 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Comprehension: A Question Answering Framework to Represent Sentence Connections
Nov 01, 2021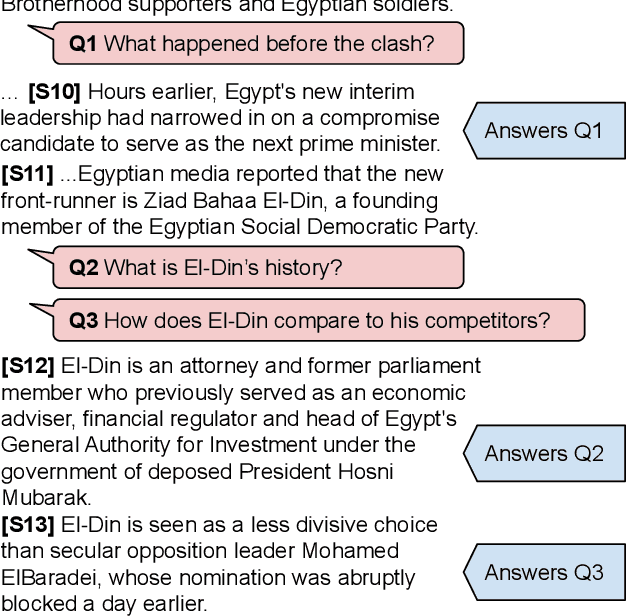


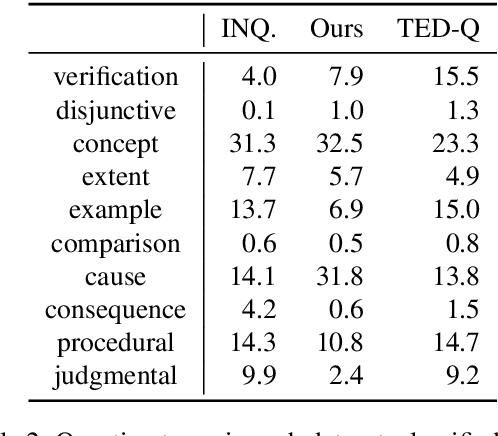
While there has been substantial progress in text comprehension through simple factoid question answering, more holistic comprehension of a discourse still presents a major challenge. Someone critically reflecting on a text as they read it will pose curiosity-driven, often open-ended questions, which reflect deep understanding of the content and require complex reasoning to answer. A key challenge in building and evaluating models for this type of discourse comprehension is the lack of annotated data, especially since finding answers to such questions (which may not be answered at all) requires high cognitive load for annotators over long documents. This paper presents a novel paradigm that enables scalable data collection targeting the comprehension of news documents, viewing these questions through the lens of discourse. The resulting corpus, DCQA (Discourse Comprehension by Question Answering), consists of 22,430 question-answer pairs across 607 English documents. DCQA captures both discourse and semantic links between sentences in the form of free-form, open-ended questions. On an evaluation set that we annotated on questions from the INQUISITIVE dataset, we show that DCQA provides valuable supervision for answering open-ended questions. We additionally design pre-training methods utilizing existing question-answering resources, and use synthetic data to accommodate unanswerable questions.