 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Based Navigation for Indoor Mobile Robots
May 28, 2026This paper presents a learning-based navigation framework for indoor mobile robots. The proposed method combines a supervised neural global planner, trained from cost-aware A* expert trajectories, with the proposed Learning-Based DWA local planner, which is formulated as discrete candidate selection over the Dynamic Window Approach (DWA) action lattice. For local planning, the policy is first trained by behavior cloning and then refined by Proximal Policy Optimization (PPO) under feasibility-aware masking. The framework is implemented and evaluated in both simulated and real-world indoor environments. Experimental results show that the proposed method generates feasible global routes and reliable local motion commands for safe goal-directed navigation in the presence of obstacles. These results demonstrate the effectiveness of integrating learning-based global planning with reinforcement-learning-refined local control for indoor mobile robot navigation. The source code will be released at https://ntdathp.github.io/rl_robot_web/.
STR Robot: Design of an Autonomous Mobile Robot from Simulation to Reality
May 27, 2026With the rapid development of simulation tools, the development and validation of autonomous robotic systems have become more efficient before real-world deployment. This paper presents a simulation-to-real implementation of an autonomous mobile robot based on an existing mechanical platform. Instead of focusing on mechanical design, our work concentrates on the development of the onboard control, self-localization, and autonomous navigation system. The proposed robot is equipped with onboard sensing and computation to estimate its pose and navigate autonomously in the environment. The overall framework is first developed and tested in simulation, and then deployed on the real robot for experimental evaluation. The results demonstrate the feasibility of the proposed approach and show that simulation provides an effective foundation for developing reliable autonomous mobile robot systems. The source code will be released at https://ntdathp.github.io/outdoor-robot-web.
Few-Shot VLM-Based G-Code and HMI Verification in CNC Machining
Dec 12, 2025Manual generation of G-code is important for learning the operation of CNC machines. Prior work in G-code verification uses Large-Language Models (LLMs), which primarily examine errors in the written programming. However, CNC machining requires extensive use and knowledge of the Human-Machine Interface (HMI), which displays machine status and errors. LLMs currently lack the capability to leverage knowledge of HMIs due to their inability to access the vision modality. This paper proposes a few-shot VLM-based verification approach that simultaneously evaluates the G-code and the HMI display for errors and safety status. The input dataset includes paired G-code text and associated HMI screenshots from a 15-slant-PRO lathe, including both correct and error-prone cases. To enable few-shot learning, the VLM is provided with a structured JSON schema based on prior heuristic knowledge. After determining the prompts, instances of G-code and HMI that either contain errors or are error free are used as few-shot examples to guide the VLM. The model was then evaluated in comparison to a zero-shot VLM through multiple scenarios of incorrect G-code and HMI errors with respect to per-slot accuracy. The VLM showed that few-shot prompting led to overall enhancement of detecting HMI errors and discrepancies with the G-code for more comprehensive debugging. Therefore, the proposed framework was demonstrated to be suitable for verification of manually generated G-code that is typically developed in CNC training.
Vision-Language Models for Infrared Industrial Sensing in Additive Manufacturing Scene Description
Dec 11, 2025Many manufacturing environments operate in low-light conditions or within enclosed machines where conventional vision systems struggle. Infrared cameras provide complementary advantages in such environments. Simultaneously, supervised AI systems require large labeled datasets, which makes zero-shot learning frameworks more practical for applications including infrared cameras. Recent advances in vision-language foundation models (VLMs) offer a new path in zero-shot predictions from paired image-text representations. However, current VLMs cannot understand infrared camera data since they are trained on RGB data. This work introduces VLM-IRIS (Vision-Language Models for InfraRed Industrial Sensing), a zero-shot framework that adapts VLMs to infrared data by preprocessing infrared images captured by a FLIR Boson sensor into RGB-compatible inputs suitable for CLIP-based encoders. We demonstrate zero-shot workpiece presence detection on a 3D printer bed where temperature differences between the build plate and workpieces make the task well-suited for thermal imaging. VLM-IRIS converts the infrared images to magma representation and applies centroid prompt ensembling with a CLIP ViT-B/32 encoder to achieve high accuracy on infrared images without any model retraining. These findings demonstrate that the proposed improvements to VLMs can be effectively extended to thermal applications for label-free monitoring.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
Multimodal Object Detection using Depth and Image Data for Manufacturing Parts
Nov 13, 2024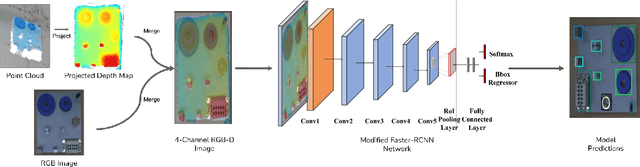
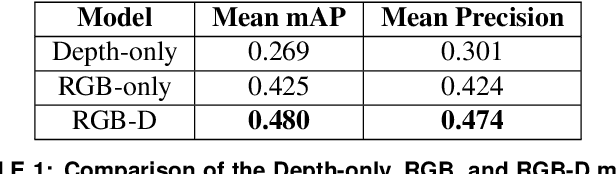
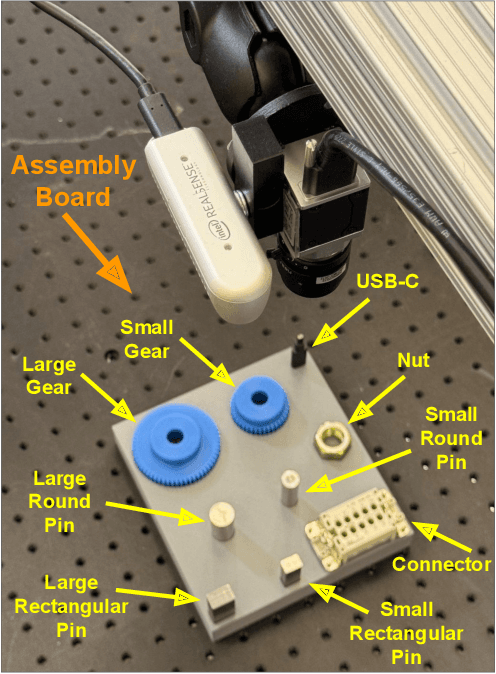

Manufacturing requires reliable object detection methods for precise picking and handling of diverse types of manufacturing parts and components. Traditional object detection methods utilize either only 2D images from cameras or 3D data from lidars or similar 3D sensors. However, each of these sensors have weaknesses and limitations. Cameras do not have depth perception and 3D sensors typically do not carry color information. These weaknesses can undermine the reliability and robustness of industrial manufacturing systems. To address these challenges, this work proposes a multi-sensor system combining an red-green-blue (RGB) camera and a 3D point cloud sensor. The two sensors are calibrated for precise alignment of the multimodal data captured from the two hardware devices. A novel multimodal object detection method is developed to process both RGB and depth data. This object detector is based on the Faster R-CNN baseline that was originally designed to process only camera images. The results show that the multimodal model significantly outperforms the depth-only and RGB-only baselines on established object detection metrics. More specifically, the multimodal model improves mAP by 13% and raises Mean Precision by 11.8% in comparison to the RGB-only baseline. Compared to the depth-only baseline, it improves mAP by 78% and raises Mean Precision by 57%. Hence, this method facilitates more reliable and robust object detection in service to smart manufacturing applications.
PerspectiveNet: Multi-View Perception for Dynamic Scene Understanding
Oct 22, 2024
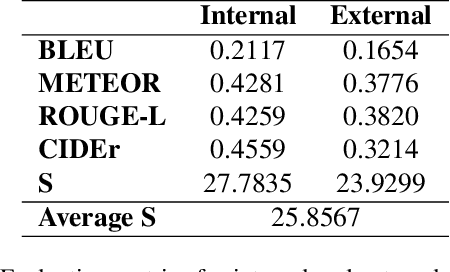


Generating detailed descriptions from multiple cameras and viewpoints is challenging due to the complex and inconsistent nature of visual data. In this paper, we introduce PerspectiveNet, a lightweight yet efficient model for generating long descriptions across multiple camera views. Our approach utilizes a vision encoder, a compact connector module to convert visual features into a fixed-size tensor, and large language models (LLMs) to harness the strong natural language generation capabilities of LLMs. The connector module is designed with three main goals: mapping visual features onto LLM embeddings, emphasizing key information needed for description generation, and producing a fixed-size feature matrix. Additionally, we augment our solution with a secondary task, the correct frame sequence detection, enabling the model to search for the correct sequence of frames to generate descriptions. Finally, we integrate the connector module, the secondary task, the LLM, and a visual feature extraction model into a single architecture, which is trained for the Traffic Safety Description and Analysis task. This task requires generating detailed, fine-grained descriptions of events from multiple cameras and viewpoints. The resulting model is lightweight, ensuring efficient training and inference, while remaining highly effective.
Solving the Right Problem is Key for Translational NLP: A Case Study in UMLS Vocabulary Insertion
Nov 25, 2023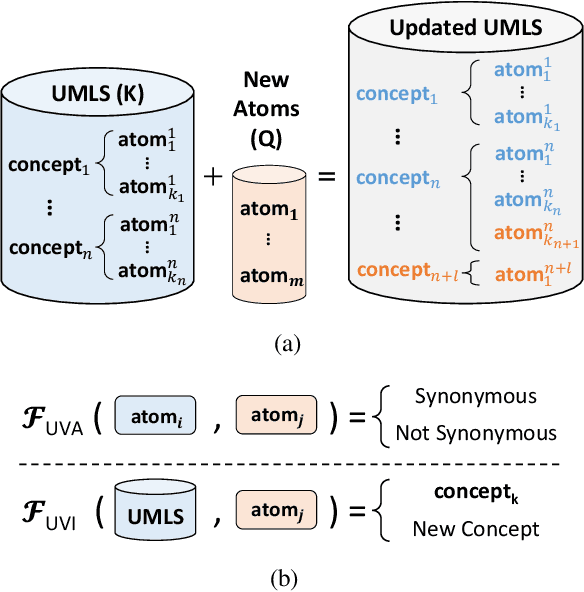
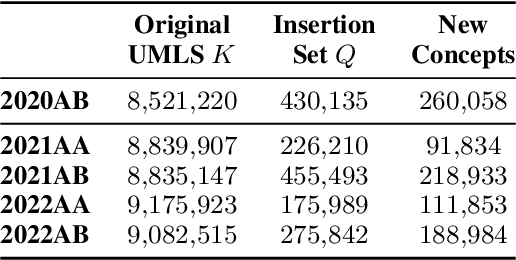
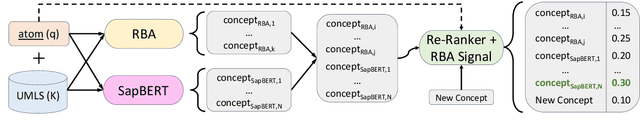

As the immense opportunities enabled by large language models become more apparent, NLP systems will be increasingly expected to excel in real-world settings. However, in many instances, powerful models alone will not yield translational NLP solutions, especially if the formulated problem is not well aligned with the real-world task. In this work, we study the case of UMLS vocabulary insertion, an important real-world task in which hundreds of thousands of new terms, referred to as atoms, are added to the UMLS, one of the most comprehensive open-source biomedical knowledge bases. Previous work aimed to develop an automated NLP system to make this time-consuming, costly, and error-prone task more efficient. Nevertheless, practical progress in this direction has been difficult to achieve due to a problem formulation and evaluation gap between research output and the real-world task. In order to address this gap, we introduce a new formulation for UMLS vocabulary insertion which mirrors the real-world task, datasets which faithfully represent it and several strong baselines we developed through re-purposing existing solutions. Additionally, we propose an effective rule-enhanced biomedical language model which enables important new model behavior, outperforms all strong baselines and provides measurable qualitative improvements to editors who carry out the UVI task. We hope this case study provides insight into the considerable importance of problem formulation for the success of translational NLP solutions.
From Coupled Oscillators to Graph Neural Networks: Reducing Over-smoothing via a Kuramoto Model-based Approach
Nov 06, 2023



We propose the Kuramoto Graph Neural Network (KuramotoGNN), a novel class of continuous-depth graph neural networks (GNNs) that employs the Kuramoto model to mitigate the over-smoothing phenomenon, in which node features in GNNs become indistinguishable as the number of layers increases. The Kuramoto model captures the synchronization behavior of non-linear coupled oscillators. Under the view of coupled oscillators, we first show the connection between Kuramoto model and basic GNN and then over-smoothing phenomenon in GNNs can be interpreted as phase synchronization in Kuramoto model. The KuramotoGNN replaces this phase synchronization with frequency synchronization to prevent the node features from converging into each other while allowing the system to reach a stable synchronized state. We experimentally verify the advantages of the KuramotoGNN over the baseline GNNs and existing methods in reducing over-smoothing on various graph deep learning benchmark tasks.
p-Laplacian Transformer
Nov 06, 2023
$p$-Laplacian regularization, rooted in graph and image signal processing, introduces a parameter $p$ to control the regularization effect on these data. Smaller values of $p$ promote sparsity and interpretability, while larger values encourage smoother solutions. In this paper, we first show that the self-attention mechanism obtains the minimal Laplacian regularization ($p=2$) and encourages the smoothness in the architecture. However, the smoothness is not suitable for the heterophilic structure of self-attention in transformers where attention weights between tokens that are in close proximity and non-close ones are assigned indistinguishably. From that insight, we then propose a novel class of transformers, namely the $p$-Laplacian Transformer (p-LaT), which leverages $p$-Laplacian regularization framework to harness the heterophilic features within self-attention layers. In particular, low $p$ values will effectively assign higher attention weights to tokens that are in close proximity to the current token being processed. We empirically demonstrate the advantages of p-LaT over the baseline transformers on a wide range of benchmark datasets.