 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Discourse Relations in Language Generation from Pre-trained Language Models
Paper and Code
Apr 28, 2020
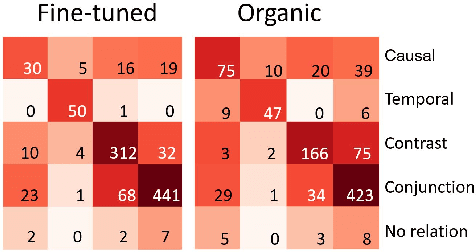
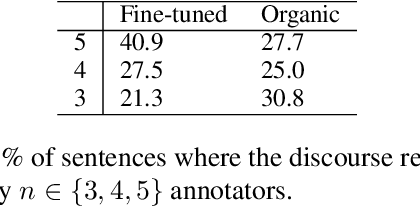
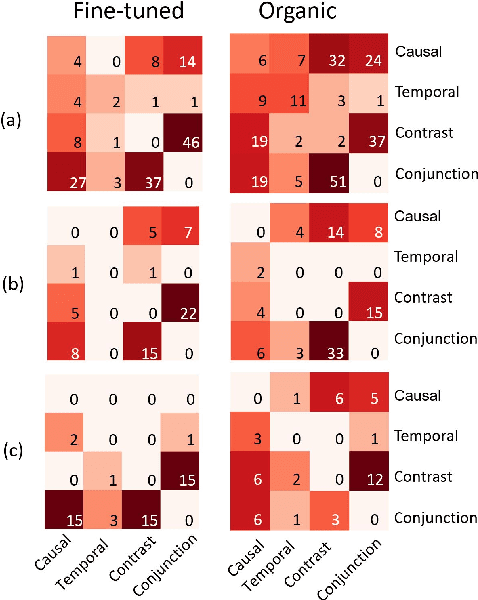
Recent advances in NLP have been attributed to the emergence of large-scale pre-trained language models. GPT-2, in particular, is suited for generation tasks given its left-to-right language modeling objective, yet the linguistic quality of its generated text has largely remain unexplored. Our work takes a step in understanding GPT-2's outputs in terms of discourse coherence. We perform a comprehensive study on the validity of explicit discourse relations in GPT-2's outputs under both organic generation and fine-tuned scenarios. Results show GPT-2 does not always generate text containing valid discourse relations; nevertheless, its text is more aligned with human expectation in the fine-tuned scenario. We propose a decoupled strategy to mitigate these problems and highlight the importance of explicitly modeling discourse information.