 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Analysis via Questions and Answers: Parsing Dependency Structures of Questions Under Discussion
Oct 12, 2022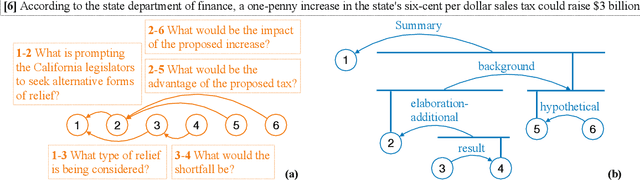

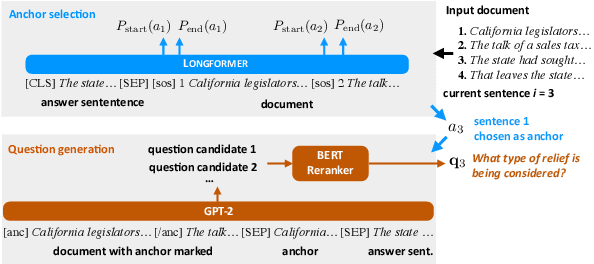
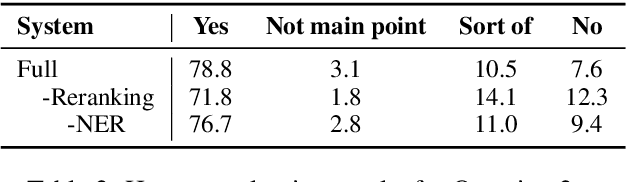
Automatic discourse processing, which can help understand how sentences connect to each other, is bottlenecked by data: current discourse formalisms pose highly demanding annotation tasks involving large taxonomies of discourse relations, making them inaccessible to lay annotators. This work instead adopts the linguistic framework of Questions Under Discussion (QUD) for discourse analysis and seeks to derive QUD structures automatically. QUD views each sentence as an answer to a question triggered in prior context; thus, we characterize relationships between sentences as free-form questions, in contrast to exhaustive fine-grained taxonomies. We develop the first-of-its-kind QUD parser that derives a dependency structure of questions over full documents, trained using a large question-answering dataset DCQA annotated in a manner consistent with the QUD framework. Importantly, data collection is easily crowdsourced using DCQA's paradigm. We show that this leads to a parser attaining strong performance according to human evaluation. We illustrate how our QUD structure is distinct from RST trees, and demonstrate the utility of QUD analysis in the context of document simplification. Our findings show that QUD parsing is an appealing alternative for automatic discourse processing.
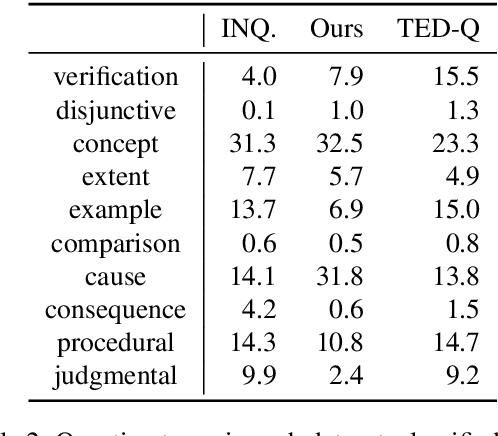
Discourse Comprehension: A Question Answering Framework to Represent Sentence Connections
Nov 01, 2021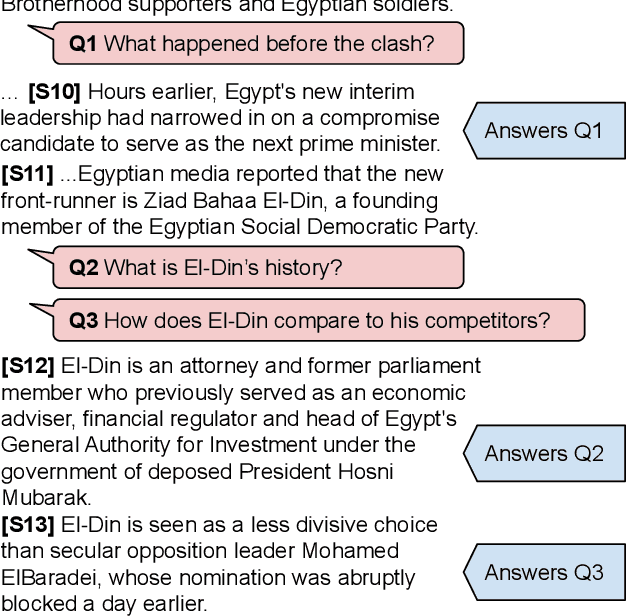


While there has been substantial progress in text comprehension through simple factoid question answering, more holistic comprehension of a discourse still presents a major challenge. Someone critically reflecting on a text as they read it will pose curiosity-driven, often open-ended questions, which reflect deep understanding of the content and require complex reasoning to answer. A key challenge in building and evaluating models for this type of discourse comprehension is the lack of annotated data, especially since finding answers to such questions (which may not be answered at all) requires high cognitive load for annotators over long documents. This paper presents a novel paradigm that enables scalable data collection targeting the comprehension of news documents, viewing these questions through the lens of discourse. The resulting corpus, DCQA (Discourse Comprehension by Question Answering), consists of 22,430 question-answer pairs across 607 English documents. DCQA captures both discourse and semantic links between sentences in the form of free-form, open-ended questions. On an evaluation set that we annotated on questions from the INQUISITIVE dataset, we show that DCQA provides valuable supervision for answering open-ended questions. We additionally design pre-training methods utilizing existing question-answering resources, and use synthetic data to accommodate unanswerable questions.