 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjointBackMapV2: Precise Reconstruction of Arbitrary CNN Unit's Activation via Adjoint Operators
Oct 04, 2021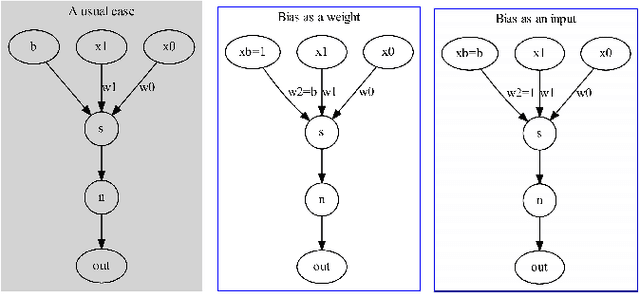

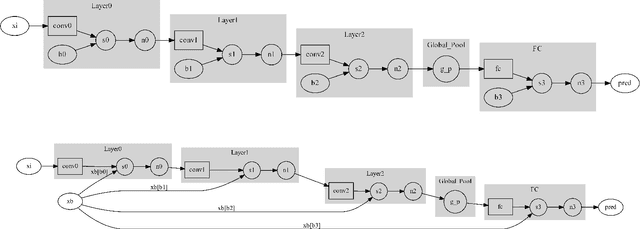
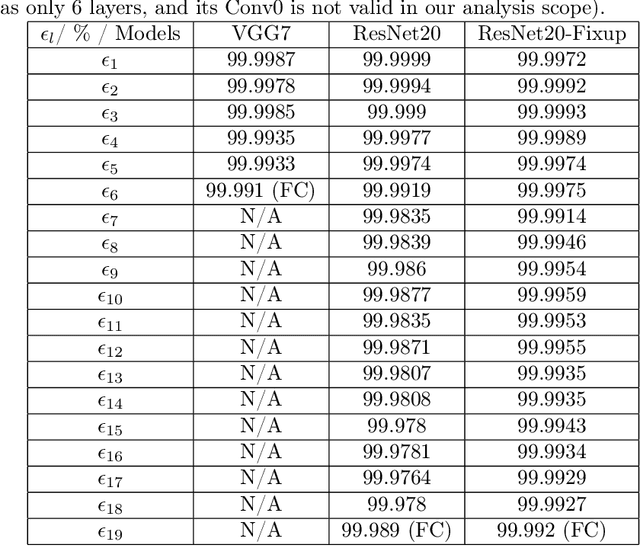
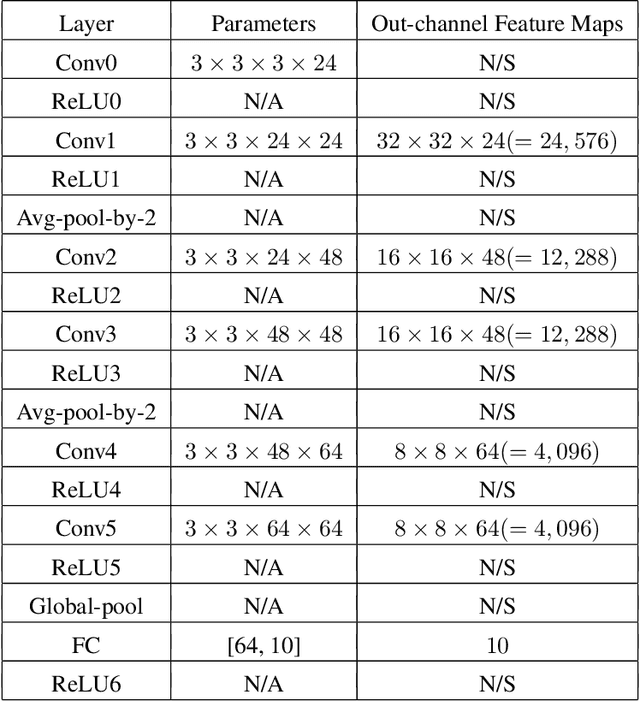
Adjoint operators have been found to be effective in the exploration of CNN's inner workings [1]. However, the previous no-bias assumption restricted its generalization. We overcome the restriction via embedding input images into an extended normed space that includes bias in all CNN layers as part of the extended input space and propose an adjoint-operator-based algorithm that maps high-level weights back to the extended input space for reconstructing an effective hypersurface. Such hypersurface can be computed for an arbitrary unit in the CNN, and we prove that this reconstructed hypersurface, when multiplied by the original input (through an inner product), will precisely replicate the output value of each unit. We show experimental results based on the CIFAR-10 dataset that the proposed approach achieves near $0$ reconstruction error.
AdjointBackMap: Reconstructing Effective Decision Hypersurfaces from CNN Layers Using Adjoint Operators
Dec 16, 2020
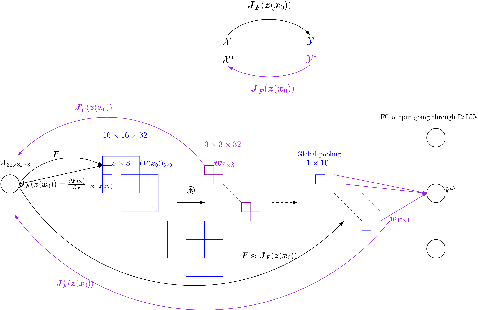
There are several effective methods in explaining the inner workings of convolutional neural networks (CNNs). However, in general, finding the inverse of the function performed by CNNs as a whole is an ill-posed problem. In this paper, we propose a method based on adjoint operators to reconstruct, given an arbitrary unit in the CNN (except for the first convolutional layer), its effective hypersurface in the input space that replicates that unit's decision surface conditioned on a particular input image. Our results show that the hypersurface reconstructed this way, when multiplied by the original input image, would give nearly exact output value of that unit. We find that the CNN unit's decision surface is largely conditioned on the input, and this may explain why adversarial inputs can effectively deceive CNNs.
Action Recognition and State Change Prediction in a Recipe Understanding Task Using a Lightweight Neural Network Model
Jan 23, 2020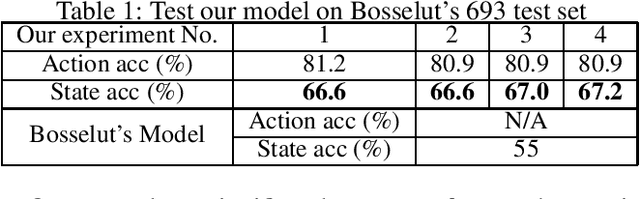
Consider a natural language sentence describing a specific step in a food recipe. In such instructions, recognizing actions (such as press, bake, etc.) and the resulting changes in the state of the ingredients (shape molded, custard cooked, temperature hot, etc.) is a challenging task. One way to cope with this challenge is to explicitly model a simulator module that applies actions to entities and predicts the resulting outcome (Bosselut et al. 2018). However, such a model can be unnecessarily complex. In this paper, we propose a simplified neural network model that separates action recognition and state change prediction, while coupling the two through a novel loss function. This allows learning to indirectly influence each other. Our model, although simpler, achieves higher state change prediction performance (67% average accuracy for ours vs. 55% in (Bosselut et al. 2018)) and takes fewer samples to train (10K ours vs. 65K+ by (Bosselut et al. 2018)).