 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini in an arena for learning
May 30, 2025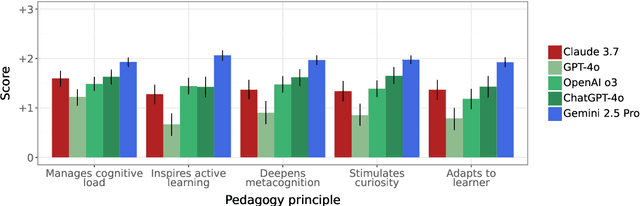

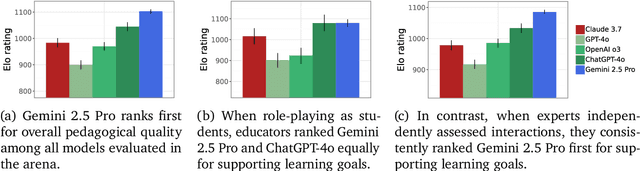
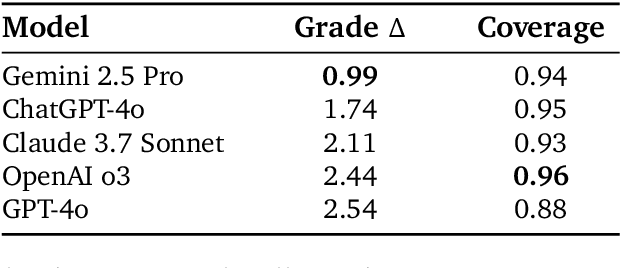
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024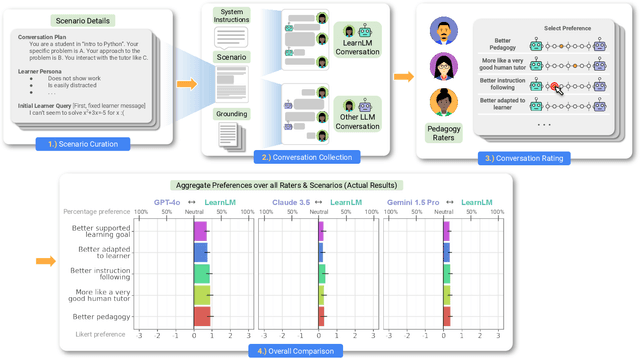
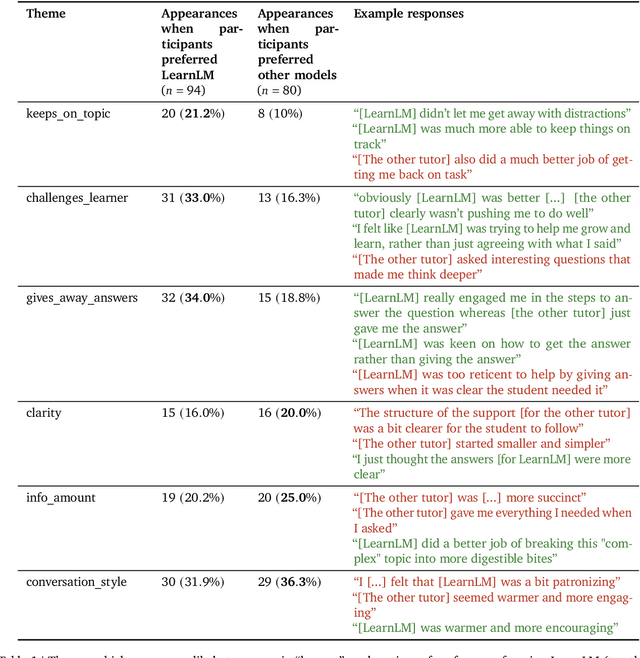
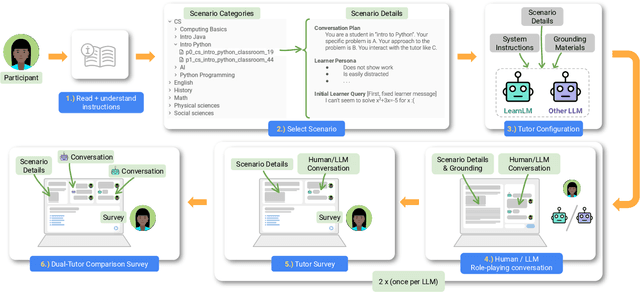
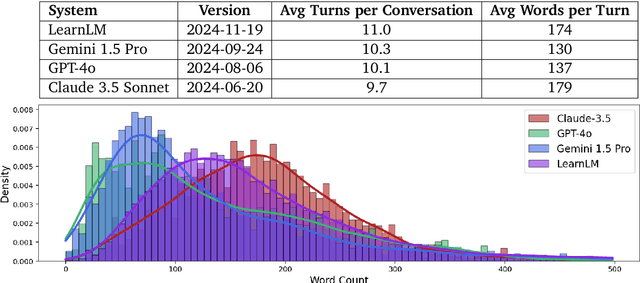
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Discourse Analysis via Questions and Answers: Parsing Dependency Structures of Questions Under Discussion
Oct 12, 2022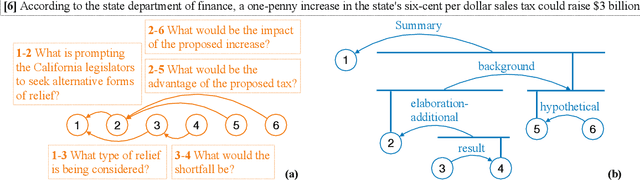

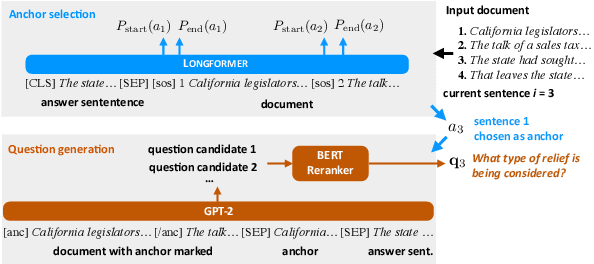
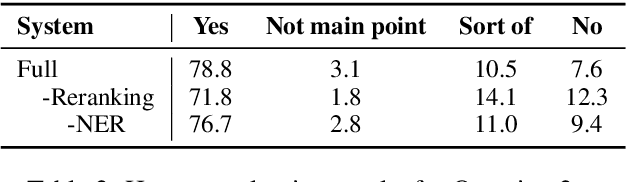
Automatic discourse processing, which can help understand how sentences connect to each other, is bottlenecked by data: current discourse formalisms pose highly demanding annotation tasks involving large taxonomies of discourse relations, making them inaccessible to lay annotators. This work instead adopts the linguistic framework of Questions Under Discussion (QUD) for discourse analysis and seeks to derive QUD structures automatically. QUD views each sentence as an answer to a question triggered in prior context; thus, we characterize relationships between sentences as free-form questions, in contrast to exhaustive fine-grained taxonomies. We develop the first-of-its-kind QUD parser that derives a dependency structure of questions over full documents, trained using a large question-answering dataset DCQA annotated in a manner consistent with the QUD framework. Importantly, data collection is easily crowdsourced using DCQA's paradigm. We show that this leads to a parser attaining strong performance according to human evaluation. We illustrate how our QUD structure is distinct from RST trees, and demonstrate the utility of QUD analysis in the context of document simplification. Our findings show that QUD parsing is an appealing alternative for automatic discourse processing.
Discourse Comprehension: A Question Answering Framework to Represent Sentence Connections
Nov 01, 2021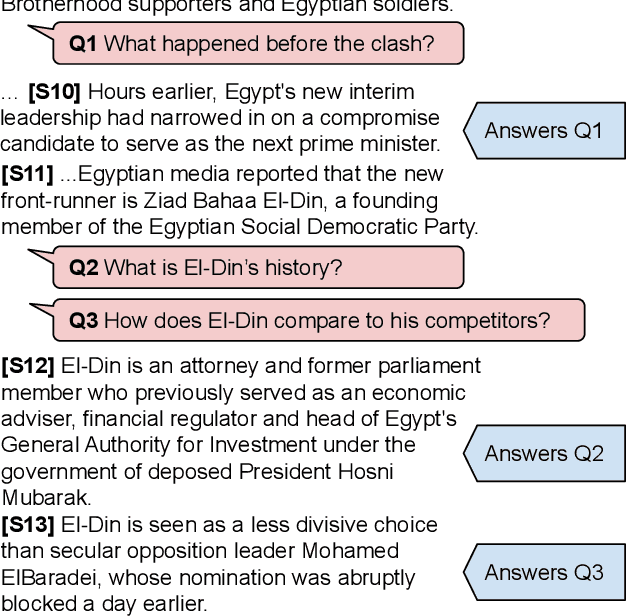


While there has been substantial progress in text comprehension through simple factoid question answering, more holistic comprehension of a discourse still presents a major challenge. Someone critically reflecting on a text as they read it will pose curiosity-driven, often open-ended questions, which reflect deep understanding of the content and require complex reasoning to answer. A key challenge in building and evaluating models for this type of discourse comprehension is the lack of annotated data, especially since finding answers to such questions (which may not be answered at all) requires high cognitive load for annotators over long documents. This paper presents a novel paradigm that enables scalable data collection targeting the comprehension of news documents, viewing these questions through the lens of discourse. The resulting corpus, DCQA (Discourse Comprehension by Question Answering), consists of 22,430 question-answer pairs across 607 English documents. DCQA captures both discourse and semantic links between sentences in the form of free-form, open-ended questions. On an evaluation set that we annotated on questions from the INQUISITIVE dataset, we show that DCQA provides valuable supervision for answering open-ended questions. We additionally design pre-training methods utilizing existing question-answering resources, and use synthetic data to accommodate unanswerable questions.
Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data
Jun 02, 2021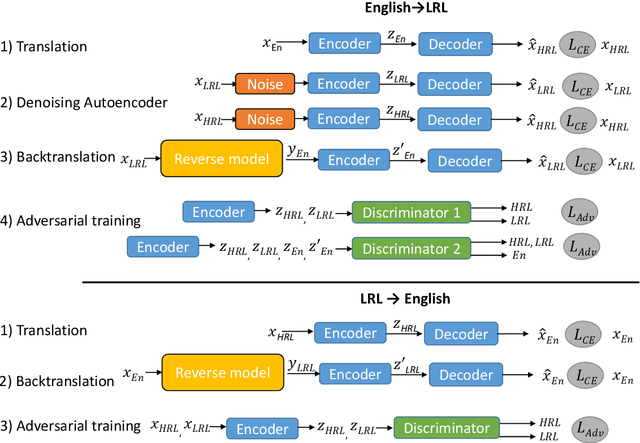
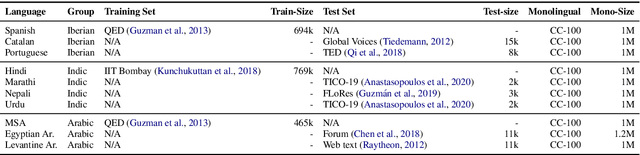
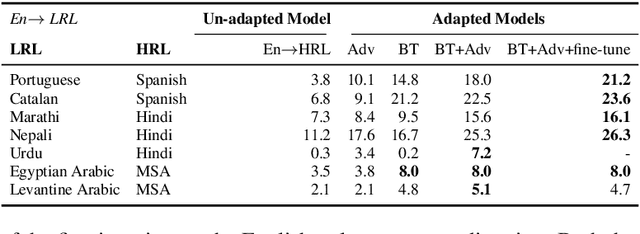
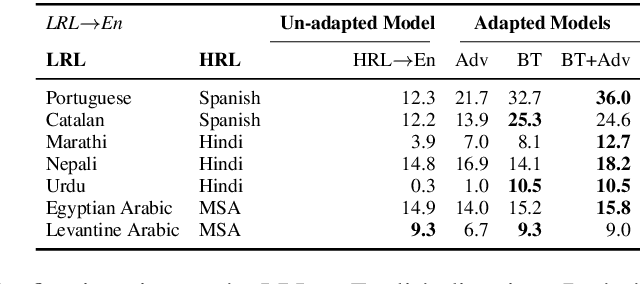
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
Generating Dialogue Responses from a Semantic Latent Space
Oct 04, 2020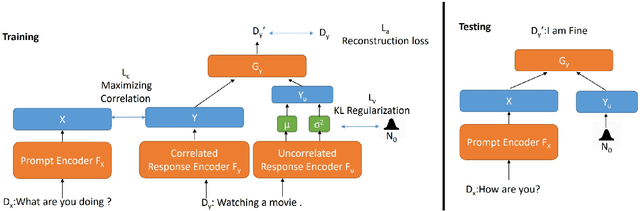
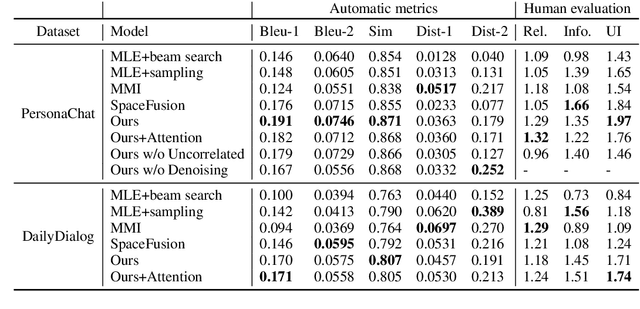
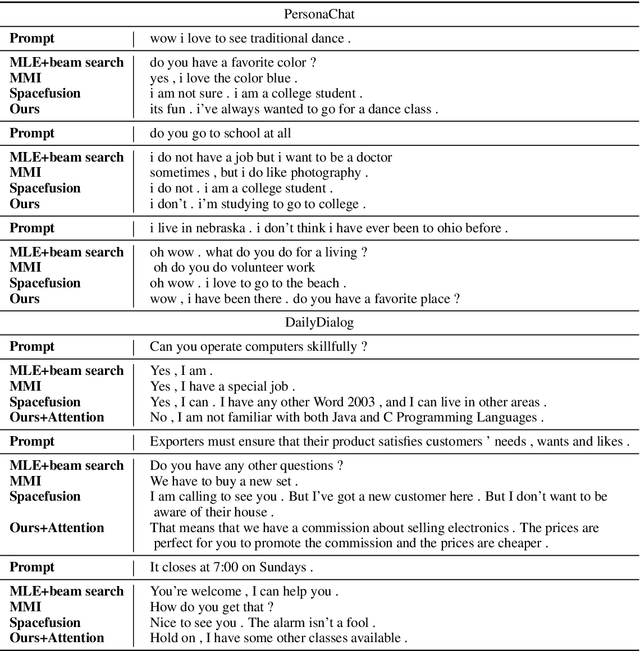
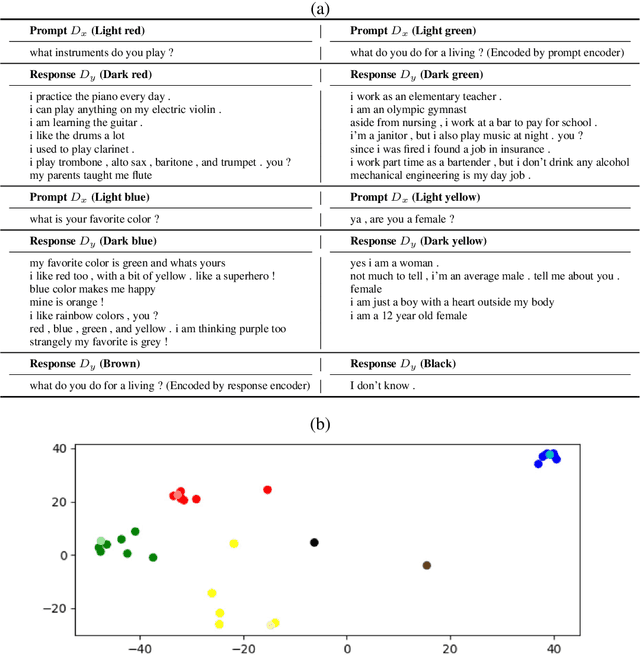
Existing open-domain dialogue generation models are usually trained to mimic the gold response in the training set using cross-entropy loss on the vocabulary. However, a good response does not need to resemble the gold response, since there are multiple possible responses to a given prompt. In this work, we hypothesize that the current models are unable to integrate information from multiple semantically similar valid responses of a prompt, resulting in the generation of generic and uninformative responses. To address this issue, we propose an alternative to the end-to-end classification on vocabulary. We learn the pair relationship between the prompts and responses as a regression task on a latent space instead. In our novel dialog generation model, the representations of semantically related sentences are close to each other on the latent space. Human evaluation showed that learning the task on a continuous space can generate responses that are both relevant and informative.
Inquisitive Question Generation for High Level Text Comprehension
Oct 04, 2020

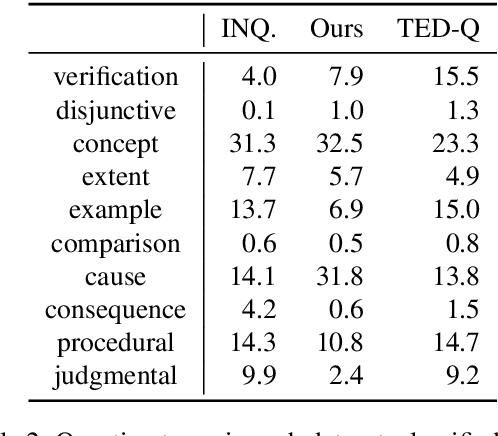
Inquisitive probing questions come naturally to humans in a variety of settings, but is a challenging task for automatic systems. One natural type of question to ask tries to fill a gap in knowledge during text comprehension, like reading a news article: we might ask about background information, deeper reasons behind things occurring, or more. Despite recent progress with data-driven approaches, generating such questions is beyond the range of models trained on existing datasets. We introduce INQUISITIVE, a dataset of ~19K questions that are elicited while a person is reading through a document. Compared to existing datasets, INQUISITIVE questions target more towards high-level (semantic and discourse) comprehension of text. We show that readers engage in a series of pragmatic strategies to seek information. Finally, we evaluate question generation models based on GPT-2 and show that our model is able to generate reasonable questions although the task is challenging, and highlight the importance of context to generate INQUISITIVE questions.
Assessing Discourse Relations in Language Generation from Pre-trained Language Models
Apr 28, 2020
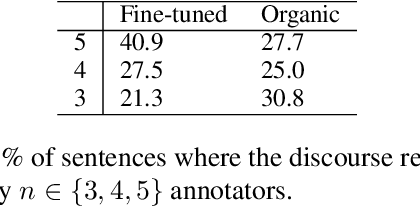
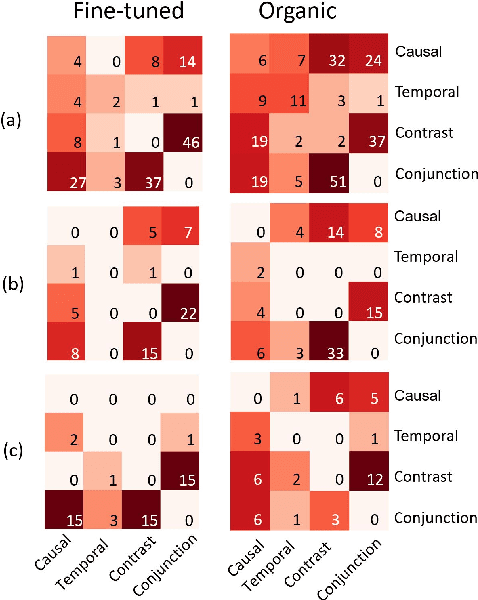
Recent advances in NLP have been attributed to the emergence of large-scale pre-trained language models. GPT-2, in particular, is suited for generation tasks given its left-to-right language modeling objective, yet the linguistic quality of its generated text has largely remain unexplored. Our work takes a step in understanding GPT-2's outputs in terms of discourse coherence. We perform a comprehensive study on the validity of explicit discourse relations in GPT-2's outputs under both organic generation and fine-tuned scenarios. Results show GPT-2 does not always generate text containing valid discourse relations; nevertheless, its text is more aligned with human expectation in the fine-tuned scenario. We propose a decoupled strategy to mitigate these problems and highlight the importance of explicitly modeling discourse information.
Domain Agnostic Real-Valued Specificity Prediction
Nov 14, 2018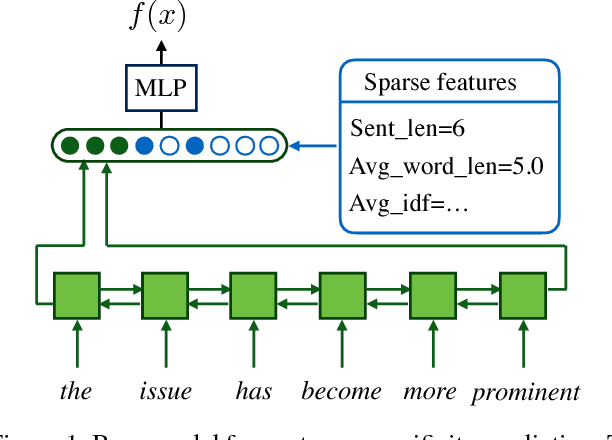
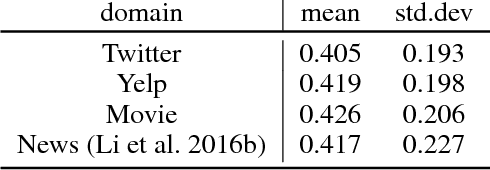

Sentence specificity quantifies the level of detail in a sentence, characterizing the organization of information in discourse. While this information is useful for many downstream applications, specificity prediction systems predict very coarse labels (binary or ternary) and are trained on and tailored toward specific domains (e.g., news). The goal of this work is to generalize specificity prediction to domains where no labeled data is available and output more nuanced real-valued specificity ratings. We present an unsupervised domain adaptation system for sentence specificity prediction, specifically designed to output real-valued estimates from binary training labels. To calibrate the values of these predictions appropriately, we regularize the posterior distribution of the labels towards a reference distribution. We show that our framework generalizes well to three different domains with 50%~68% mean absolute error reduction than the current state-of-the-art system trained for news sentence specificity. We also demonstrate the potential of our work in improving the quality and informativeness of dialogue generation systems.
* AAAI 2019 camera ready
Learning Deep Latent Spaces for Multi-Label Classification
Jul 03, 2017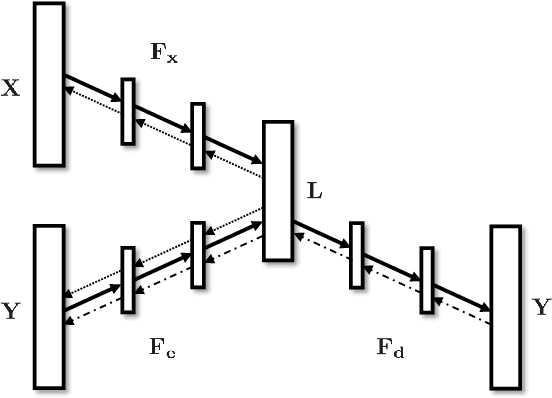
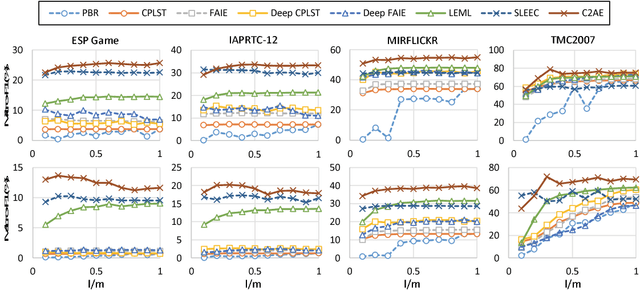
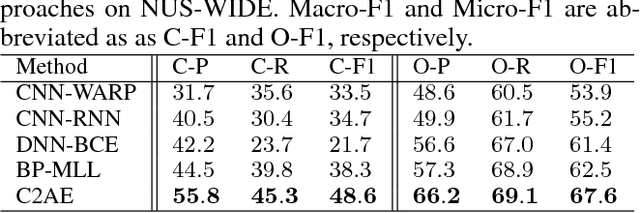
Multi-label classification is a practical yet challenging task in machine learning related fields, since it requires the prediction of more than one label category for each input instance. We propose a novel deep neural networks (DNN) based model, Canonical Correlated AutoEncoder (C2AE), for solving this task. Aiming at better relating feature and label domain data for improved classification, we uniquely perform joint feature and label embedding by deriving a deep latent space, followed by the introduction of label-correlation sensitive loss function for recovering the predicted label outputs. Our C2AE is achieved by integrating the DNN architectures of canonical correlation analysis and autoencoder, which allows end-to-end learning and prediction with the ability to exploit label dependency. Moreover, our C2AE can be easily extended to address the learning problem with missing labels. Our experiments on multiple datasets with different scales confirm the effectiveness and robustness of our proposed method, which is shown to perform favorably against state-of-the-art methods for multi-label classification.