 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartphone monitoring of smiling as a behavioral proxy of well-being in everyday life
Dec 10, 2025Subjective well-being is a cornerstone of individual and societal health, yet its scientific measurement has traditionally relied on self-report methods prone to recall bias and high participant burden. This has left a gap in our understanding of well-being as it is expressed in everyday life. We hypothesized that candid smiles captured during natural smartphone interactions could serve as a scalable, objective behavioral correlate of positive affect. To test this, we analyzed 405,448 video clips passively recorded from 233 consented participants over one week. Using a deep learning model to quantify smile intensity, we identified distinct diurnal and daily patterns. Daily patterns of smile intensity across the week showed strong correlation with national survey data on happiness (r=0.92), and diurnal rhythms documented close correspondence with established results from the day reconstruction method (r=0.80). Higher daily mean smile intensity was significantly associated with more physical activity (Beta coefficient = 0.043, 95% CI [0.001, 0.085]) and greater light exposure (Beta coefficient = 0.038, [0.013, 0.063]), whereas no significant effects were found for smartphone use. These findings suggest that passive smartphone sensing could serve as a powerful, ecologically valid methodology for studying the dynamics of affective behavior and open the door to understanding this behavior at a population scale.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Passive Heart Rate Monitoring During Smartphone Use in Everyday Life
Mar 04, 2025

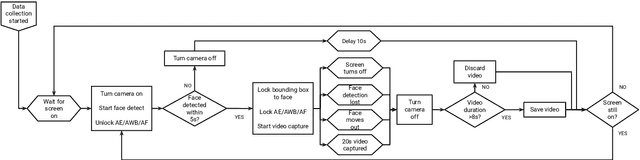

Resting heart rate (RHR) is an important biomarker of cardiovascular health and mortality, but tracking it longitudinally generally requires a wearable device, limiting its availability. We present PHRM, a deep learning system for passive heart rate (HR) and RHR measurements during everyday smartphone use, using facial video-based photoplethysmography. Our system was developed using 225,773 videos from 495 participants and validated on 185,970 videos from 205 participants in laboratory and free-living conditions, representing the largest validation study of its kind. Compared to reference electrocardiogram, PHRM achieved a mean absolute percentage error (MAPE) < 10% for HR measurements across three skin tone groups of light, medium and dark pigmentation; MAPE for each skin tone group was non-inferior versus the others. Daily RHR measured by PHRM had a mean absolute error < 5 bpm compared to a wearable HR tracker, and was associated with known risk factors. These results highlight the potential of smartphones to enable passive and equitable heart health monitoring.
Scaling Wearable Foundation Models
Oct 17, 2024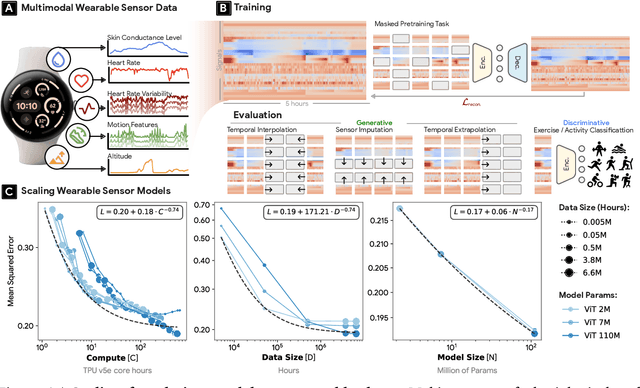
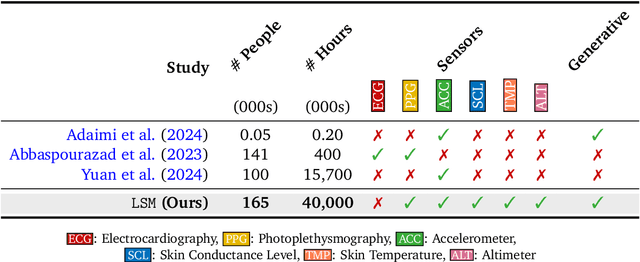


Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data; however, making sense of these observations for scientific and actionable insights is non-trivial. Inspired by the empirical success of generative modeling, where large neural networks learn powerful representations from vast amounts of text, image, video, or audio data, we investigate the scaling properties of sensor foundation models across compute, data, and model size. Using a dataset of up to 40 million hours of in-situ heart rate, heart rate variability, electrodermal activity, accelerometer, skin temperature, and altimeter per-minute data from over 165,000 people, we create LSM, a multimodal foundation model built on the largest wearable-signals dataset with the most extensive range of sensor modalities to date. Our results establish the scaling laws of LSM for tasks such as imputation, interpolation and extrapolation, both across time and sensor modalities. Moreover, we highlight how LSM enables sample-efficient downstream learning for tasks like exercise and activity recognition.
Scalable Multi-Domain Adaptation of Language Models using Modular Experts
Oct 14, 2024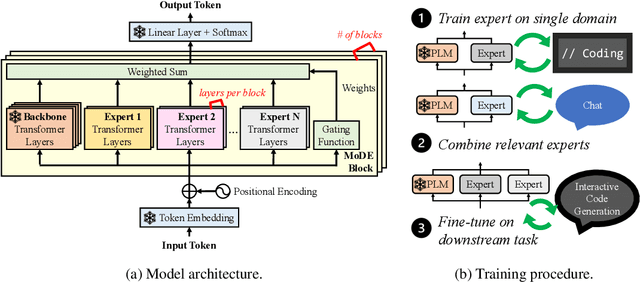
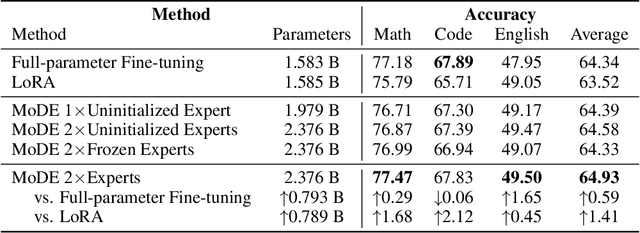
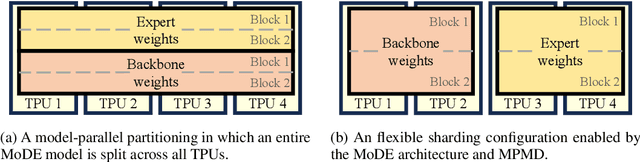
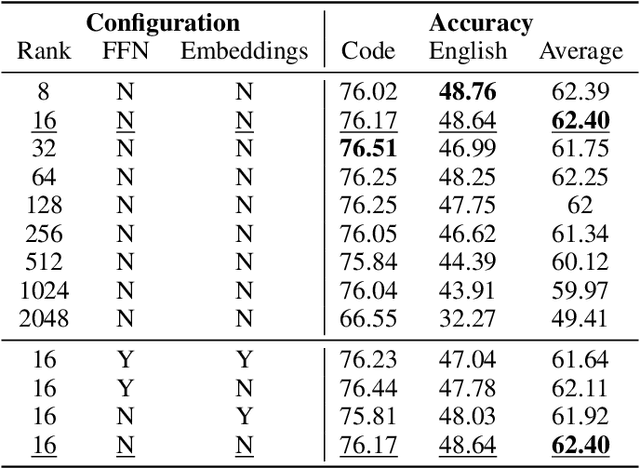
Domain-specific adaptation is critical to maximizing the performance of pre-trained language models (PLMs) on one or multiple targeted tasks, especially under resource-constrained use cases, such as edge devices. However, existing methods often struggle to balance domain-specific performance, retention of general knowledge, and efficiency for training and inference. To address these challenges, we propose Modular Domain Experts (MoDE). MoDE is a mixture-of-experts architecture that augments a general PLMs with modular, domain-specialized experts. These experts are trained independently and composed together via a lightweight training process. In contrast to standard low-rank adaptation methods, each MoDE expert consists of several transformer layers which scale better with more training examples and larger parameter counts. Our evaluation demonstrates that MoDE achieves comparable target performances to full parameter fine-tuning while achieving 1.65% better retention performance. Moreover, MoDE's architecture enables flexible sharding configurations and improves training speeds by up to 38% over state-of-the-art distributed training configurations.
What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
Jun 18, 2024



Language models (LM) are capable of remarkably complex linguistic tasks; however, numerical reasoning is an area in which they frequently struggle. An important but rarely evaluated form of reasoning is understanding probability distributions. In this paper, we focus on evaluating the probabilistic reasoning capabilities of LMs using idealized and real-world statistical distributions. We perform a systematic evaluation of state-of-the-art LMs on three tasks: estimating percentiles, drawing samples, and calculating probabilities. We evaluate three ways to provide context to LMs 1) anchoring examples from within a distribution or family of distributions, 2) real-world context, 3) summary statistics on which to base a Normal approximation. Models can make inferences about distributions, and can be further aided by the incorporation of real-world context, example shots and simplified assumptions, even if these assumptions are incorrect or misspecified. To conduct this work, we developed a comprehensive benchmark distribution dataset with associated question-answer pairs that we will release publicly.
Large Language Models are Few-Shot Health Learners
May 24, 2023
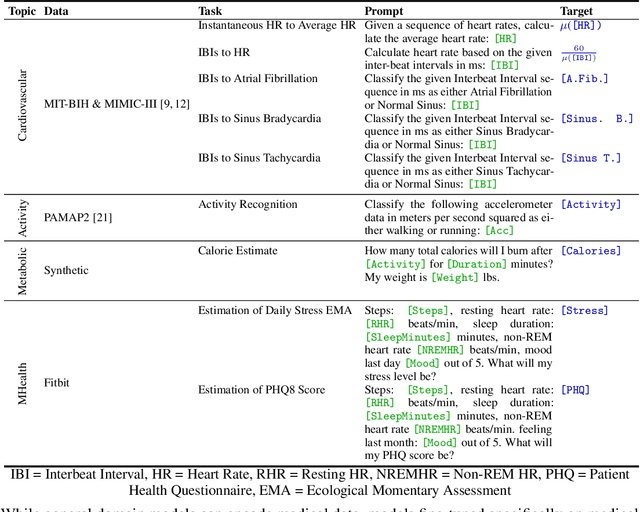

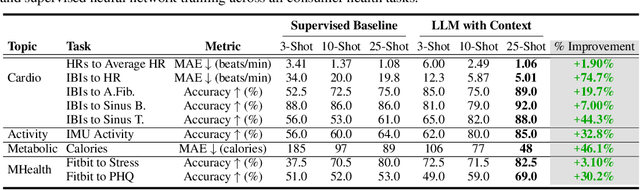
Large language models (LLMs) can capture rich representations of concepts that are useful for real-world tasks. However, language alone is limited. While existing LLMs excel at text-based inferences, health applications require that models be grounded in numerical data (e.g., vital signs, laboratory values in clinical domains; steps, movement in the wellness domain) that is not easily or readily expressed as text in existing training corpus. We demonstrate that with only few-shot tuning, a large language model is capable of grounding various physiological and behavioral time-series data and making meaningful inferences on numerous health tasks for both clinical and wellness contexts. Using data from wearable and medical sensor recordings, we evaluate these capabilities on the tasks of cardiac signal analysis, physical activity recognition, metabolic calculation (e.g., calories burned), and estimation of stress reports and mental health screeners.
Doubly Sparse: Sparse Mixture of Sparse Experts for Efficient Softmax Inference
Jan 30, 2019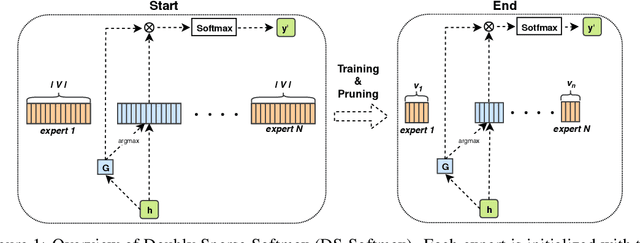
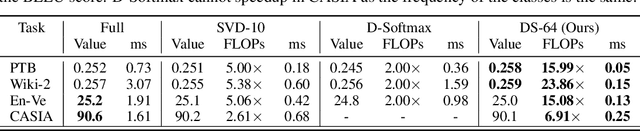
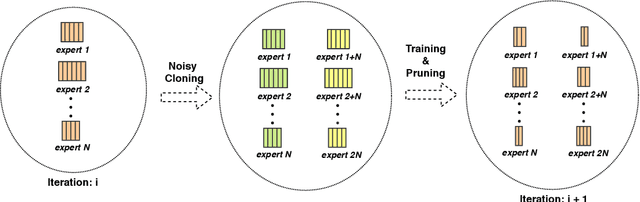
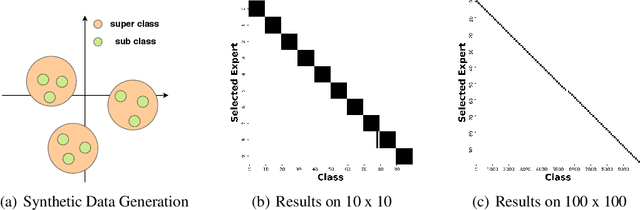
Computations for the softmax function are significantly expensive when the number of output classes is large. In this paper, we present a novel softmax inference speedup method, Doubly Sparse Softmax (DS-Softmax), that leverages sparse mixture of sparse experts to efficiently retrieve top-k classes. Different from most existing methods that require and approximate a fixed softmax, our method is learning-based and can adapt softmax weights for a better approximation. In particular, our method learns a two-level hierarchy which divides entire output class space into several partially overlapping experts. Each expert is sparse and only contains a subset of output classes. To find top-k classes, a sparse mixture enables us to find the most probable expert quickly, and the sparse expert enables us to search within a small-scale softmax. We empirically conduct evaluation on several real-world tasks (including neural machine translation, language modeling and image classification) and demonstrate that significant computation reductions can be achieved without loss of performance.
Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation
Aug 18, 2017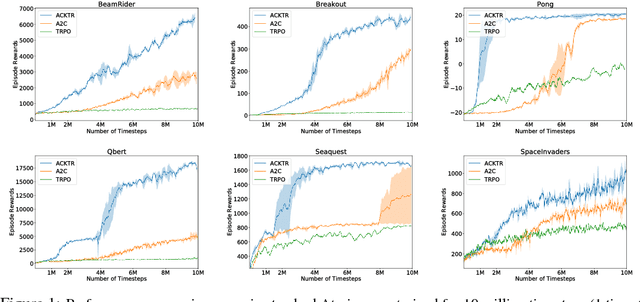
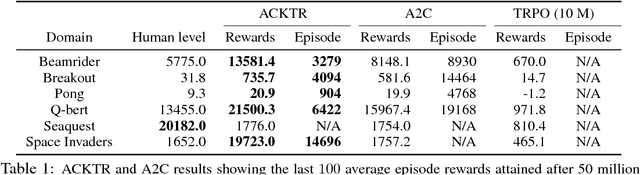
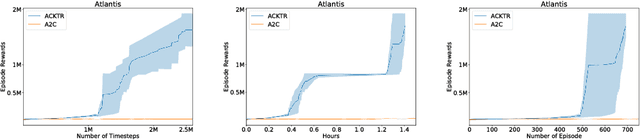
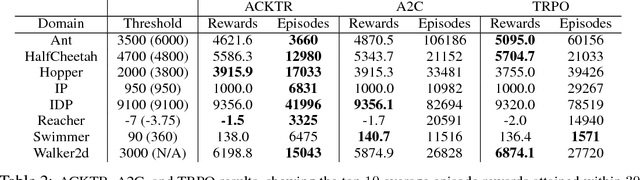
In this work, we propose to apply trust region optimization to deep reinforcement learning using a recently proposed Kronecker-factored approximation to the curvature. We extend the framework of natural policy gradient and propose to optimize both the actor and the critic using Kronecker-factored approximate curvature (K-FAC) with trust region; hence we call our method Actor Critic using Kronecker-Factored Trust Region (ACKTR). To the best of our knowledge, this is the first scalable trust region natural gradient method for actor-critic methods. It is also a method that learns non-trivial tasks in continuous control as well as discrete control policies directly from raw pixel inputs. We tested our approach across discrete domains in Atari games as well as continuous domains in the MuJoCo environment. With the proposed methods, we are able to achieve higher rewards and a 2- to 3-fold improvement in sample efficiency on average, compared to previous state-of-the-art on-policy actor-critic methods. Code is available at https://github.com/openai/baselines