 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPMLN, Weak Constraints, and P-log
Jun 15, 2025LPMLN is a recently introduced formalism that extends answer set programs by adopting the log-linear weight scheme of Markov Logic. This paper investigates the relationships between LPMLN and two other extensions of answer set programs: weak constraints to express a quantitative preference among answer sets, and P-log to incorporate probabilistic uncertainty. We present a translation of LPMLN into programs with weak constraints and a translation of P-log into LPMLN, which complement the existing translations in the opposite directions. The first translation allows us to compute the most probable stable models (i.e., MAP estimates) of LPMLN programs using standard ASP solvers. This result can be extended to other formalisms, such as Markov Logic, ProbLog, and Pearl's Causal Models, that are shown to be translatable into LPMLN. The second translation tells us how probabilistic nonmonotonicity (the ability of the reasoner to change his probabilistic model as a result of new information) of P-log can be represented in LPMLN, which yields a way to compute P-log using standard ASP solvers and MLN solvers.
Think before You Simulate: Symbolic Reasoning to Orchestrate Neural Computation for Counterfactual Question Answering
Jun 12, 2025Causal and temporal reasoning about video dynamics is a challenging problem. While neuro-symbolic models that combine symbolic reasoning with neural-based perception and prediction have shown promise, they exhibit limitations, especially in answering counterfactual questions. This paper introduces a method to enhance a neuro-symbolic model for counterfactual reasoning, leveraging symbolic reasoning about causal relations among events. We define the notion of a causal graph to represent such relations and use Answer Set Programming (ASP), a declarative logic programming method, to find how to coordinate perception and simulation modules. We validate the effectiveness of our approach on two benchmarks, CLEVRER and CRAFT. Our enhancement achieves state-of-the-art performance on the CLEVRER challenge, significantly outperforming existing models. In the case of the CRAFT benchmark, we leverage a large pre-trained language model, such as GPT-3.5 and GPT-4, as a proxy for a dynamics simulator. Our findings show that this method can further improve its performance on counterfactual questions by providing alternative prompts instructed by symbolic causal reasoning.
Towards a Personal Health Large Language Model
Jun 10, 2024



In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
Coupling Large Language Models with Logic Programming for Robust and General Reasoning from Text
Jul 15, 2023



While large language models (LLMs), such as GPT-3, appear to be robust and general, their reasoning ability is not at a level to compete with the best models trained for specific natural language reasoning problems. In this study, we observe that a large language model can serve as a highly effective few-shot semantic parser. It can convert natural language sentences into a logical form that serves as input for answer set programs, a logic-based declarative knowledge representation formalism. The combination results in a robust and general system that can handle multiple question-answering tasks without requiring retraining for each new task. It only needs a few examples to guide the LLM's adaptation to a specific task, along with reusable ASP knowledge modules that can be applied to multiple tasks. We demonstrate that this method achieves state-of-the-art performance on several NLP benchmarks, including bAbI, StepGame, CLUTRR, and gSCAN. Additionally, it successfully tackles robot planning tasks that an LLM alone fails to solve.
Leveraging Large Language Models to Generate Answer Set Programs
Jul 15, 2023



Large language models (LLMs), such as GPT-3 and GPT-4, have demonstrated exceptional performance in various natural language processing tasks and have shown the ability to solve certain reasoning problems. However, their reasoning capabilities are limited and relatively shallow, despite the application of various prompting techniques. In contrast, formal logic is adept at handling complex reasoning, but translating natural language descriptions into formal logic is a challenging task that non-experts struggle with. This paper proposes a neuro-symbolic method that combines the strengths of large language models and answer set programming. Specifically, we employ an LLM to transform natural language descriptions of logic puzzles into answer set programs. We carefully design prompts for an LLM to convert natural language descriptions into answer set programs in a step by step manner. Surprisingly, with just a few in-context learning examples, LLMs can generate reasonably complex answer set programs. The majority of errors made are relatively simple and can be easily corrected by humans, thus enabling LLMs to effectively assist in the creation of answer set programs.
NeurASP: Embracing Neural Networks into Answer Set Programming
Jul 15, 2023
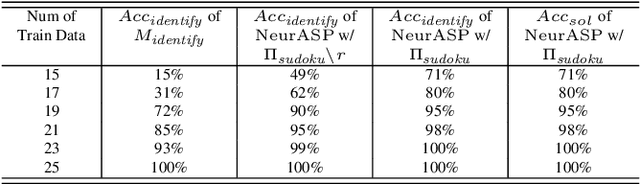

We present NeurASP, a simple extension of answer set programs by embracing neural networks. By treating the neural network output as the probability distribution over atomic facts in answer set programs, NeurASP provides a simple and effective way to integrate sub-symbolic and symbolic computation. We demonstrate how NeurASP can make use of a pre-trained neural network in symbolic computation and how it can improve the neural network's perception result by applying symbolic reasoning in answer set programming. Also, NeurASP can be used to train a neural network better by training with ASP rules so that a neural network not only learns from implicit correlations from the data but also from the explicit complex semantic constraints expressed by the rules.
Injecting Logical Constraints into Neural Networks via Straight-Through Estimators
Jul 10, 2023


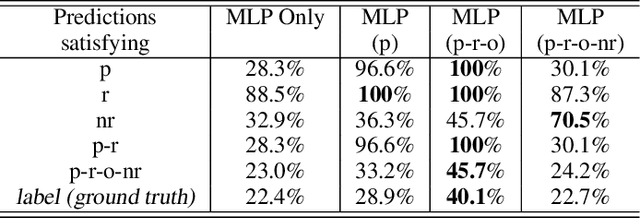
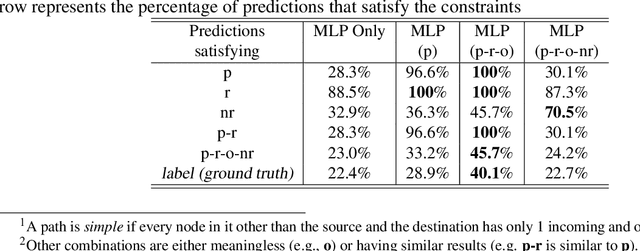
Injecting discrete logical constraints into neural network learning is one of the main challenges in neuro-symbolic AI. We find that a straight-through-estimator, a method introduced to train binary neural networks, could effectively be applied to incorporate logical constraints into neural network learning. More specifically, we design a systematic way to represent discrete logical constraints as a loss function; minimizing this loss using gradient descent via a straight-through-estimator updates the neural network's weights in the direction that the binarized outputs satisfy the logical constraints. The experimental results show that by leveraging GPUs and batch training, this method scales significantly better than existing neuro-symbolic methods that require heavy symbolic computation for computing gradients. Also, we demonstrate that our method applies to different types of neural networks, such as MLP, CNN, and GNN, making them learn with no or fewer labeled data by learning directly from known constraints.
* 27 pages
Learning to Solve Constraint Satisfaction Problems with Recurrent Transformer
Jul 10, 2023



Constraint satisfaction problems (CSPs) are about finding values of variables that satisfy the given constraints. We show that Transformer extended with recurrence is a viable approach to learning to solve CSPs in an end-to-end manner, having clear advantages over state-of-the-art methods such as Graph Neural Networks, SATNet, and some neuro-symbolic models. With the ability of Transformer to handle visual input, the proposed Recurrent Transformer can straightforwardly be applied to visual constraint reasoning problems while successfully addressing the symbol grounding problem. We also show how to leverage deductive knowledge of discrete constraints in the Transformer's inductive learning to achieve sample-efficient learning and semi-supervised learning for CSPs.
Extending Answer Set Programs with Neural Networks
Sep 22, 2020
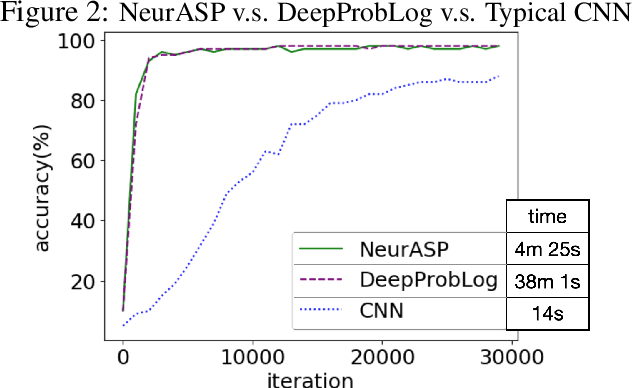
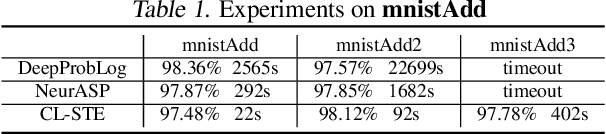
The integration of low-level perception with high-level reasoning is one of the oldest problems in Artificial Intelligence. Recently, several proposals were made to implement the reasoning process in complex neural network architectures. While these works aim at extending neural networks with the capability of reasoning, a natural question that we consider is: can we extend answer set programs with neural networks to allow complex and high-level reasoning on neural network outputs? As a preliminary result, we propose NeurASP -- a simple extension of answer set programs by embracing neural networks where neural network outputs are treated as probability distributions over atomic facts in answer set programs. We show that NeurASP can not only improve the perception accuracy of a pre-trained neural network, but also help to train a neural network better by giving restrictions through logic rules. However, training with NeurASP would take much more time than pure neural network training due to the internal use of a symbolic reasoning engine. For future work, we plan to investigate the potential ways to solve the scalability issue of NeurASP. One potential way is to embed logic programs directly in neural networks. On this route, we plan to first design a SAT solver using neural networks, then extend such a solver to allow logic programs.
* In Proceedings ICLP 2020, arXiv:2009.09158
Translating LPOD and CR-Prolog2 into Standard Answer Set Programs
May 02, 2018Logic Programs with Ordered Disjunction (LPOD) is an extension of standard answer set programs to handle preference using the construct of ordered disjunction, and CR-Prolog2 is an extension of standard answer set programs with consistency restoring rules and LPOD-like ordered disjunction. We present reductions of each of these languages into the standard ASP language, which gives us an alternative way to understand the extensions in terms of the standard ASP language.