 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusable Slotwise Mechanisms
Feb 21, 2023Agents that can understand and reason over the dynamics of objects can have a better capability to act robustly and generalize to novel scenarios. Such an ability, however, requires a suitable representation of the scene as well as an understanding of the mechanisms that govern the interactions of different subsets of objects. To address this problem, we propose RSM, or Reusable Slotwise Mechanisms, that jointly learns a slotwise representation of the scene and a modular architecture that dynamically chooses one mechanism among a set of reusable mechanisms to predict the next state of each slot. RSM crucially takes advantage of a \textit{Central Contextual Information (CCI)}, which lets each selected reusable mechanism access the rest of the slots through a bottleneck, effectively allowing for modeling higher order and complex interactions that might require a sparse subset of objects. We show how this model outperforms state-of-the-art methods in a variety of next-step prediction tasks ranging from grid-world environments to Atari 2600 games. Particularly, we challenge methods that model the dynamics with Graph Neural Networks (GNNs) on top of slotwise representations, and modular architectures that restrict the interactions to be only pairwise. Finally, we show that RSM is able to generalize to scenes with objects varying in number and shape, highlighting its out-of-distribution generalization capabilities. Our implementation is available online\footnote{\hyperlink{https://github.com/trangnnp/RSM}{github.com/trangnnp/RSM}}.
Revisiting Over-smoothing and Over-squashing using Ollivier's Ricci Curvature
Nov 28, 2022



Graph Neural Networks (GNNs) had been demonstrated to be inherently susceptible to the problems of over-smoothing and over-squashing. These issues prohibit the ability of GNNs to model complex graph interactions by limiting their effectiveness at taking into account distant information. Our study reveals the key connection between the local graph geometry and the occurrence of both of these issues, thereby providing a unified framework for studying them at a local scale using the Ollivier's Ricci curvature. Based on our theory, a number of principled methods are proposed to alleviate the over-smoothing and over-squashing issues.
Improving Generative Flow Networks with Path Regularization
Sep 29, 2022
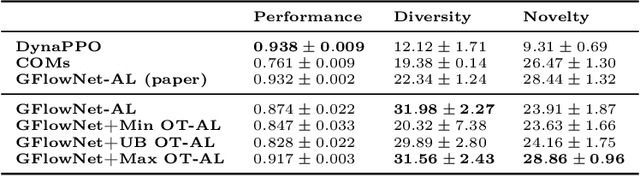
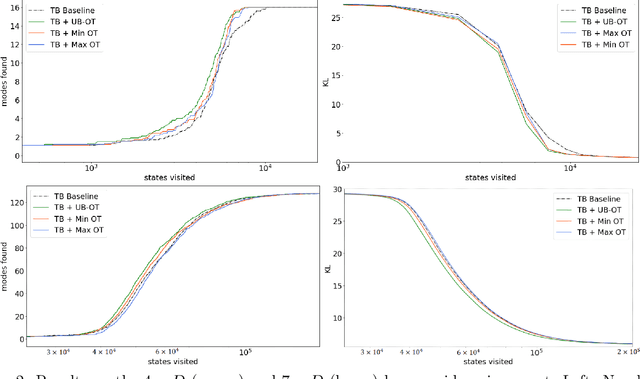
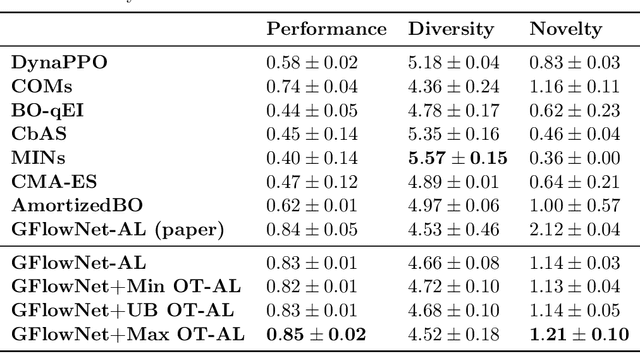
Generative Flow Networks (GFlowNets) are recently proposed models for learning stochastic policies that generate compositional objects by sequences of actions with the probability proportional to a given reward function. The central problem of GFlowNets is to improve their exploration and generalization. In this work, we propose a novel path regularization method based on optimal transport theory that places prior constraints on the underlying structure of the GFlowNets. The prior is designed to help the GFlowNets better discover the latent structure of the target distribution or enhance its ability to explore the environment in the context of active learning. The path regularization controls the flow in GFlowNets to generate more diverse and novel candidates via maximizing the optimal transport distances between two forward policies or to improve the generalization via minimizing the optimal transport distances. In addition, we derive an efficient implementation of the regularization by finding its closed form solutions in specific cases and a meaningful upper bound that can be used as an approximation to minimize the regularization term. We empirically demonstrate the advantage of our path regularization on a wide range of tasks, including synthetic hypergrid environment modeling, discrete probabilistic modeling, and biological sequence design.
Transformer with a Mixture of Gaussian Keys
Oct 16, 2021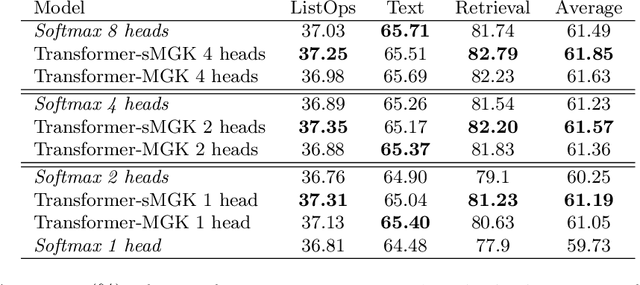

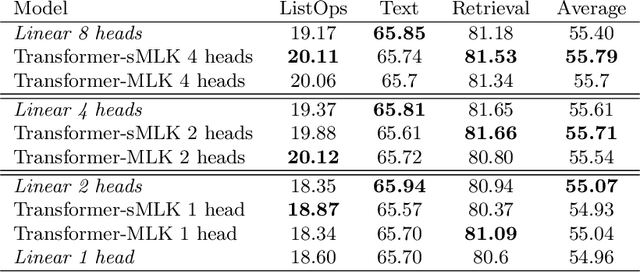

Multi-head attention is a driving force behind state-of-the-art transformers which achieve remarkable performance across a variety of natural language processing (NLP) and computer vision tasks. It has been observed that for many applications, those attention heads learn redundant embedding, and most of them can be removed without degrading the performance of the model. Inspired by this observation, we propose Transformer with a Mixture of Gaussian Keys (Transformer-MGK), a novel transformer architecture that replaces redundant heads in transformers with a mixture of keys at each head. These mixtures of keys follow a Gaussian mixture model and allow each attention head to focus on different parts of the input sequence efficiently. Compared to its conventional transformer counterpart, Transformer-MGK accelerates training and inference, has fewer parameters, and requires less FLOPs to compute while achieving comparable or better accuracy across tasks. Transformer-MGK can also be easily extended to use with linear attentions. We empirically demonstrate the advantage of Transformer-MGK in a range of practical applications including language modeling and tasks that involve very long sequences. On the Wikitext-103 and Long Range Arena benchmark, Transformer-MGKs with 4 heads attain comparable or better performance to the baseline transformers with 8 heads.
Emergence of Different Modes of Tool Use in a Reaching and Dragging Task
Dec 08, 2020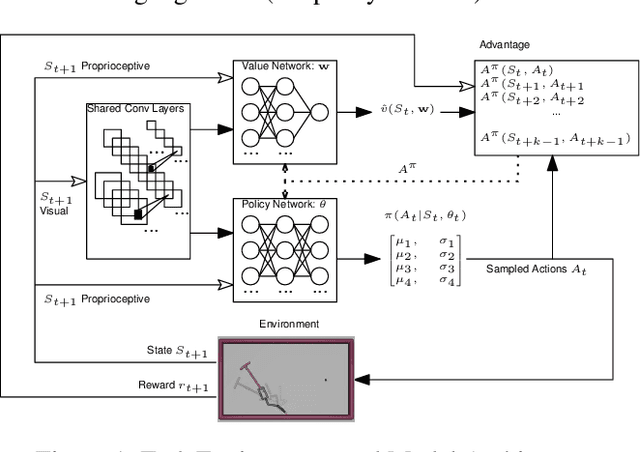
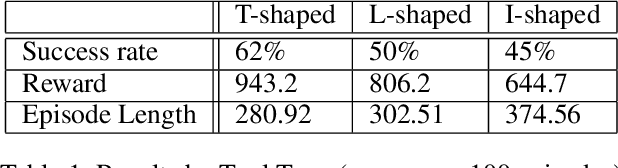
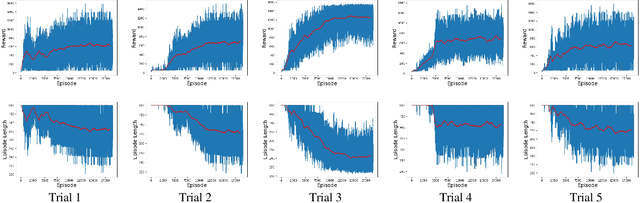

Tool use is an important milestone in the evolution of intelligence. In this paper, we investigate different modes of tool use that emerge in a reaching and dragging task. In this task, a jointed arm with a gripper must grab a tool (T, I, or L-shaped) and drag an object down to the target location (the bottom of the arena). The simulated environment had real physics such as gravity and friction. We trained a deep-reinforcement learning based controller (with raw visual and proprioceptive input) with minimal reward shaping information to tackle this task. We observed the emergence of a wide range of unexpected behaviors, not directly encoded in the motor primitives or reward functions. Examples include hitting the object to the target location, correcting error of initial contact, throwing the tool toward the object, as well as normal expected behavior such as wide sweep. Also, we further analyzed these behaviors based on the type of tool and the initial position of the target object. Our results show a rich repertoire of behaviors, beyond the basic built-in mechanisms of the deep reinforcement learning method we used.