 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Pruning Method for Neural Networks
Apr 24, 2019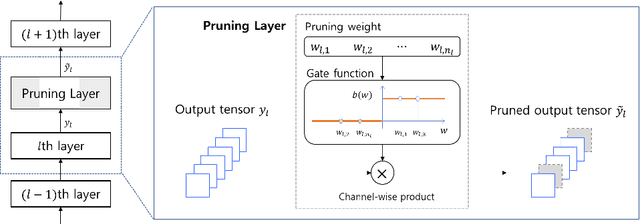
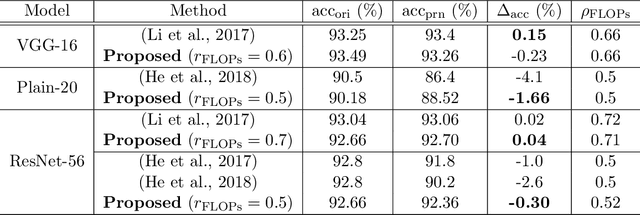
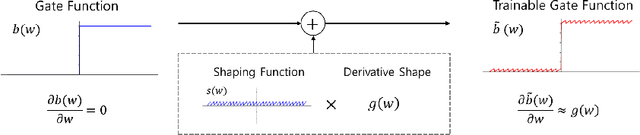
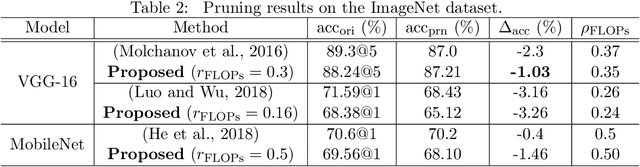
Architecture optimization is a promising technique to find an efficient neural network to meet certain requirements, which is usually a problem of selections. This paper introduces a concept of a trainable gate function and proposes a channel pruning method which finds automatically the optimal combination of channels using a simple gradient descent training procedure. The trainable gate function, which confers a differentiable property to discrete-valued variables, allows us to directly optimize loss functions that include discrete values such as the number of parameters or FLOPs that are generally non-differentiable. Channel pruning can be applied simply by appending trainable gate functions to each intermediate output tensor followed by fine-tuning the overall model, using any gradient-based training methods. Our experiments show that the proposed method can achieve better compression results on various models. For instance, our proposed method compresses ResNet-56 on CIFAR-10 dataset by half in terms of the number of FLOPs without accuracy drop.
How Compact?: Assessing Compactness of Representations through Layer-Wise Pruning
Jan 09, 2019
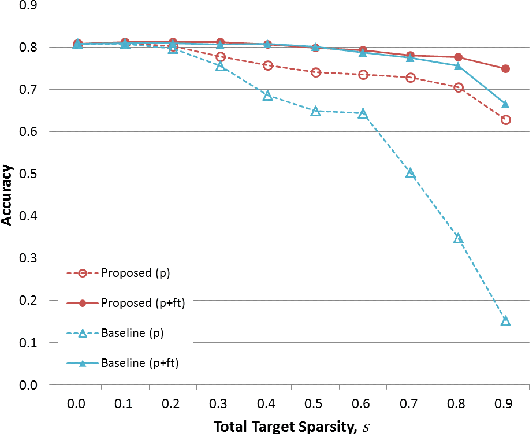
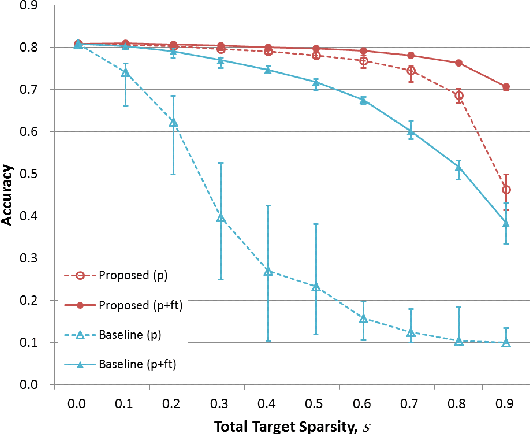
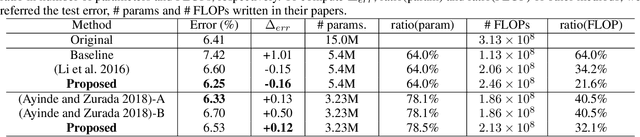
Various forms of representations may arise in the many layers embedded in deep neural networks (DNNs). Of these, where can we find the most compact representation? We propose to use a pruning framework to answer this question: How compact can each layer be compressed, without losing performance? Most of the existing DNN compression methods do not consider the relative compressibility of the individual layers. They uniformly apply a single target sparsity to all layers or adapt layer sparsity using heuristics and additional training. We propose a principled method that automatically determines the sparsity of individual layers derived from the importance of each layer. To do this, we consider a metric to measure the importance of each layer based on the layer-wise capacity. Given the trained model and the total target sparsity, we first evaluate the importance of each layer from the model. From the evaluated importance, we compute the layer-wise sparsity of each layer. The proposed method can be applied to any DNN architecture and can be combined with any pruning method that takes the total target sparsity as a parameter. To validate the proposed method, we carried out an image classification task with two types of DNN architectures on two benchmark datasets and used three pruning methods for compression. In case of VGG-16 model with weight pruning on the ImageNet dataset, we achieved up to 75% (17.5% on average) better top-5 accuracy than the baseline under the same total target sparsity. Furthermore, we analyzed where the maximum compression can occur in the network. This kind of analysis can help us identify the most compact representation within a deep neural network.
Comparing Sample-wise Learnability Across Deep Neural Network Models
Jan 08, 2019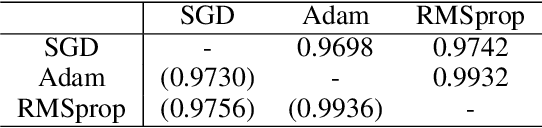
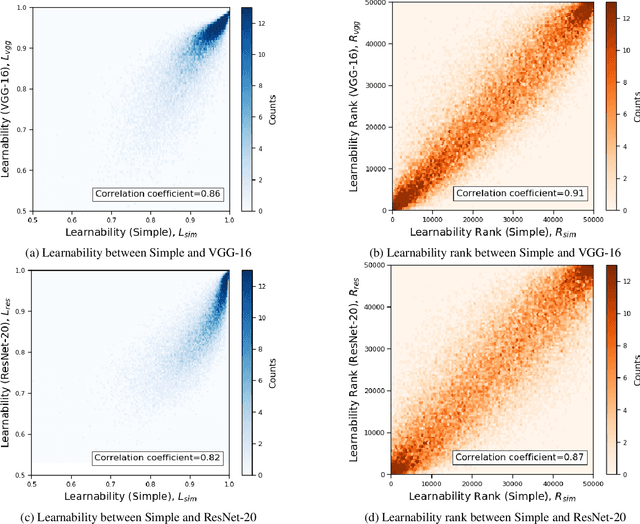
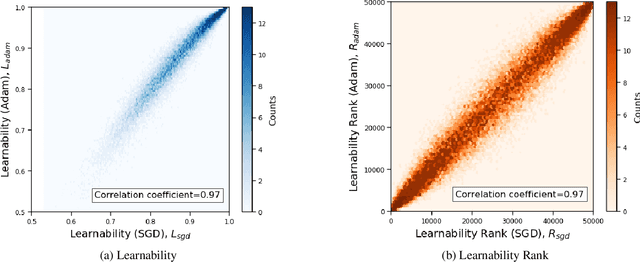
Estimating the relative importance of each sample in a training set has important practical and theoretical value, such as in importance sampling or curriculum learning. This kind of focus on individual samples invokes the concept of sample-wise learnability: How easy is it to correctly learn each sample (cf. PAC learnability)? In this paper, we approach the sample-wise learnability problem within a deep learning context. We propose a measure of the learnability of a sample with a given deep neural network (DNN) model. The basic idea is to train the given model on the training set, and for each sample, aggregate the hits and misses over the entire training epochs. Our experiments show that the sample-wise learnability measure collected this way is highly linearly correlated across different DNN models (ResNet-20, VGG-16, and MobileNet), suggesting that such a measure can provide deep general insights on the data's properties. We expect our method to help develop better curricula for training, and help us better understand the data itself.