 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagFormer: Time Staggering Transformer Decoding for RunningLayers In Parallel
Jan 26, 2025Standard decoding in a Transformer based language model is inherently sequential as we wait for a token's embedding to pass through all the layers in the network before starting the generation of the next token. In this work, we propose a new architecture StagFormer (Staggered Transformer), which staggered execution along the time axis and thereby enables parallelizing the decoding process along the depth of the model. We achieve this by breaking the dependency of the token representation at time step $i$ in layer $l$ upon the representations of tokens until time step $i$ from layer $l-1$. Instead, we stagger the execution and only allow a dependency on token representations until time step $i-1$. The later sections of the Transformer still get access to the ``rich" representations from the prior section but only from those token positions which are one time step behind. StagFormer allows for different sections of the model to be executed in parallel yielding at potential 33\% speedup in decoding while being quality neutral in our simulations. We also explore many natural variants of this idea. We present how weight-sharing across the different sections being staggered can be more practical in settings with limited memory. We show how one can approximate a recurrent model during inference using such weight-sharing. We explore the efficacy of using a bounded window attention to pass information from one section to another which helps drive further latency gains for some applications. We also explore demonstrate the scalability of the staggering idea over more than 2 sections of the Transformer.
Scalable Multi-Domain Adaptation of Language Models using Modular Experts
Oct 14, 2024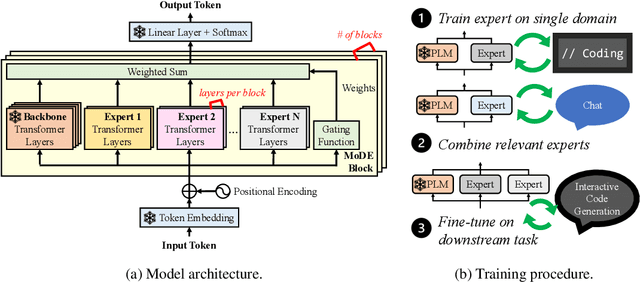
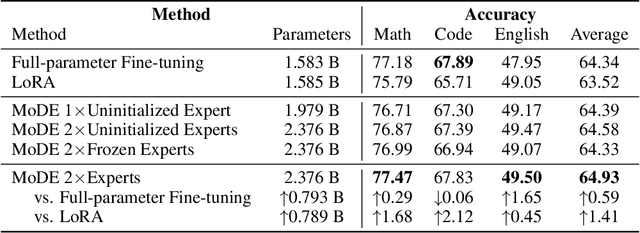
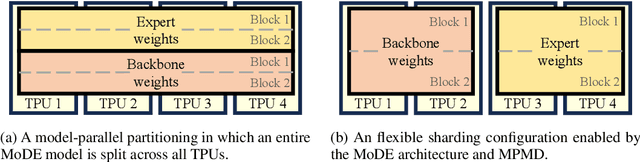
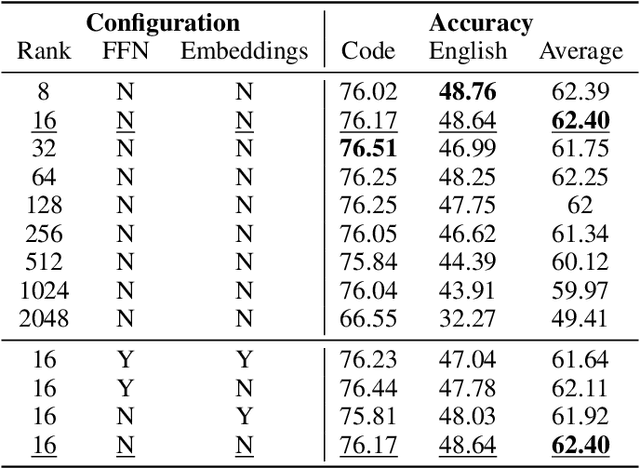
Domain-specific adaptation is critical to maximizing the performance of pre-trained language models (PLMs) on one or multiple targeted tasks, especially under resource-constrained use cases, such as edge devices. However, existing methods often struggle to balance domain-specific performance, retention of general knowledge, and efficiency for training and inference. To address these challenges, we propose Modular Domain Experts (MoDE). MoDE is a mixture-of-experts architecture that augments a general PLMs with modular, domain-specialized experts. These experts are trained independently and composed together via a lightweight training process. In contrast to standard low-rank adaptation methods, each MoDE expert consists of several transformer layers which scale better with more training examples and larger parameter counts. Our evaluation demonstrates that MoDE achieves comparable target performances to full parameter fine-tuning while achieving 1.65% better retention performance. Moreover, MoDE's architecture enables flexible sharding configurations and improves training speeds by up to 38% over state-of-the-art distributed training configurations.
Tiny Neural Models for Seq2Seq
Aug 07, 2021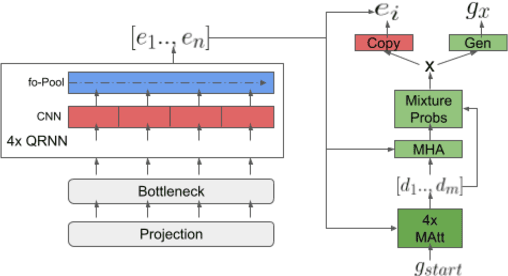
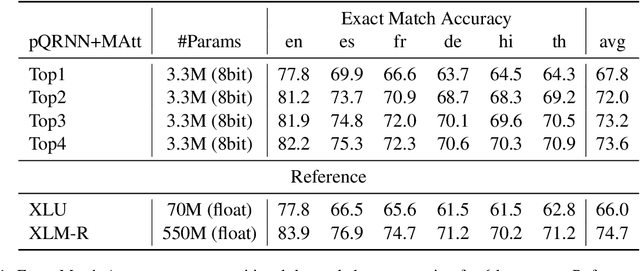
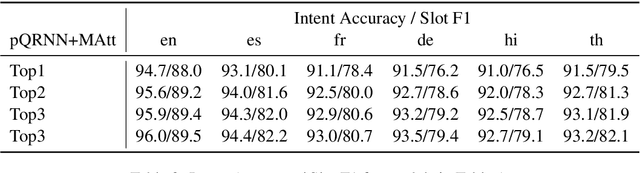
Semantic parsing models with applications in task oriented dialog systems require efficient sequence to sequence (seq2seq) architectures to be run on-device. To this end, we propose a projection based encoder-decoder model referred to as pQRNN-MAtt. Studies based on projection methods were restricted to encoder-only models, and we believe this is the first study extending it to seq2seq architectures. The resulting quantized models are less than 3.5MB in size and are well suited for on-device latency critical applications. We show that on MTOP, a challenging multilingual semantic parsing dataset, the average model performance surpasses LSTM based seq2seq model that uses pre-trained embeddings despite being 85x smaller. Furthermore, the model can be an effective student for distilling large pre-trained models such as T5/BERT.