 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Sample-wise Learnability Across Deep Neural Network Models
Paper and Code
Jan 08, 2019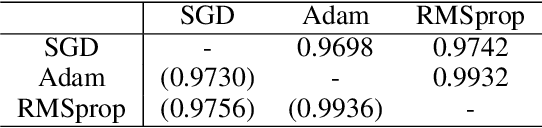
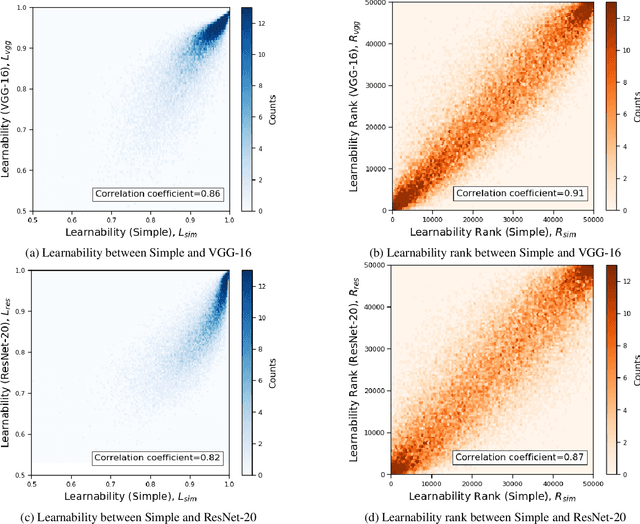
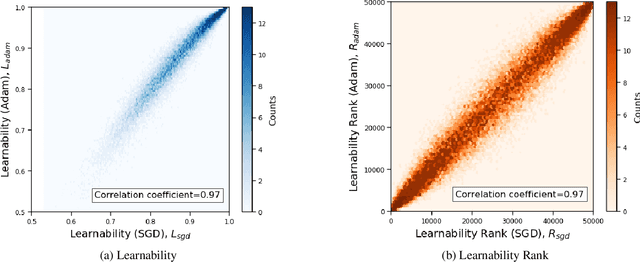
Estimating the relative importance of each sample in a training set has important practical and theoretical value, such as in importance sampling or curriculum learning. This kind of focus on individual samples invokes the concept of sample-wise learnability: How easy is it to correctly learn each sample (cf. PAC learnability)? In this paper, we approach the sample-wise learnability problem within a deep learning context. We propose a measure of the learnability of a sample with a given deep neural network (DNN) model. The basic idea is to train the given model on the training set, and for each sample, aggregate the hits and misses over the entire training epochs. Our experiments show that the sample-wise learnability measure collected this way is highly linearly correlated across different DNN models (ResNet-20, VGG-16, and MobileNet), suggesting that such a measure can provide deep general insights on the data's properties. We expect our method to help develop better curricula for training, and help us better understand the data itself.