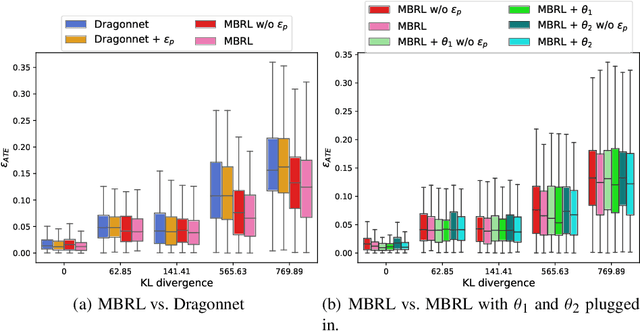
Estimating the average treatment effect (ATE) from observational data is challenging due to selection bias. Existing works mainly tackle this challenge in two ways. Some researchers propose constructing a score function that satisfies the orthogonal condition, which guarantees that the established ATE estimator is "orthogonal" to be more robust. The others explore representation learning models to achieve a balanced representation between the treated and the controlled groups. However, existing studies fail to 1) discriminate treated units from controlled ones in the representation space to avoid the over-balanced issue; 2) fully utilize the "orthogonality information". In this paper, we propose a moderately-balanced representation learning (MBRL) framework based on recent covariates balanced representation learning methods and orthogonal machine learning theory. This framework protects the representation from being over-balanced via multi-task learning. Simultaneously, MBRL incorporates the noise orthogonality information in the training and validation stages to achieve a better ATE estimation. The comprehensive experiments on benchmark and simulated datasets show the superiority and robustness of our method on treatment effect estimations compared with existing state-of-the-art methods.
Robust Causal Learning for the Estimation of Average Treatment Effects
Sep 05, 2022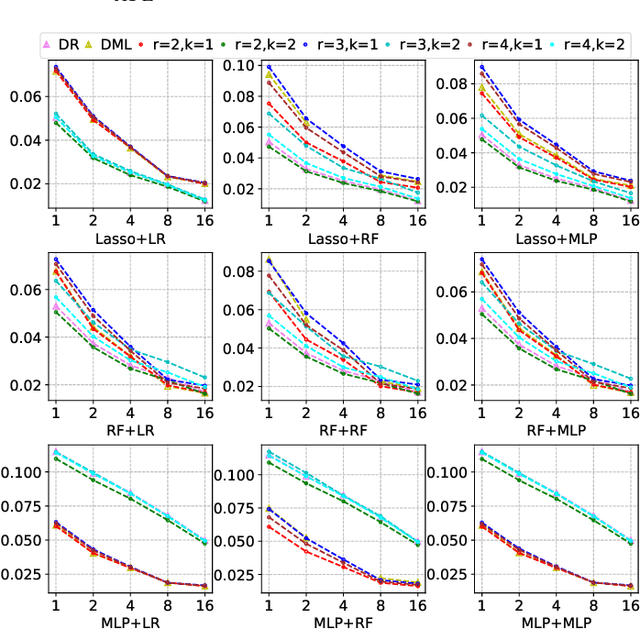
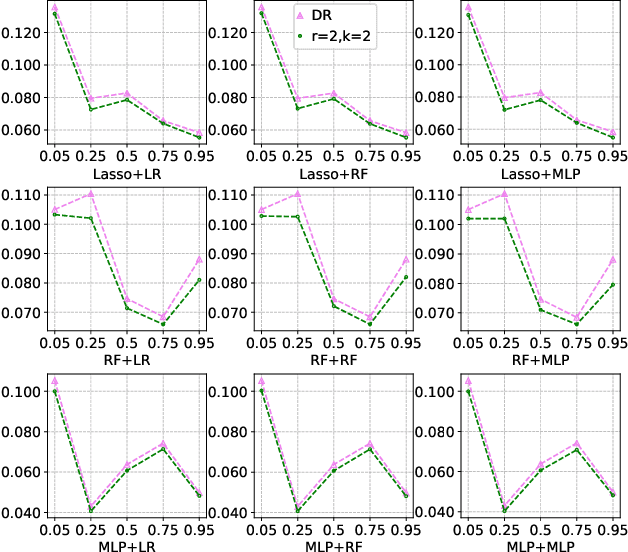
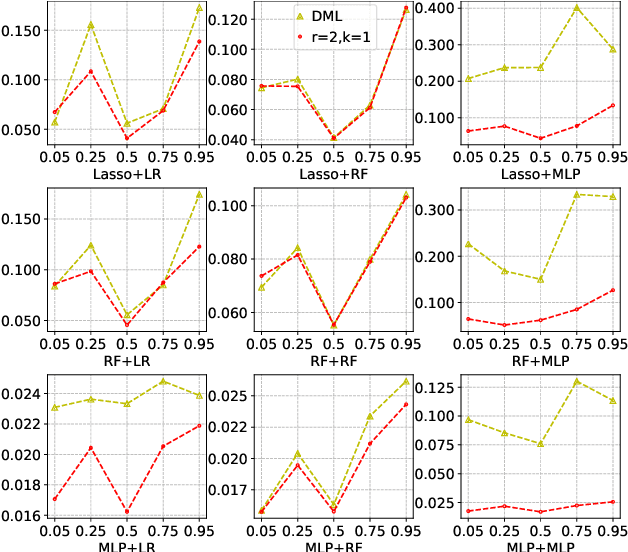
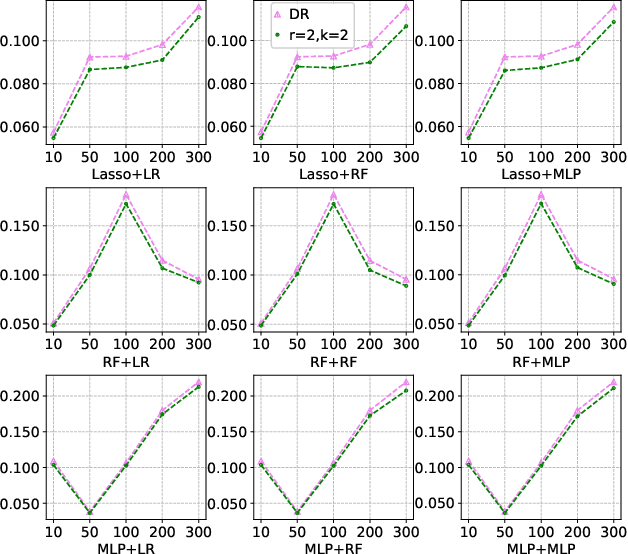
Many practical decision-making problems in economics and healthcare seek to estimate the average treatment effect (ATE) from observational data. The Double/Debiased Machine Learning (DML) is one of the prevalent methods to estimate ATE in the observational study. However, the DML estimators can suffer an error-compounding issue and even give an extreme estimate when the propensity scores are misspecified or very close to 0 or 1. Previous studies have overcome this issue through some empirical tricks such as propensity score trimming, yet none of the existing literature solves this problem from a theoretical standpoint. In this paper, we propose a Robust Causal Learning (RCL) method to offset the deficiencies of the DML estimators. Theoretically, the RCL estimators i) are as consistent and doubly robust as the DML estimators, and ii) can get rid of the error-compounding issue. Empirically, the comprehensive experiments show that i) the RCL estimators give more stable estimations of the causal parameters than the DML estimators, and ii) the RCL estimators outperform the traditional estimators and their variants when applying different machine learning models on both simulation and benchmark datasets.
Higher-Order Orthogonal Causal Learning for Treatment Effect
Mar 22, 2021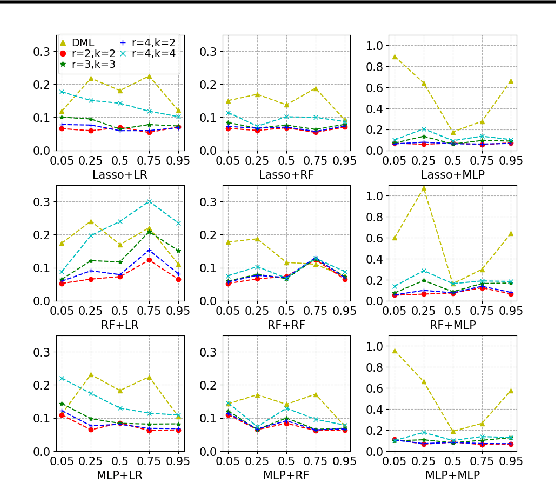
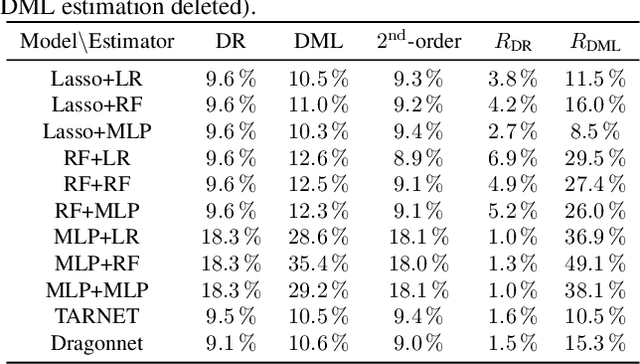
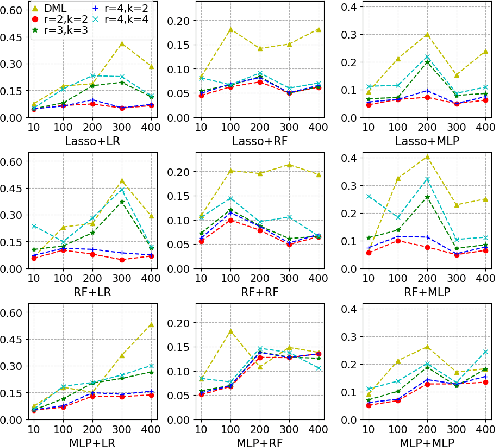
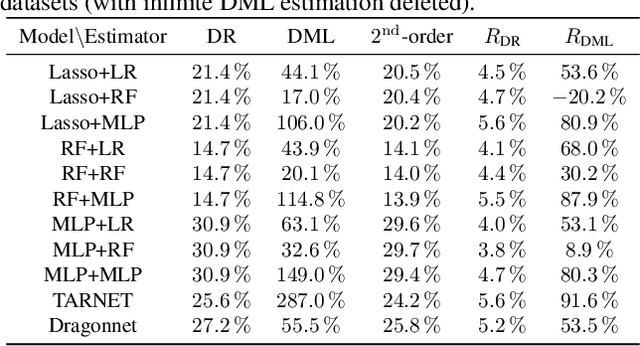
Most existing studies on the double/debiased machine learning method concentrate on the causal parameter estimation recovering from the first-order orthogonal score function. In this paper, we will construct the $k^{\mathrm{th}}$-order orthogonal score function for estimating the average treatment effect (ATE) and present an algorithm that enables us to obtain the debiased estimator recovered from the score function. Such a higher-order orthogonal estimator is more robust to the misspecification of the propensity score than the first-order one does. Besides, it has the merit of being applicable with many machine learning methodologies such as Lasso, Random Forests, Neural Nets, etc. We also undergo comprehensive experiments to test the power of the estimator we construct from the score function using both the simulated datasets and the real datasets.
The Causal Learning of Retail Delinquency
Dec 17, 2020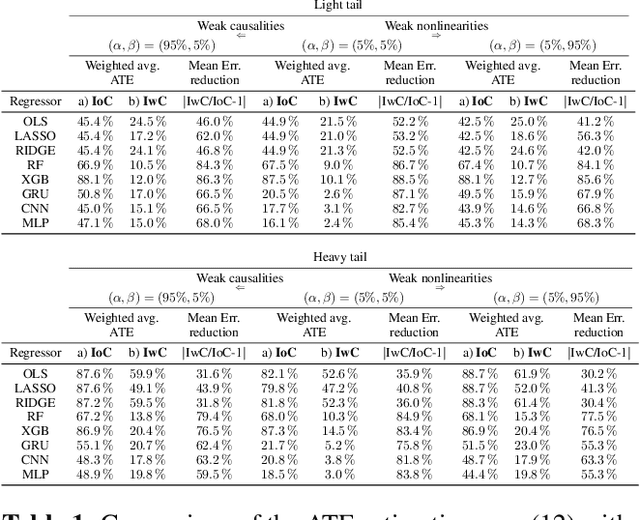
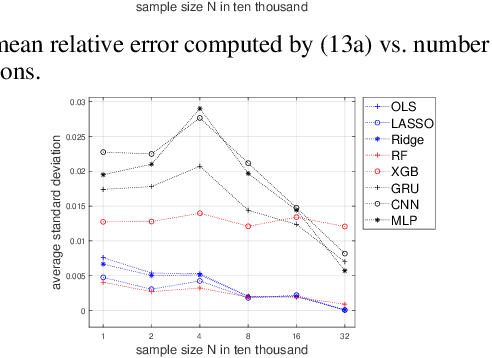

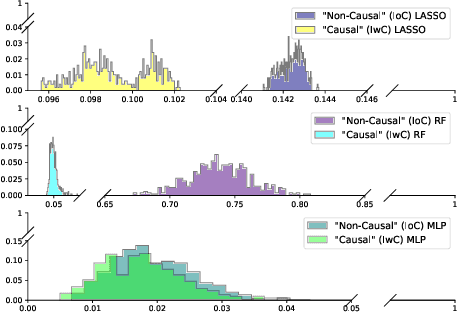
This paper focuses on the expected difference in borrower's repayment when there is a change in the lender's credit decisions. Classical estimators overlook the confounding effects and hence the estimation error can be magnificent. As such, we propose another approach to construct the estimators such that the error can be greatly reduced. The proposed estimators are shown to be unbiased, consistent, and robust through a combination of theoretical analysis and numerical testing. Moreover, we compare the power of estimating the causal quantities between the classical estimators and the proposed estimators. The comparison is tested across a wide range of models, including linear regression models, tree-based models, and neural network-based models, under different simulated datasets that exhibit different levels of causality, different degrees of nonlinearity, and different distributional properties. Most importantly, we apply our approaches to a large observational dataset provided by a global technology firm that operates in both the e-commerce and the lending business. We find that the relative reduction of estimation error is strikingly substantial if the causal effects are accounted for correctly.