 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
Scaling Wearable Foundation Models
Oct 17, 2024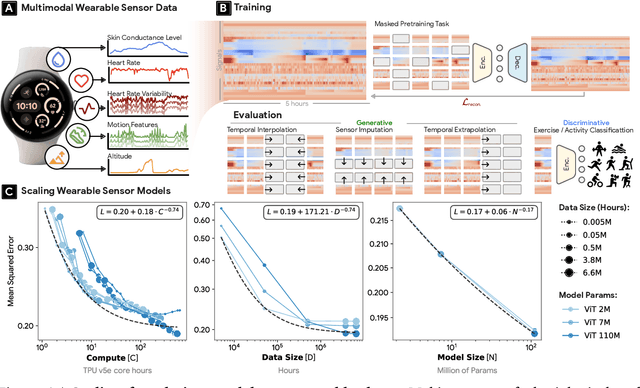
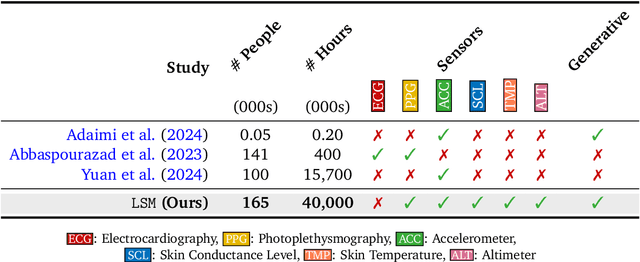


Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data; however, making sense of these observations for scientific and actionable insights is non-trivial. Inspired by the empirical success of generative modeling, where large neural networks learn powerful representations from vast amounts of text, image, video, or audio data, we investigate the scaling properties of sensor foundation models across compute, data, and model size. Using a dataset of up to 40 million hours of in-situ heart rate, heart rate variability, electrodermal activity, accelerometer, skin temperature, and altimeter per-minute data from over 165,000 people, we create LSM, a multimodal foundation model built on the largest wearable-signals dataset with the most extensive range of sensor modalities to date. Our results establish the scaling laws of LSM for tasks such as imputation, interpolation and extrapolation, both across time and sensor modalities. Moreover, we highlight how LSM enables sample-efficient downstream learning for tasks like exercise and activity recognition.
Transforming Wearable Data into Health Insights using Large Language Model Agents
Jun 11, 2024



Despite the proliferation of wearable health trackers and the importance of sleep and exercise to health, deriving actionable personalized insights from wearable data remains a challenge because doing so requires non-trivial open-ended analysis of these data. The recent rise of large language model (LLM) agents, which can use tools to reason about and interact with the world, presents a promising opportunity to enable such personalized analysis at scale. Yet, the application of LLM agents in analyzing personal health is still largely untapped. In this paper, we introduce the Personal Health Insights Agent (PHIA), an agent system that leverages state-of-the-art code generation and information retrieval tools to analyze and interpret behavioral health data from wearables. We curate two benchmark question-answering datasets of over 4000 health insights questions. Based on 650 hours of human and expert evaluation we find that PHIA can accurately address over 84% of factual numerical questions and more than 83% of crowd-sourced open-ended questions. This work has implications for advancing behavioral health across the population, potentially enabling individuals to interpret their own wearable data, and paving the way for a new era of accessible, personalized wellness regimens that are informed by data-driven insights.
Towards a Personal Health Large Language Model
Jun 10, 2024



In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
Large Language Models are Few-Shot Health Learners
May 24, 2023
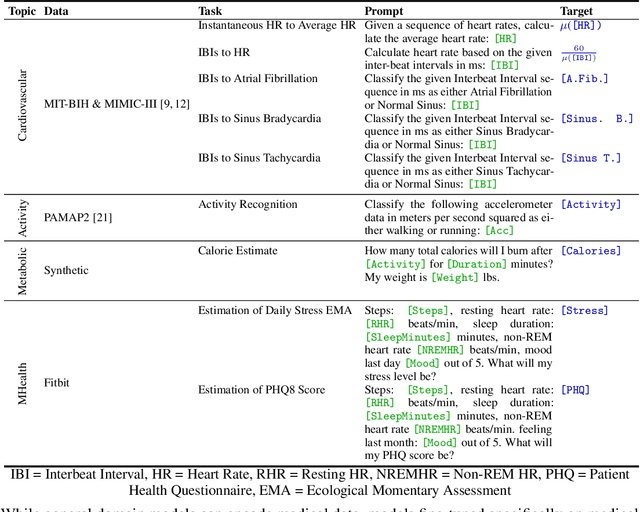

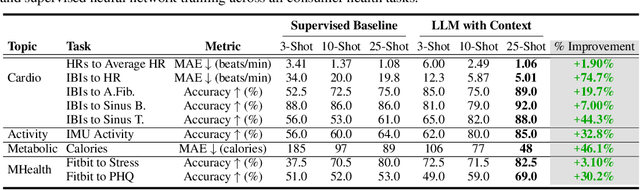
Large language models (LLMs) can capture rich representations of concepts that are useful for real-world tasks. However, language alone is limited. While existing LLMs excel at text-based inferences, health applications require that models be grounded in numerical data (e.g., vital signs, laboratory values in clinical domains; steps, movement in the wellness domain) that is not easily or readily expressed as text in existing training corpus. We demonstrate that with only few-shot tuning, a large language model is capable of grounding various physiological and behavioral time-series data and making meaningful inferences on numerous health tasks for both clinical and wellness contexts. Using data from wearable and medical sensor recordings, we evaluate these capabilities on the tasks of cardiac signal analysis, physical activity recognition, metabolic calculation (e.g., calories burned), and estimation of stress reports and mental health screeners.
Temporal Graph Convolutional Networks for Automatic Seizure Detection
May 03, 2019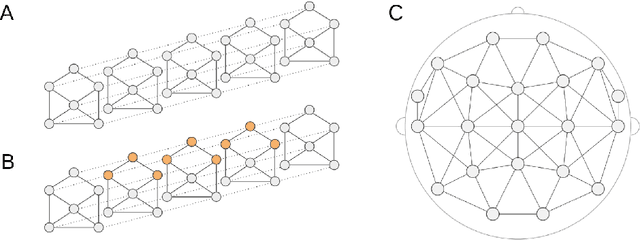


Seizure detection from EEGs is a challenging and time consuming clinical problem that would benefit from the development of automated algorithms. EEGs can be viewed as structural time series, because they are multivariate time series where the placement of leads on a patient's scalp provides prior information about the structure of interactions. Commonly used deep learning models for time series don't offer a way to leverage structural information, but this would be desirable in a model for structural time series. To address this challenge, we propose the temporal graph convolutional network (TGCN), a model that leverages structural information and has relatively few parameters. TGCNs apply feature extraction operations that are localized and shared over both time and space, thereby providing a useful inductive bias in tasks where one expects similar features to be discriminative across the different sequences. In our experiments we focus on metrics that are most important to seizure detection, and demonstrate that TGCN matches the performance of related models that have been shown to be state of the art in other tasks. Additionally, we investigate interpretability advantages of TGCN by exploring approaches for helping clinicians determine when precisely seizures occur, and the parts of the brain that are most involved.