 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization in Spoken Language Understanding
Dec 25, 2023



State-of-the-art spoken language understanding (SLU) models have shown tremendous success in benchmark SLU datasets, yet they still fail in many practical scenario due to the lack of model compositionality when trained on limited training data. In this paper, we study two types of compositionality: (a) novel slot combination, and (b) length generalization. We first conduct in-depth analysis, and find that state-of-the-art SLU models often learn spurious slot correlations during training, which leads to poor performance in both compositional cases. To mitigate these limitations, we create the first compositional splits of benchmark SLU datasets and we propose the first compositional SLU model, including compositional loss and paired training that tackle each compositional case respectively. On both benchmark and compositional splits in ATIS and SNIPS, we show that our compositional SLU model significantly outperforms (up to $5\%$ F1 score) state-of-the-art BERT SLU model.
* Published in INTERSPEECH 2023
Contextual Data Augmentation for Task-Oriented Dialog Systems
Oct 16, 2023Collection of annotated dialogs for training task-oriented dialog systems have been one of the key bottlenecks in improving current models. While dialog response generation has been widely studied on the agent side, it is not evident if similar generative models can be used to generate a large variety of, and often unexpected, user inputs that real dialog systems encounter in practice. Existing data augmentation techniques such as paraphrase generation do not take the dialog context into consideration. In this paper, we develop a novel dialog augmentation model that generates a user turn, conditioning on full dialog context. Additionally, with a new prompt design for language model, and output re-ranking, the dialogs generated from our model can be directly used to train downstream dialog systems. On common benchmark datasets MultiWoZ and SGD, we show that our dialog augmentation model generates high quality dialogs and improves dialog success rate by as much as $8\%$ over baseline.
Code-Switched Text Synthesis in Unseen Language Pairs
May 26, 2023Existing efforts on text synthesis for code-switching mostly require training on code-switched texts in the target language pairs, limiting the deployment of the models to cases lacking code-switched data. In this work, we study the problem of synthesizing code-switched texts for language pairs absent from the training data. We introduce GLOSS, a model built on top of a pre-trained multilingual machine translation model (PMMTM) with an additional code-switching module. This module, either an adapter or extra prefixes, learns code-switching patterns from code-switched data during training, while the primary component of GLOSS, i.e., the PMMTM, is frozen. The design of only adjusting the code-switching module prevents our model from overfitting to the constrained training data for code-switching. Hence, GLOSS exhibits the ability to generalize and synthesize code-switched texts across a broader spectrum of language pairs. Additionally, we develop a self-training algorithm on target language pairs further to enhance the reliability of GLOSS. Automatic evaluations on four language pairs show that GLOSS achieves at least 55% relative BLEU and METEOR scores improvements compared to strong baselines. Human evaluations on two language pairs further validate the success of GLOSS.
Enhancing the Generalization for Intent Classification and Out-of-Domain Detection in SLU
Jun 28, 2021

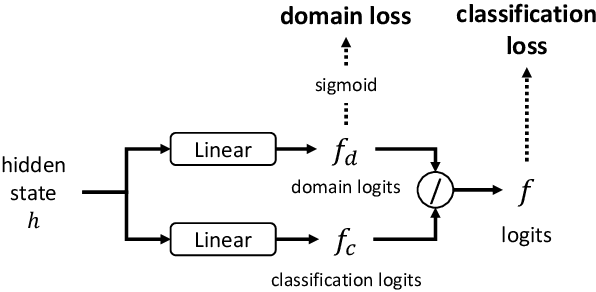

Intent classification is a major task in spoken language understanding (SLU). Since most models are built with pre-collected in-domain (IND) training utterances, their ability to detect unsupported out-of-domain (OOD) utterances has a critical effect in practical use. Recent works have shown that using extra data and labels can improve the OOD detection performance, yet it could be costly to collect such data. This paper proposes to train a model with only IND data while supporting both IND intent classification and OOD detection. Our method designs a novel domain-regularized module (DRM) to reduce the overconfident phenomenon of a vanilla classifier, achieving a better generalization in both cases. Besides, DRM can be used as a drop-in replacement for the last layer in any neural network-based intent classifier, providing a low-cost strategy for a significant improvement. The evaluation on four datasets shows that our method built on BERT and RoBERTa models achieves state-of-the-art performance against existing approaches and the strong baselines we created for the comparisons.
Generating Dialogue Responses from a Semantic Latent Space
Oct 04, 2020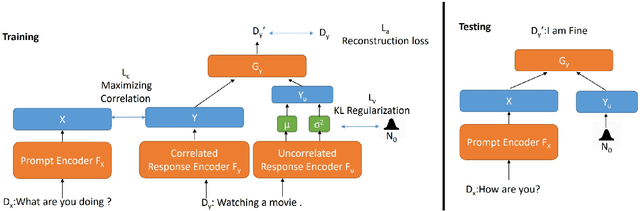
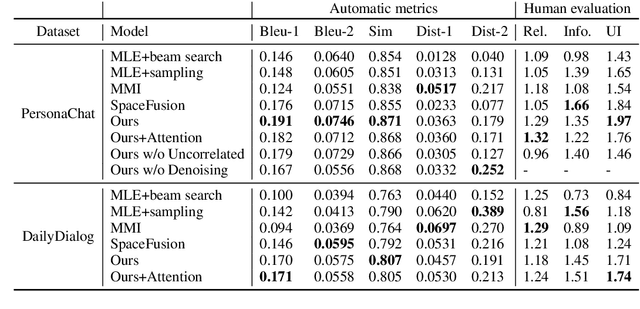
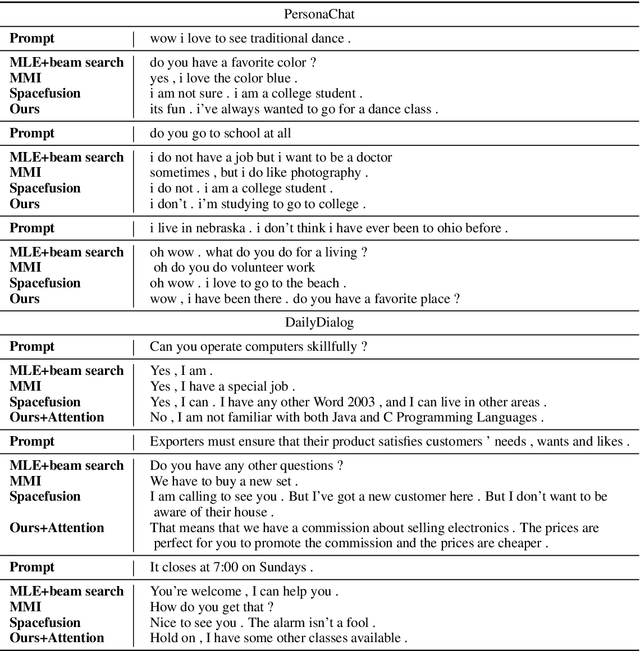
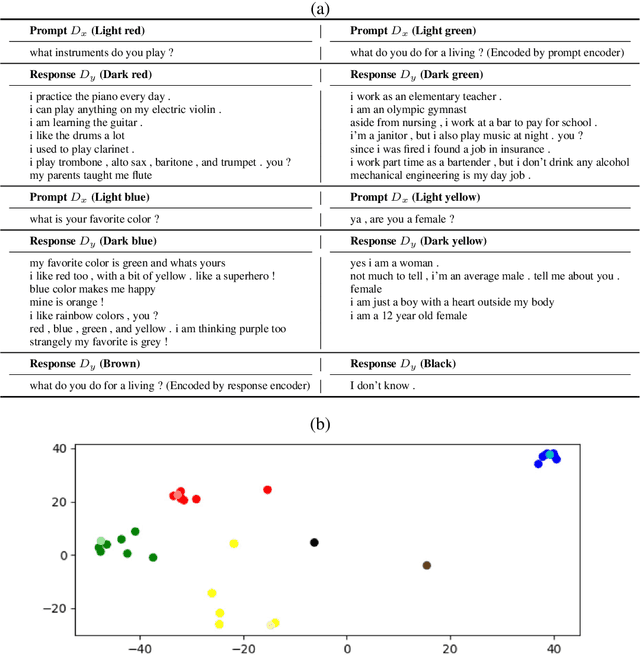
Existing open-domain dialogue generation models are usually trained to mimic the gold response in the training set using cross-entropy loss on the vocabulary. However, a good response does not need to resemble the gold response, since there are multiple possible responses to a given prompt. In this work, we hypothesize that the current models are unable to integrate information from multiple semantically similar valid responses of a prompt, resulting in the generation of generic and uninformative responses. To address this issue, we propose an alternative to the end-to-end classification on vocabulary. We learn the pair relationship between the prompts and responses as a regression task on a latent space instead. In our novel dialog generation model, the representations of semantically related sentences are close to each other on the latent space. Human evaluation showed that learning the task on a continuous space can generate responses that are both relevant and informative.
Iterative Delexicalization for Improved Spoken Language Understanding
Oct 15, 2019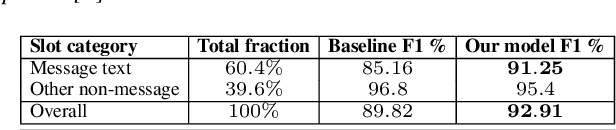

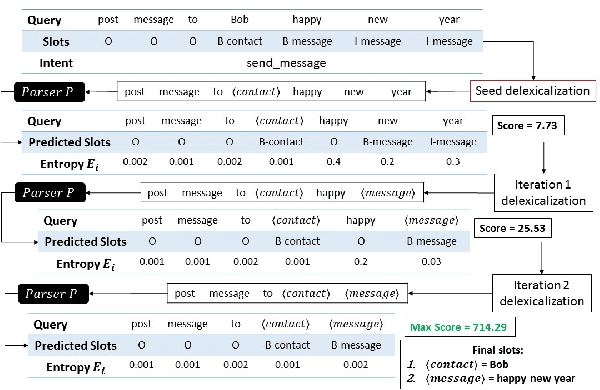

Recurrent neural network (RNN) based joint intent classification and slot tagging models have achieved tremendous success in recent years for building spoken language understanding and dialog systems. However, these models suffer from poor performance for slots which often encounter large semantic variability in slot values after deployment (e.g. message texts, partial movie/artist names). While greedy delexicalization of slots in the input utterance via substring matching can partly improve performance, it often produces incorrect input. Moreover, such techniques cannot delexicalize slots with out-of-vocabulary slot values not seen at training. In this paper, we propose a novel iterative delexicalization algorithm, which can accurately delexicalize the input, even with out-of-vocabulary slot values. Based on model confidence of the current delexicalized input, our algorithm improves delexicalization in every iteration to converge to the best input having the highest confidence. We show on benchmark and in-house datasets that our algorithm can greatly improve parsing performance for RNN based models, especially for out-of-distribution slot values.
* Published at INTERSPEECH 2019, Graz, Austria
Robust Spoken Language Understanding via Paraphrasing
Sep 17, 2018


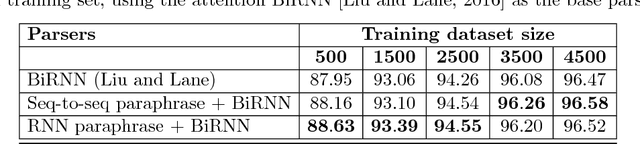
Learning intents and slot labels from user utterances is a fundamental step in all spoken language understanding (SLU) and dialog systems. State-of-the-art neural network based methods, after deployment, often suffer from performance degradation on encountering paraphrased utterances, and out-of-vocabulary words, rarely observed in their training set. We address this challenging problem by introducing a novel paraphrasing based SLU model which can be integrated with any existing SLU model in order to improve their overall performance. We propose two new paraphrase generators using RNN and sequence-to-sequence based neural networks, which are suitable for our application. Our experiments on existing benchmark and in house datasets demonstrate the robustness of our models to rare and complex paraphrased utterances, even under adversarial test distributions.
Searching for a Single Community in a Graph
May 24, 2018



In standard graph clustering/community detection, one is interested in partitioning the graph into more densely connected subsets of nodes. In contrast, the "search" problem of this paper aims to only find the nodes in a "single" such community, the target, out of the many communities that may exist. To do so , we are given suitable side information about the target; for example, a very small number of nodes from the target are labeled as such. We consider a general yet simple notion of side information: all nodes are assumed to have random weights, with nodes in the target having higher weights on average. Given these weights and the graph, we develop a variant of the method of moments that identifies nodes in the target more reliably, and with lower computation, than generic community detection methods that do not use side information and partition the entire graph. Our empirical results show significant gains in runtime, and also gains in accuracy over other graph clustering algorithms.
The Search Problem in Mixture Models
Feb 24, 2018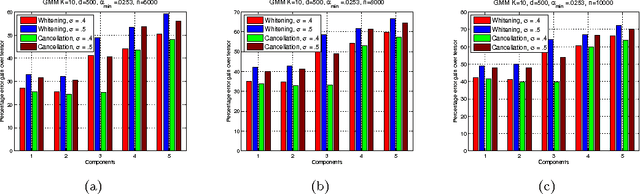

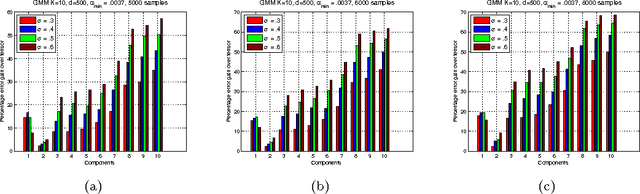
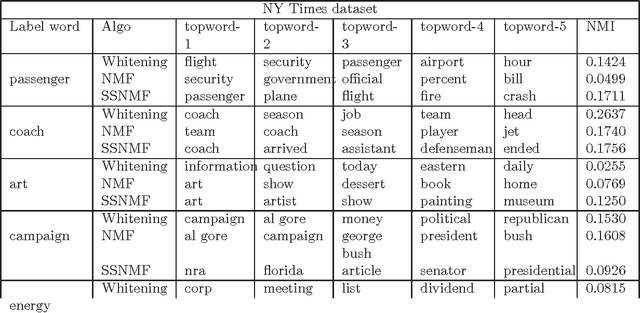
We consider the task of learning the parameters of a {\em single} component of a mixture model, for the case when we are given {\em side information} about that component, we call this the "search problem" in mixture models. We would like to solve this with computational and sample complexity lower than solving the overall original problem, where one learns parameters of all components. Our main contributions are the development of a simple but general model for the notion of side information, and a corresponding simple matrix-based algorithm for solving the search problem in this general setting. We then specialize this model and algorithm to four common scenarios: Gaussian mixture models, LDA topic models, subspace clustering, and mixed linear regression. For each one of these we show that if (and only if) the side information is informative, we obtain parameter estimates with greater accuracy, and also improved computation complexity than existing moment based mixture model algorithms (e.g. tensor methods). We also illustrate several natural ways one can obtain such side information, for specific problem instances. Our experiments on real data sets (NY Times, Yelp, BSDS500) further demonstrate the practicality of our algorithms showing significant improvement in runtime and accuracy.