 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting Logical Constraints into Neural Networks via Straight-Through Estimators
Jul 10, 2023
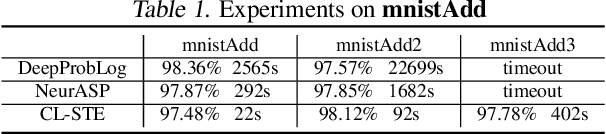


Injecting discrete logical constraints into neural network learning is one of the main challenges in neuro-symbolic AI. We find that a straight-through-estimator, a method introduced to train binary neural networks, could effectively be applied to incorporate logical constraints into neural network learning. More specifically, we design a systematic way to represent discrete logical constraints as a loss function; minimizing this loss using gradient descent via a straight-through-estimator updates the neural network's weights in the direction that the binarized outputs satisfy the logical constraints. The experimental results show that by leveraging GPUs and batch training, this method scales significantly better than existing neuro-symbolic methods that require heavy symbolic computation for computing gradients. Also, we demonstrate that our method applies to different types of neural networks, such as MLP, CNN, and GNN, making them learn with no or fewer labeled data by learning directly from known constraints.
* 27 pages
Applying GPGPU to Recurrent Neural Network Language Model based Fast Network Search in the Real-Time LVCSR
Jul 23, 2020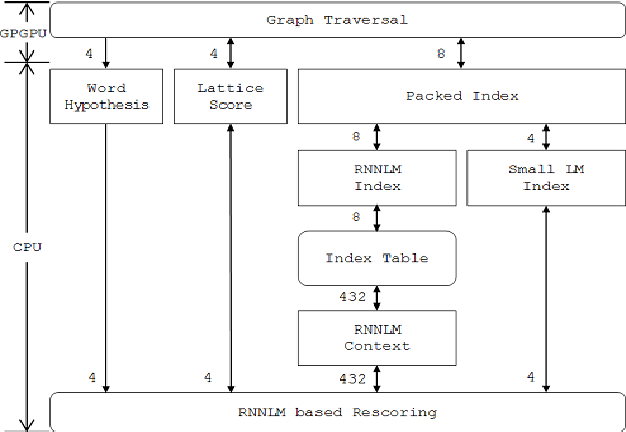

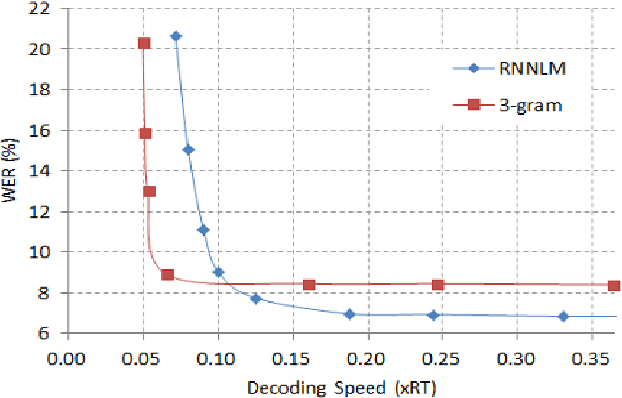
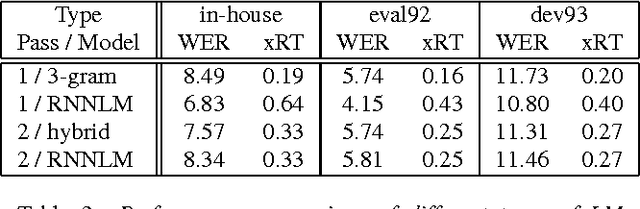
Recurrent Neural Network Language Models (RNNLMs) have started to be used in various fields of speech recognition due to their outstanding performance. However, the high computational complexity of RNNLMs has been a hurdle in applying the RNNLM to a real-time Large Vocabulary Continuous Speech Recognition (LVCSR). In order to accelerate the speed of RNNLM-based network searches during decoding, we apply the General Purpose Graphic Processing Units (GPGPUs). This paper proposes a novel method of applying GPGPUs to RNNLM-based graph traversals. We have achieved our goal by reducing redundant computations on CPUs and amount of transfer between GPGPUs and CPUs. The proposed approach was evaluated on both WSJ corpus and in-house data. Experiments shows that the proposed approach achieves the real-time speed in various circumstances while maintaining the Word Error Rate (WER) to be relatively 10% lower than that of n-gram models.
Differentiable Pruning Method for Neural Networks
Apr 24, 2019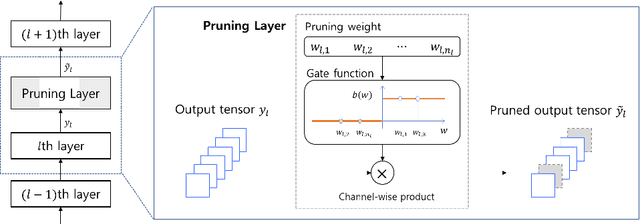
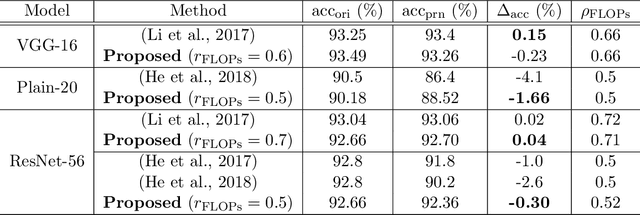
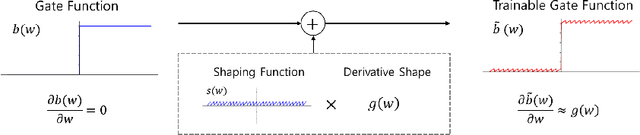
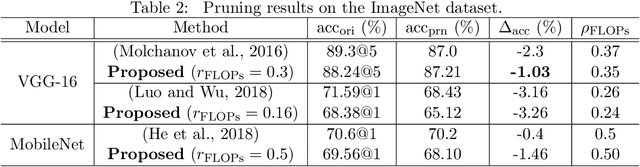
Architecture optimization is a promising technique to find an efficient neural network to meet certain requirements, which is usually a problem of selections. This paper introduces a concept of a trainable gate function and proposes a channel pruning method which finds automatically the optimal combination of channels using a simple gradient descent training procedure. The trainable gate function, which confers a differentiable property to discrete-valued variables, allows us to directly optimize loss functions that include discrete values such as the number of parameters or FLOPs that are generally non-differentiable. Channel pruning can be applied simply by appending trainable gate functions to each intermediate output tensor followed by fine-tuning the overall model, using any gradient-based training methods. Our experiments show that the proposed method can achieve better compression results on various models. For instance, our proposed method compresses ResNet-56 on CIFAR-10 dataset by half in terms of the number of FLOPs without accuracy drop.
Accelerating recurrent neural network language model based online speech recognition system
Jan 30, 2018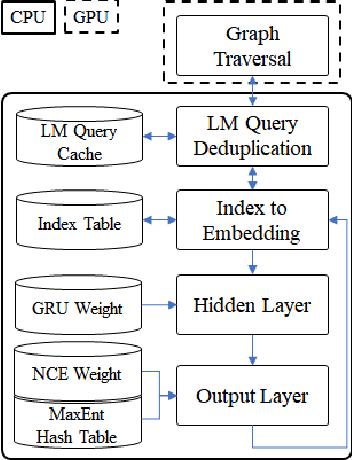
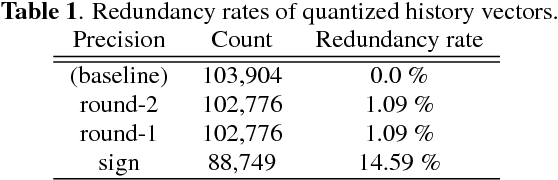
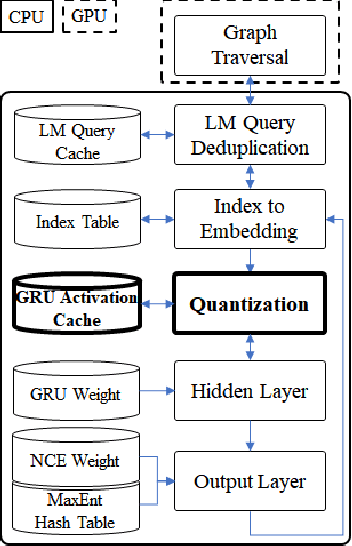
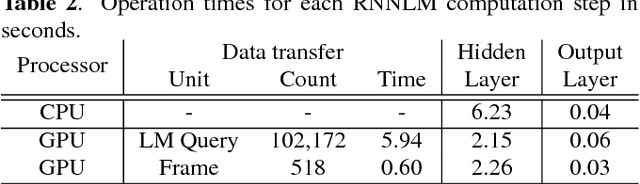
This paper presents methods to accelerate recurrent neural network based language models (RNNLMs) for online speech recognition systems. Firstly, a lossy compression of the past hidden layer outputs (history vector) with caching is introduced in order to reduce the number of LM queries. Next, RNNLM computations are deployed in a CPU-GPU hybrid manner, which computes each layer of the model on a more advantageous platform. The added overhead by data exchanges between CPU and GPU is compensated through a frame-wise batching strategy. The performance of the proposed methods evaluated on LibriSpeech test sets indicates that the reduction in history vector precision improves the average recognition speed by 1.23 times with minimum degradation in accuracy. On the other hand, the CPU-GPU hybrid parallelization enables RNNLM based real-time recognition with a four times improvement in speed.