 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Visual Cortical Lateral Connection Properties into CNN: Recurrent Activation and Excitatory-Inhibitory Separation
Sep 18, 2025The original Convolutional Neural Networks (CNNs) and their modern updates such as the ResNet are heavily inspired by the mammalian visual system. These models include afferent connections (retina and LGN to the visual cortex) and long-range projections (connections across different visual cortical areas). However, in the mammalian visual system, there are connections within each visual cortical area, known as lateral (or horizontal) connections. These would roughly correspond to connections within CNN feature maps, and this important architectural feature is missing in current CNN models. In this paper, we present how such lateral connections can be modeled within the standard CNN framework, and test its benefits and analyze its emergent properties in relation to the biological visual system. We will focus on two main architectural features of lateral connections: (1) recurrent activation and (2) separation of excitatory and inhibitory connections. We show that recurrent CNN using weight sharing is equivalent to lateral connections, and propose a custom loss function to separate excitatory and inhibitory weights. The addition of these two leads to increased classification accuracy, and importantly, the activation properties and connection properties of the resulting model show properties similar to those observed in the biological visual system. We expect our approach to help align CNN closer to its biological counterpart and better understand the principles of visual cortical computation.
Indexing Analytics to Instances: How Integrating a Dashboard can Support Design Education
Apr 08, 2024



We investigate how to use AI-based analytics to support design education. The analytics at hand measure multiscale design, that is, students' use of space and scale to visually and conceptually organize their design work. With the goal of making the analytics intelligible to instructors, we developed a research artifact integrating a design analytics dashboard with design instances, and the design environment that students use to create them. We theorize about how Suchman's notion of mutual intelligibility requires contextualized investigation of AI in order to develop findings about how analytics work for people. We studied the research artifact in 5 situated course contexts, in 3 departments. A total of 236 students used the multiscale design environment. The 9 instructors who taught those students experienced the analytics via the new research artifact. We derive findings from a qualitative analysis of interviews with instructors regarding their experiences. Instructors reflected on how the analytics and their presentation in the dashboard have the potential to affect design education. We develop research implications addressing: (1) how indexing design analytics in the dashboard to actual design work instances helps design instructors reflect on what they mean and, more broadly, is a technique for how AI-based design analytics can support instructors' assessment and feedback experiences in situated course contexts; and (2) how multiscale design analytics, in particular, have the potential to support design education. By indexing, we mean linking which provides context, here connecting the numbers of the analytics with visually annotated design work instances.
AdjointBackMapV2: Precise Reconstruction of Arbitrary CNN Unit's Activation via Adjoint Operators
Oct 04, 2021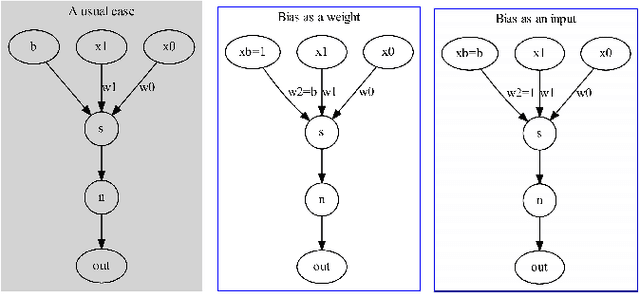

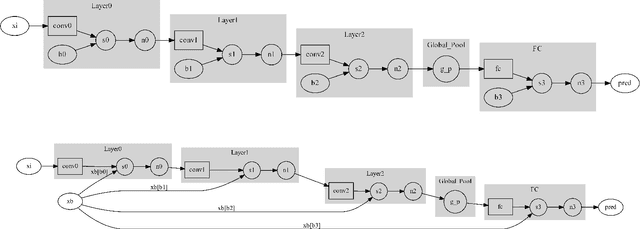
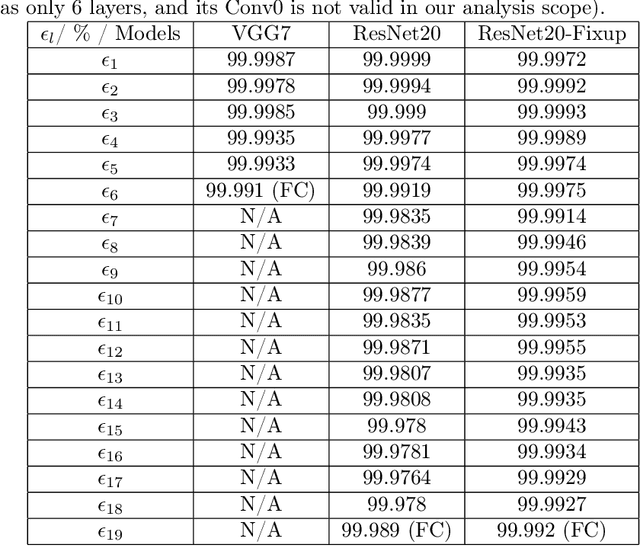
Adjoint operators have been found to be effective in the exploration of CNN's inner workings [1]. However, the previous no-bias assumption restricted its generalization. We overcome the restriction via embedding input images into an extended normed space that includes bias in all CNN layers as part of the extended input space and propose an adjoint-operator-based algorithm that maps high-level weights back to the extended input space for reconstructing an effective hypersurface. Such hypersurface can be computed for an arbitrary unit in the CNN, and we prove that this reconstructed hypersurface, when multiplied by the original input (through an inner product), will precisely replicate the output value of each unit. We show experimental results based on the CIFAR-10 dataset that the proposed approach achieves near $0$ reconstruction error.
Meaning Versus Information, Prediction Versus Memory, and Question Versus Answer
Jun 29, 2021

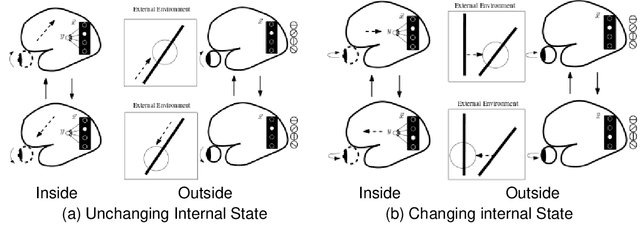
Brain science and artificial intelligence have made great progress toward the understanding and engineering of the human mind. The progress has accelerated significantly since the turn of the century thanks to new methods for probing the brain (both structure and function), and rapid development in deep learning research. However, despite these new developments, there are still many open questions, such as how to understand the brain at the system level, and various robustness issues and limitations of deep learning. In this informal essay, I will talk about some of the concepts that are central to brain science and artificial intelligence, such as information and memory, and discuss how a different view on these concepts can help us move forward, beyond current limits of our understanding in these fields.
AdjointBackMap: Reconstructing Effective Decision Hypersurfaces from CNN Layers Using Adjoint Operators
Dec 16, 2020
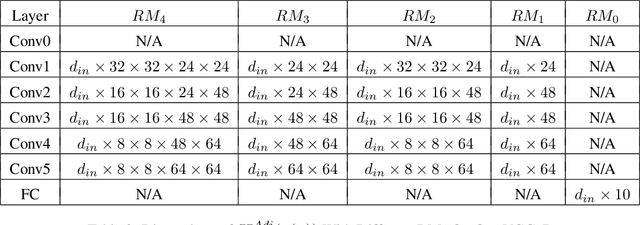
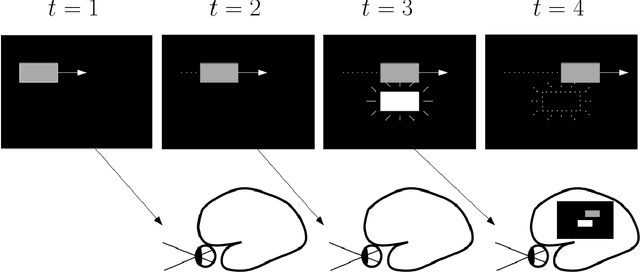
There are several effective methods in explaining the inner workings of convolutional neural networks (CNNs). However, in general, finding the inverse of the function performed by CNNs as a whole is an ill-posed problem. In this paper, we propose a method based on adjoint operators to reconstruct, given an arbitrary unit in the CNN (except for the first convolutional layer), its effective hypersurface in the input space that replicates that unit's decision surface conditioned on a particular input image. Our results show that the hypersurface reconstructed this way, when multiplied by the original input image, would give nearly exact output value of that unit. We find that the CNN unit's decision surface is largely conditioned on the input, and this may explain why adversarial inputs can effectively deceive CNNs.
Emergence of Different Modes of Tool Use in a Reaching and Dragging Task
Dec 08, 2020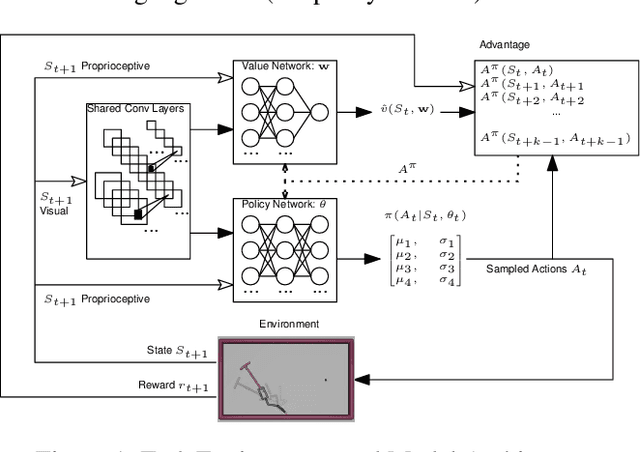
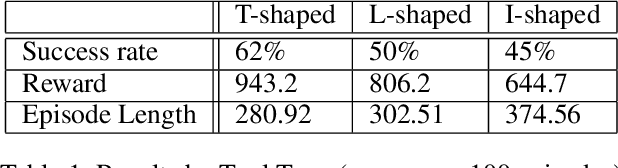
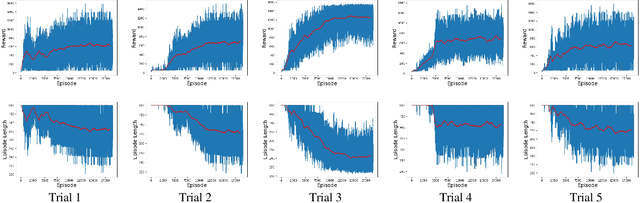

Tool use is an important milestone in the evolution of intelligence. In this paper, we investigate different modes of tool use that emerge in a reaching and dragging task. In this task, a jointed arm with a gripper must grab a tool (T, I, or L-shaped) and drag an object down to the target location (the bottom of the arena). The simulated environment had real physics such as gravity and friction. We trained a deep-reinforcement learning based controller (with raw visual and proprioceptive input) with minimal reward shaping information to tackle this task. We observed the emergence of a wide range of unexpected behaviors, not directly encoded in the motor primitives or reward functions. Examples include hitting the object to the target location, correcting error of initial contact, throwing the tool toward the object, as well as normal expected behavior such as wide sweep. Also, we further analyzed these behaviors based on the type of tool and the initial position of the target object. Our results show a rich repertoire of behaviors, beyond the basic built-in mechanisms of the deep reinforcement learning method we used.
Action Recognition and State Change Prediction in a Recipe Understanding Task Using a Lightweight Neural Network Model
Jan 23, 2020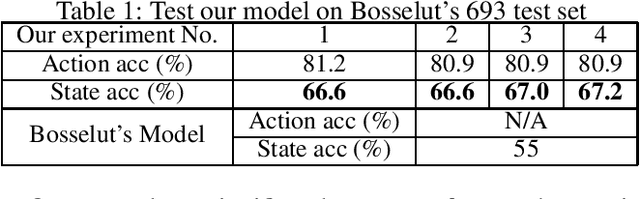
Consider a natural language sentence describing a specific step in a food recipe. In such instructions, recognizing actions (such as press, bake, etc.) and the resulting changes in the state of the ingredients (shape molded, custard cooked, temperature hot, etc.) is a challenging task. One way to cope with this challenge is to explicitly model a simulator module that applies actions to entities and predicts the resulting outcome (Bosselut et al. 2018). However, such a model can be unnecessarily complex. In this paper, we propose a simplified neural network model that separates action recognition and state change prediction, while coupling the two through a novel loss function. This allows learning to indirectly influence each other. Our model, although simpler, achieves higher state change prediction performance (67% average accuracy for ours vs. 55% in (Bosselut et al. 2018)) and takes fewer samples to train (10K ours vs. 65K+ by (Bosselut et al. 2018)).
Differentiable Pruning Method for Neural Networks
Apr 24, 2019
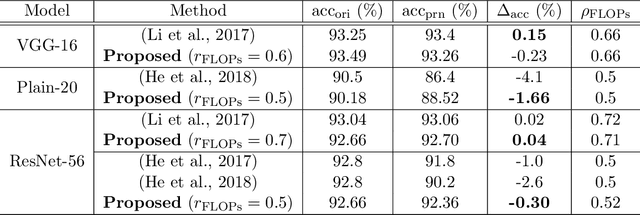
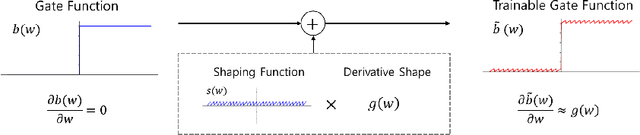
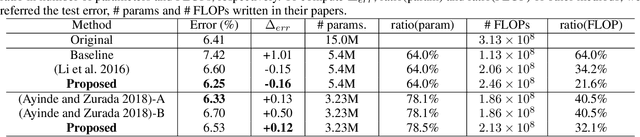
Architecture optimization is a promising technique to find an efficient neural network to meet certain requirements, which is usually a problem of selections. This paper introduces a concept of a trainable gate function and proposes a channel pruning method which finds automatically the optimal combination of channels using a simple gradient descent training procedure. The trainable gate function, which confers a differentiable property to discrete-valued variables, allows us to directly optimize loss functions that include discrete values such as the number of parameters or FLOPs that are generally non-differentiable. Channel pruning can be applied simply by appending trainable gate functions to each intermediate output tensor followed by fine-tuning the overall model, using any gradient-based training methods. Our experiments show that the proposed method can achieve better compression results on various models. For instance, our proposed method compresses ResNet-56 on CIFAR-10 dataset by half in terms of the number of FLOPs without accuracy drop.
How Compact?: Assessing Compactness of Representations through Layer-Wise Pruning
Jan 09, 2019
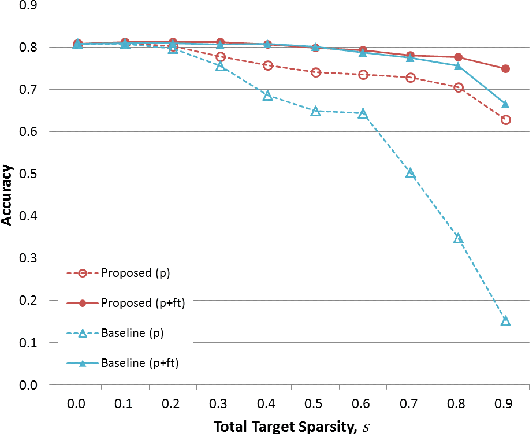
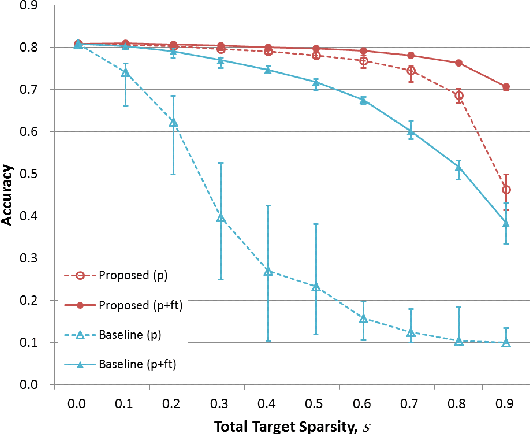
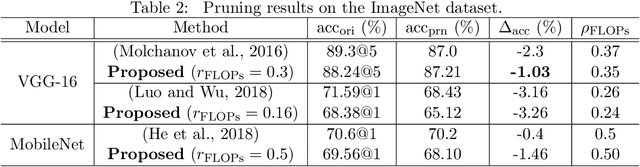
Various forms of representations may arise in the many layers embedded in deep neural networks (DNNs). Of these, where can we find the most compact representation? We propose to use a pruning framework to answer this question: How compact can each layer be compressed, without losing performance? Most of the existing DNN compression methods do not consider the relative compressibility of the individual layers. They uniformly apply a single target sparsity to all layers or adapt layer sparsity using heuristics and additional training. We propose a principled method that automatically determines the sparsity of individual layers derived from the importance of each layer. To do this, we consider a metric to measure the importance of each layer based on the layer-wise capacity. Given the trained model and the total target sparsity, we first evaluate the importance of each layer from the model. From the evaluated importance, we compute the layer-wise sparsity of each layer. The proposed method can be applied to any DNN architecture and can be combined with any pruning method that takes the total target sparsity as a parameter. To validate the proposed method, we carried out an image classification task with two types of DNN architectures on two benchmark datasets and used three pruning methods for compression. In case of VGG-16 model with weight pruning on the ImageNet dataset, we achieved up to 75% (17.5% on average) better top-5 accuracy than the baseline under the same total target sparsity. Furthermore, we analyzed where the maximum compression can occur in the network. This kind of analysis can help us identify the most compact representation within a deep neural network.
Comparing Sample-wise Learnability Across Deep Neural Network Models
Jan 08, 2019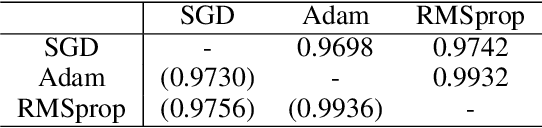
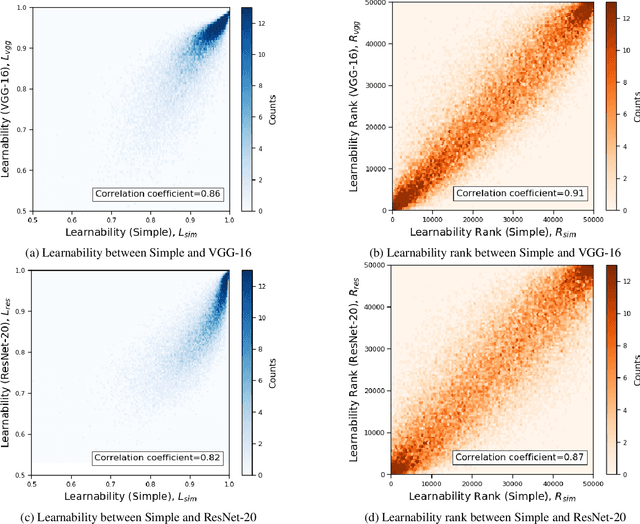
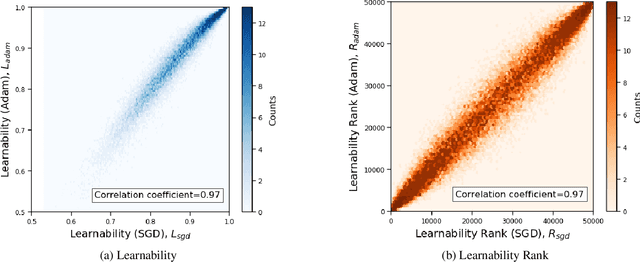
Estimating the relative importance of each sample in a training set has important practical and theoretical value, such as in importance sampling or curriculum learning. This kind of focus on individual samples invokes the concept of sample-wise learnability: How easy is it to correctly learn each sample (cf. PAC learnability)? In this paper, we approach the sample-wise learnability problem within a deep learning context. We propose a measure of the learnability of a sample with a given deep neural network (DNN) model. The basic idea is to train the given model on the training set, and for each sample, aggregate the hits and misses over the entire training epochs. Our experiments show that the sample-wise learnability measure collected this way is highly linearly correlated across different DNN models (ResNet-20, VGG-16, and MobileNet), suggesting that such a measure can provide deep general insights on the data's properties. We expect our method to help develop better curricula for training, and help us better understand the data itself.