 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Domain Adaptation of Language Models using Modular Experts
Oct 14, 2024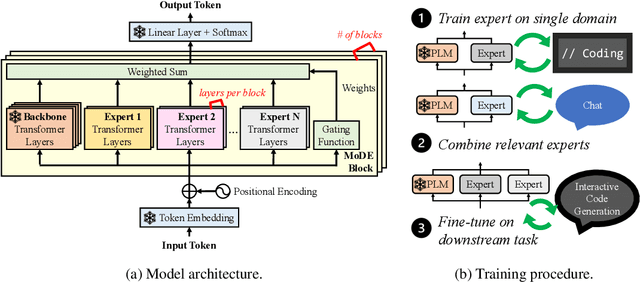
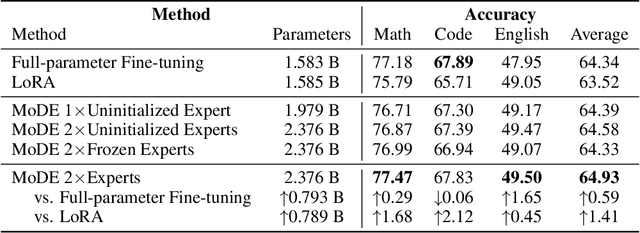
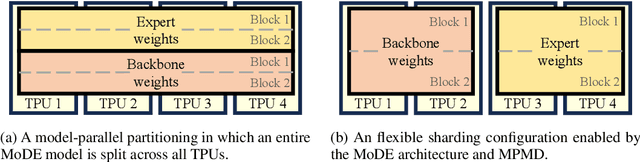
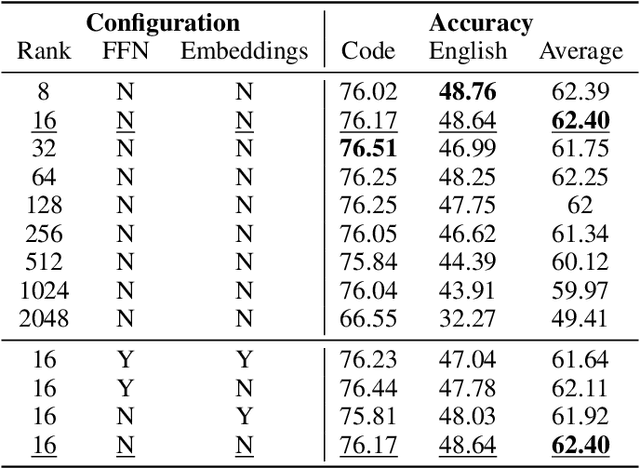
Domain-specific adaptation is critical to maximizing the performance of pre-trained language models (PLMs) on one or multiple targeted tasks, especially under resource-constrained use cases, such as edge devices. However, existing methods often struggle to balance domain-specific performance, retention of general knowledge, and efficiency for training and inference. To address these challenges, we propose Modular Domain Experts (MoDE). MoDE is a mixture-of-experts architecture that augments a general PLMs with modular, domain-specialized experts. These experts are trained independently and composed together via a lightweight training process. In contrast to standard low-rank adaptation methods, each MoDE expert consists of several transformer layers which scale better with more training examples and larger parameter counts. Our evaluation demonstrates that MoDE achieves comparable target performances to full parameter fine-tuning while achieving 1.65% better retention performance. Moreover, MoDE's architecture enables flexible sharding configurations and improves training speeds by up to 38% over state-of-the-art distributed training configurations.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Which Pretrain Samples to Rehearse when Finetuning Pretrained Models?
Feb 12, 2024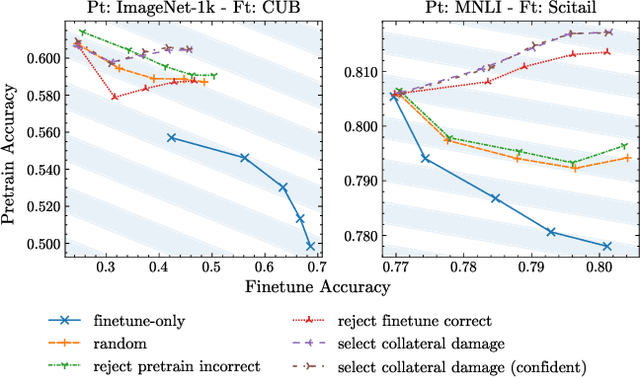
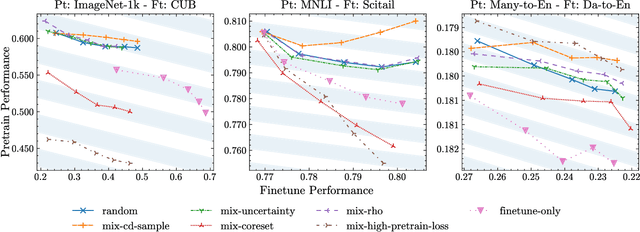
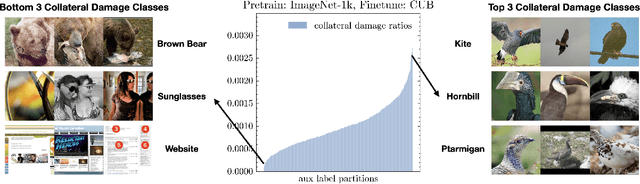
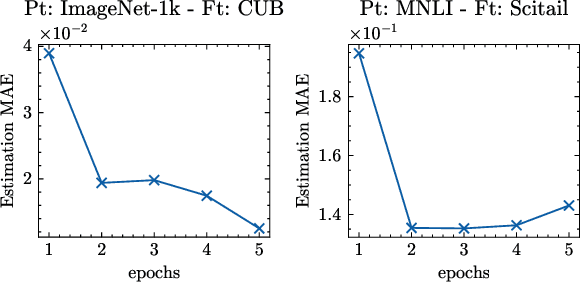
Fine-tuning pretrained foundational models on specific tasks is now the de facto approach for text and vision tasks. A known pitfall of this approach is the forgetting of pretraining knowledge that happens during finetuning. Rehearsing samples randomly from the pretrain dataset is a common approach to alleviate such forgetting. However, we find that random mixing unintentionally includes samples which are not (yet) forgotten or unlearnable by the model. We propose a novel sampling scheme, mix-cd, that identifies and prioritizes samples that actually face forgetting, which we call collateral damage. Since directly identifying collateral damage samples is computationally expensive, we propose a procedure to estimate the distribution of such samples by tracking the statistics of finetuned samples. Our approach is lightweight, easy to implement, and can be seamlessly integrated into existing models, offering an effective means to retain pretrain performance without additional computational costs.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Order Matters in the Presence of Dataset Imbalance for Multilingual Learning
Dec 11, 2023In this paper, we empirically study the optimization dynamics of multi-task learning, particularly focusing on those that govern a collection of tasks with significant data imbalance. We present a simple yet effective method of pre-training on high-resource tasks, followed by fine-tuning on a mixture of high/low-resource tasks. We provide a thorough empirical study and analysis of this method's benefits showing that it achieves consistent improvements relative to the performance trade-off profile of standard static weighting. We analyze under what data regimes this method is applicable and show its improvements empirically in neural machine translation (NMT) and multi-lingual language modeling.
Sample based Explanations via Generalized Representers
Oct 27, 2023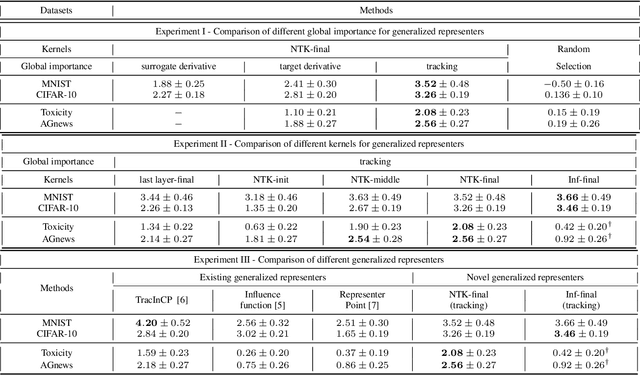
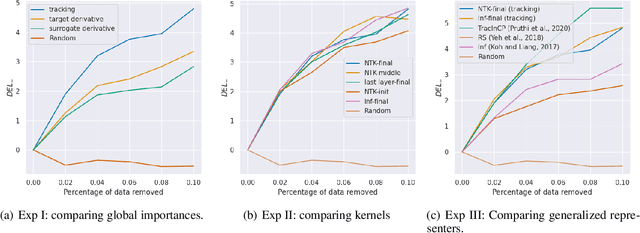
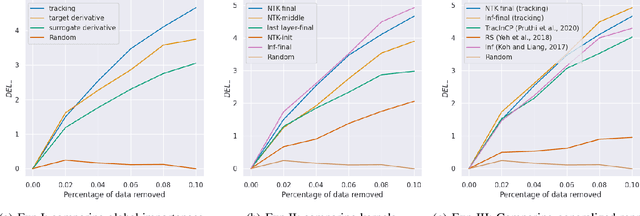
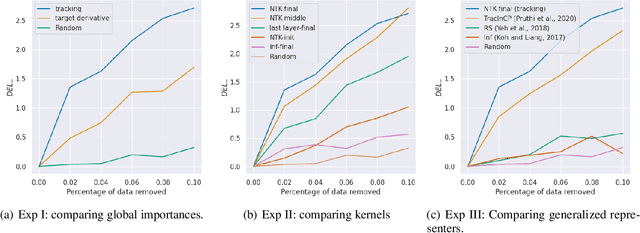
We propose a general class of sample based explanations of machine learning models, which we term generalized representers. To measure the effect of a training sample on a model's test prediction, generalized representers use two components: a global sample importance that quantifies the importance of the training point to the model and is invariant to test samples, and a local sample importance that measures similarity between the training sample and the test point with a kernel. A key contribution of the paper is to show that generalized representers are the only class of sample based explanations satisfying a natural set of axiomatic properties. We discuss approaches to extract global importances given a kernel, and also natural choices of kernels given modern non-linear models. As we show, many popular existing sample based explanations could be cast as generalized representers with particular choices of kernels and approaches to extract global importances. Additionally, we conduct empirical comparisons of different generalized representers on two image and two text classification datasets.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
May 03, 2023
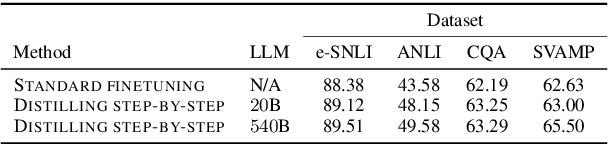
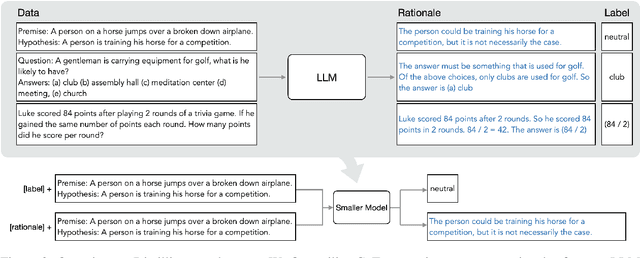

Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling using LLM-generated labels. However, finetuning and distillation require large amounts of training data to achieve comparable performance to LLMs. We introduce Distilling step-by-step, a new mechanism that (a) trains smaller models that outperform LLMs, and (b) achieves so by leveraging less training data needed by finetuning or distillation. Our method extracts LLM rationales as additional supervision for small models within a multi-task training framework. We present three findings across 4 NLP benchmarks: First, compared to both finetuning and distillation, our mechanism achieves better performance with much fewer labeled/unlabeled training examples. Second, compared to LLMs, we achieve better performance using substantially smaller model sizes. Third, we reduce both the model size and the amount of data required to outperform LLMs; our 770M T5 model outperforms the 540B PaLM model using only 80% of available data on a benchmark task.
Concept Gradient: Concept-based Interpretation Without Linear Assumption
Aug 31, 2022
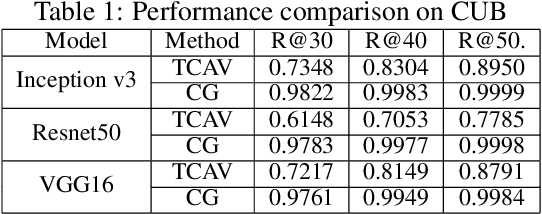
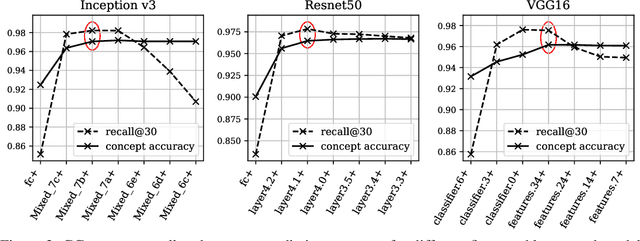
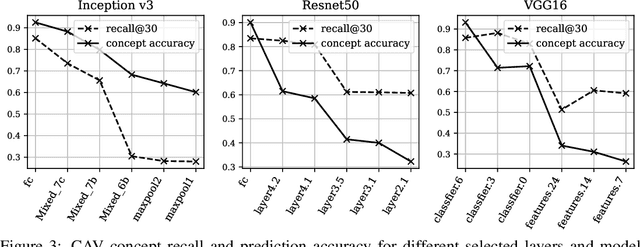
Concept-based interpretations of black-box models are often more intuitive for humans to understand. The most widely adopted approach for concept-based interpretation is Concept Activation Vector (CAV). CAV relies on learning a linear relation between some latent representation of a given model and concepts. The linear separability is usually implicitly assumed but does not hold true in general. In this work, we started from the original intent of concept-based interpretation and proposed Concept Gradient (CG), extending concept-based interpretation beyond linear concept functions. We showed that for a general (potentially non-linear) concept, we can mathematically evaluate how a small change of concept affecting the model's prediction, which leads to an extension of gradient-based interpretation to the concept space. We demonstrated empirically that CG outperforms CAV in both toy examples and real world datasets.
Faith-Shap: The Faithful Shapley Interaction Index
Mar 09, 2022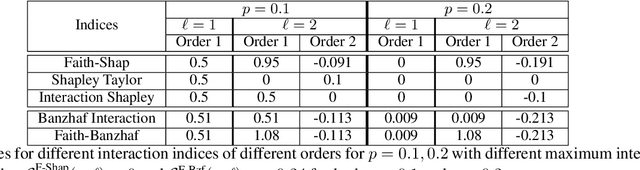
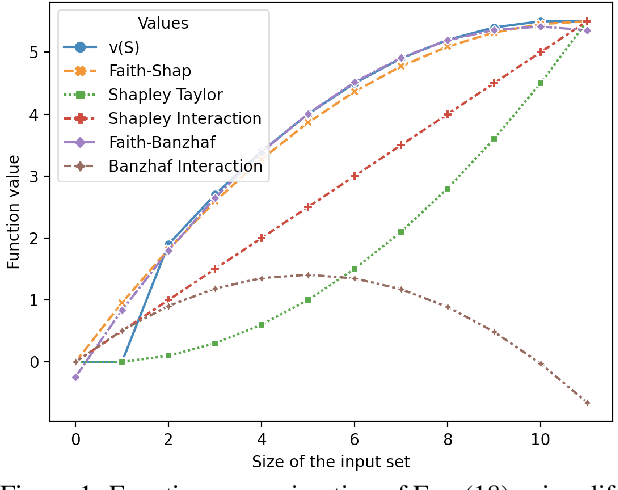
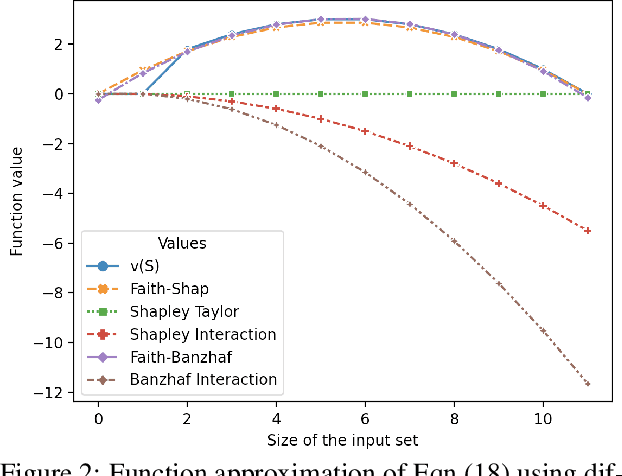
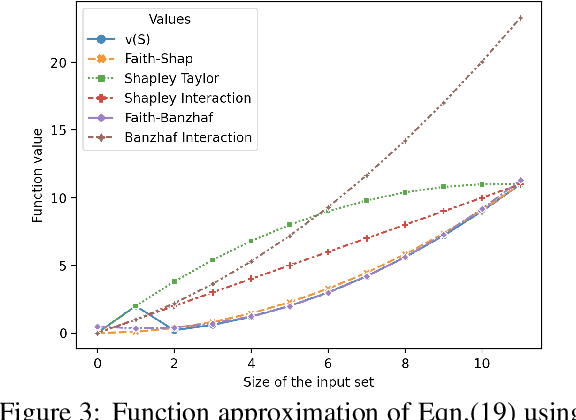
Shapley values, which were originally designed to assign attributions to individual players in coalition games, have become a commonly used approach in explainable machine learning to provide attributions to input features for black-box machine learning models. A key attraction of Shapley values is that they uniquely satisfy a very natural set of axiomatic properties. However, extending the Shapley value to assigning attributions to interactions rather than individual players, an interaction index, is non-trivial: as the natural set of axioms for the original Shapley values, extended to the context of interactions, no longer specify a unique interaction index. Many proposals thus introduce additional less "natural" axioms, while sacrificing the key axiom of efficiency, in order to obtain unique interaction indices. In this work, rather than introduce additional conflicting axioms, we adopt the viewpoint of Shapley values as coefficients of the most faithful linear approximation to the pseudo-Boolean coalition game value function. By extending linear to $\ell$-order polynomial approximations, we can then define the general family of faithful interaction indices}. We show that by additionally requiring the faithful interaction indices to satisfy interaction-extensions of the standard individual Shapley axioms (dummy, symmetry, linearity, and efficiency), we obtain a unique FaithfulShapley Interaction index, which we denote Faith-Shap, as a natural generalization of the Shapley value to interactions. We then provide some illustrative contrasts of Faith-Shap with previously proposed interaction indices, and further investigate some of its interesting algebraic properties. We further show the computational efficiency of computing Faith-Shap, together with some additional qualitative insights, via some illustrative experiments.
Human-Centered Concept Explanations for Neural Networks
Feb 25, 2022
Understanding complex machine learning models such as deep neural networks with explanations is crucial in various applications. Many explanations stem from the model perspective, and may not necessarily effectively communicate why the model is making its predictions at the right level of abstraction. For example, providing importance weights to individual pixels in an image can only express which parts of that particular image are important to the model, but humans may prefer an explanation which explains the prediction by concept-based thinking. In this work, we review the emerging area of concept based explanations. We start by introducing concept explanations including the class of Concept Activation Vectors (CAV) which characterize concepts using vectors in appropriate spaces of neural activations, and discuss different properties of useful concepts, and approaches to measure the usefulness of concept vectors. We then discuss approaches to automatically extract concepts, and approaches to address some of their caveats. Finally, we discuss some case studies that showcase the utility of such concept-based explanations in synthetic settings and real world applications.