 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Nov 16, 2024



Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated. We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories. ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
Towards Infusing Auxiliary Knowledge for Distracted Driver Detection
Aug 29, 2024



Distracted driving is a leading cause of road accidents globally. Identification of distracted driving involves reliably detecting and classifying various forms of driver distraction (e.g., texting, eating, or using in-car devices) from in-vehicle camera feeds to enhance road safety. This task is challenging due to the need for robust models that can generalize to a diverse set of driver behaviors without requiring extensive annotated datasets. In this paper, we propose KiD3, a novel method for distracted driver detection (DDD) by infusing auxiliary knowledge about semantic relations between entities in a scene and the structural configuration of the driver's pose. Specifically, we construct a unified framework that integrates the scene graphs, and driver pose information with the visual cues in video frames to create a holistic representation of the driver's actions.Our results indicate that KiD3 achieves a 13.64% accuracy improvement over the vision-only baseline by incorporating such auxiliary knowledge with visual information.
CausalDisco: Causal discovery using knowledge graph link prediction
Apr 23, 2024
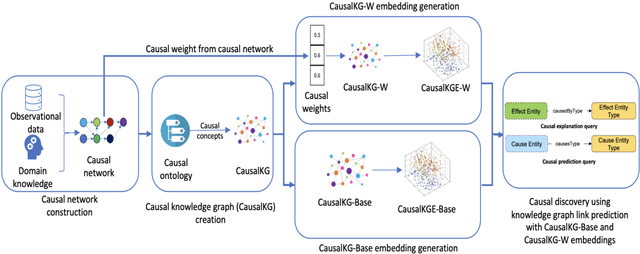

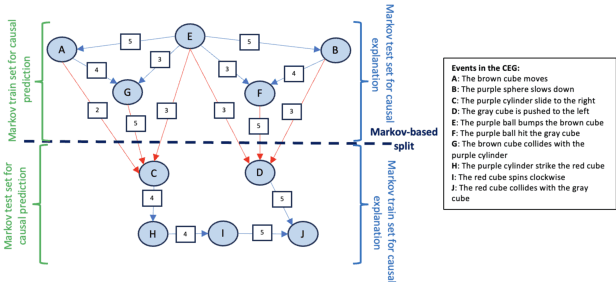
Causal discovery is a process of discovering new causal relations from observational data. Traditional causal discovery methods often suffer from issues related to missing data To address these issues, this paper presents a novel approach called CausalDisco that formulates causal discovery as a knowledge graph completion problem. More specifically, the task of discovering causal relations is mapped to the task of knowledge graph link prediction. CausalDisco supports two types of discovery: causal explanation and causal prediction. The causal relations have weights representing the strength of the causal association between entities in the knowledge graph. An evaluation of this approach uses a benchmark dataset of simulated videos for causal reasoning, CLEVRER-Humans, and compares the performance of multiple knowledge graph embedding algorithms. In addition, two distinct dataset splitting approaches are utilized within the evaluation: (1) random-based split, which is the method typically used to evaluate link prediction algorithms, and (2) Markov-based split, a novel data split technique for evaluating link prediction that utilizes the Markovian property of the causal relation. Results show that using weighted causal relations improves causal discovery over the baseline without weighted relations.
FACTOID: FACtual enTailment fOr hallucInation Detection
Mar 28, 2024The widespread adoption of Large Language Models (LLMs) has facilitated numerous benefits. However, hallucination is a significant concern. In response, Retrieval Augmented Generation (RAG) has emerged as a highly promising paradigm to improve LLM outputs by grounding them in factual information. RAG relies on textual entailment (TE) or similar methods to check if the text produced by LLMs is supported or contradicted, compared to retrieved documents. This paper argues that conventional TE methods are inadequate for spotting hallucinations in content generated by LLMs. For instance, consider a prompt about the 'USA's stance on the Ukraine war''. The AI-generated text states, ...U.S. President Barack Obama says the U.S. will not put troops in Ukraine...'' However, during the war the U.S. president is Joe Biden which contradicts factual reality. Moreover, current TE systems are unable to accurately annotate the given text and identify the exact portion that is contradicted. To address this, we introduces a new type of TE called ``Factual Entailment (FE).'', aims to detect factual inaccuracies in content generated by LLMs while also highlighting the specific text segment that contradicts reality. We present FACTOID (FACTual enTAILment for hallucInation Detection), a benchmark dataset for FE. We propose a multi-task learning (MTL) framework for FE, incorporating state-of-the-art (SoTA) long text embeddings such as e5-mistral-7b-instruct, along with GPT-3, SpanBERT, and RoFormer. The proposed MTL architecture for FE achieves an avg. 40\% improvement in accuracy on the FACTOID benchmark compared to SoTA TE methods. As FE automatically detects hallucinations, we assessed 15 modern LLMs and ranked them using our proposed Auto Hallucination Vulnerability Index (HVI_auto). This index quantifies and offers a comparative scale to evaluate and rank LLMs according to their hallucinations.
"Sorry, Come Again?" Prompting -- Enhancing Comprehension and Diminishing Hallucination with [PAUSE]-injected Optimal Paraphrasing
Mar 27, 2024Hallucination has emerged as the most vulnerable aspect of contemporary Large Language Models (LLMs). In this paper, we introduce the Sorry, Come Again (SCA) prompting, aimed to avoid LLM hallucinations by enhancing comprehension through: (i) optimal paraphrasing and (ii) injecting [PAUSE] tokens to delay LLM generation. First, we provide an in-depth analysis of linguistic nuances: formality, readability, and concreteness of prompts for 21 LLMs, and elucidate how these nuances contribute to hallucinated generation. Prompts with lower readability, formality, or concreteness pose comprehension challenges for LLMs, similar to those faced by humans. In such scenarios, an LLM tends to speculate and generate content based on its imagination (associative memory) to fill these information gaps. Although these speculations may occasionally align with factual information, their accuracy is not assured, often resulting in hallucination. Recent studies reveal that an LLM often neglects the middle sections of extended prompts, a phenomenon termed as lost in the middle. While a specific paraphrase may suit one LLM, the same paraphrased version may elicit a different response from another LLM. Therefore, we propose an optimal paraphrasing technique to identify the most comprehensible paraphrase of a given prompt, evaluated using Integrated Gradient (and its variations) to guarantee that the LLM accurately processes all words. While reading lengthy sentences, humans often pause at various points to better comprehend the meaning read thus far. We have fine-tuned an LLM with injected [PAUSE] tokens, allowing the LLM to pause while reading lengthier prompts. This has brought several key contributions: (i) determining the optimal position to inject [PAUSE], (ii) determining the number of [PAUSE] tokens to be inserted, and (iii) introducing reverse proxy tuning to fine-tune the LLM for [PAUSE] insertion.
Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think -- Introducing AI Detectability Index
Oct 24, 2023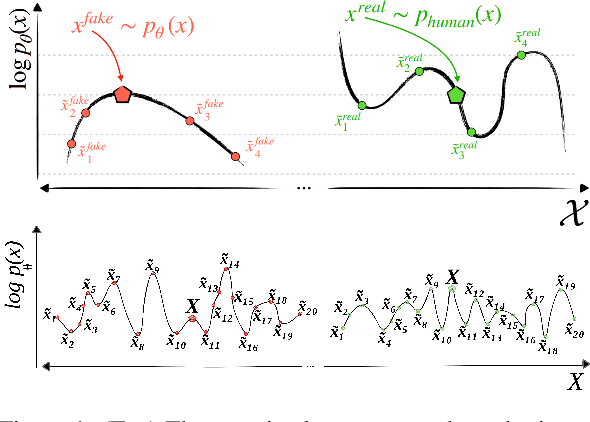



With the rise of prolific ChatGPT, the risk and consequences of AI-generated text has increased alarmingly. To address the inevitable question of ownership attribution for AI-generated artifacts, the US Copyright Office released a statement stating that 'If a work's traditional elements of authorship were produced by a machine, the work lacks human authorship and the Office will not register it'. Furthermore, both the US and the EU governments have recently drafted their initial proposals regarding the regulatory framework for AI. Given this cynosural spotlight on generative AI, AI-generated text detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by emergence of techniques to bypass detection. This paper introduces the Counter Turing Test (CT^2), a benchmark consisting of techniques aiming to offer a comprehensive evaluation of the robustness of existing AGTD techniques. Our empirical findings unequivocally highlight the fragility of the proposed AGTD methods under scrutiny. Amidst the extensive deliberations on policy-making for regulating AI development, it is of utmost importance to assess the detectability of content generated by LLMs. Thus, to establish a quantifiable spectrum facilitating the evaluation and ranking of LLMs according to their detectability levels, we propose the AI Detectability Index (ADI). We conduct a thorough examination of 15 contemporary LLMs, empirically demonstrating that larger LLMs tend to have a higher ADI, indicating they are less detectable compared to smaller LLMs. We firmly believe that ADI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making.
The Troubling Emergence of Hallucination in Large Language Models -- An Extensive Definition, Quantification, and Prescriptive Remediations
Oct 08, 2023The recent advancements in Large Language Models (LLMs) have garnered widespread acclaim for their remarkable emerging capabilities. However, the issue of hallucination has parallelly emerged as a by-product, posing significant concerns. While some recent endeavors have been made to identify and mitigate different types of hallucination, there has been a limited emphasis on the nuanced categorization of hallucination and associated mitigation methods. To address this gap, we offer a fine-grained discourse on profiling hallucination based on its degree, orientation, and category, along with offering strategies for alleviation. As such, we define two overarching orientations of hallucination: (i) factual mirage (FM) and (ii) silver lining (SL). To provide a more comprehensive understanding, both orientations are further sub-categorized into intrinsic and extrinsic, with three degrees of severity - (i) mild, (ii) moderate, and (iii) alarming. We also meticulously categorize hallucination into six types: (i) acronym ambiguity, (ii) numeric nuisance, (iii) generated golem, (iv) virtual voice, (v) geographic erratum, and (vi) time wrap. Furthermore, we curate HallucInation eLiciTation (HILT), a publicly available dataset comprising of 75,000 samples generated using 15 contemporary LLMs along with human annotations for the aforementioned categories. Finally, to establish a method for quantifying and to offer a comparative spectrum that allows us to evaluate and rank LLMs based on their vulnerability to producing hallucinations, we propose Hallucination Vulnerability Index (HVI). We firmly believe that HVI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making. In conclusion, we propose two solution strategies for mitigating hallucinations.
UBERT: A Novel Language Model for Synonymy Prediction at Scale in the UMLS Metathesaurus
Apr 27, 2022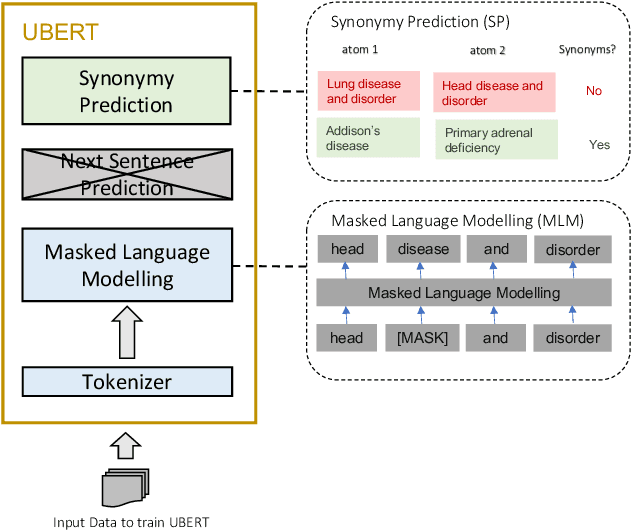
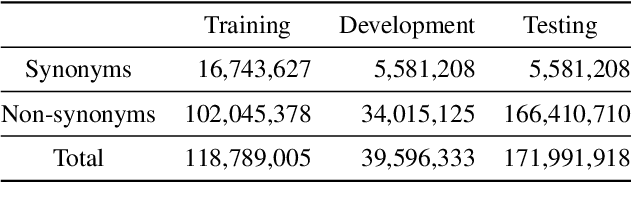
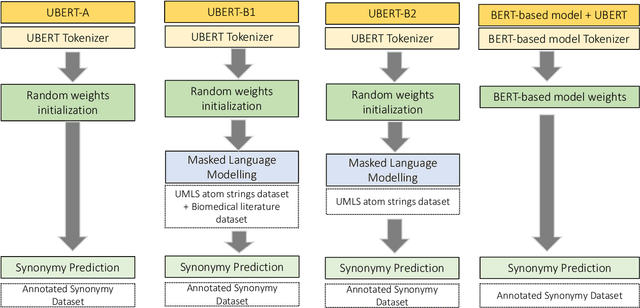

The UMLS Metathesaurus integrates more than 200 biomedical source vocabularies. During the Metathesaurus construction process, synonymous terms are clustered into concepts by human editors, assisted by lexical similarity algorithms. This process is error-prone and time-consuming. Recently, a deep learning model (LexLM) has been developed for the UMLS Vocabulary Alignment (UVA) task. This work introduces UBERT, a BERT-based language model, pretrained on UMLS terms via a supervised Synonymy Prediction (SP) task replacing the original Next Sentence Prediction (NSP) task. The effectiveness of UBERT for UMLS Metathesaurus construction process is evaluated using the UMLS Vocabulary Alignment (UVA) task. We show that UBERT outperforms the LexLM, as well as biomedical BERT-based models. Key to the performance of UBERT are the synonymy prediction task specifically developed for UBERT, the tight alignment of training data to the UVA task, and the similarity of the models used for pretrained UBERT.
CEVO: Comprehensive EVent Ontology Enhancing Cognitive Annotation
Oct 03, 2018
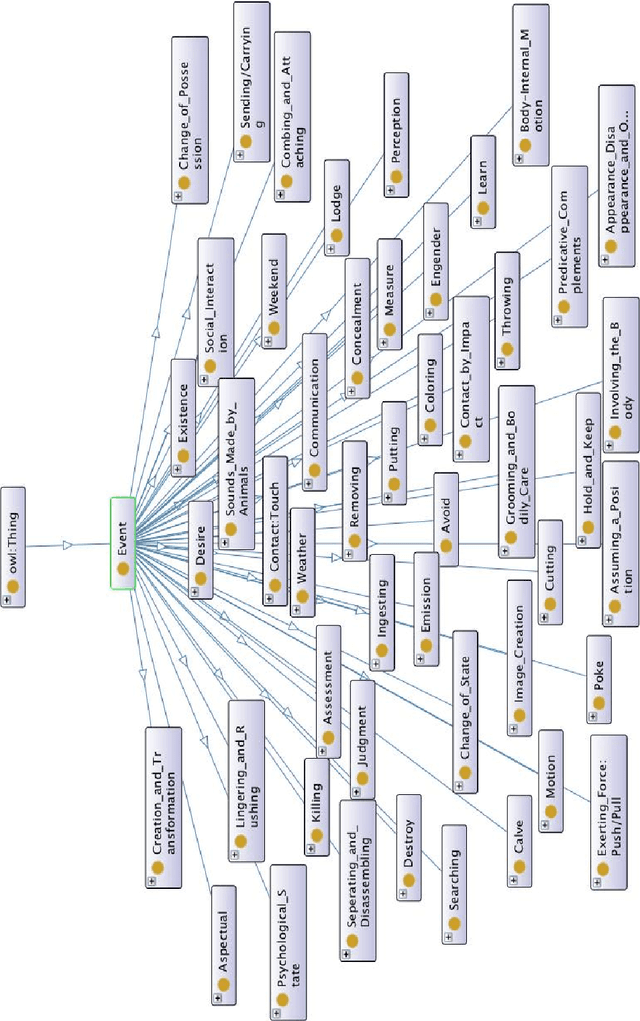
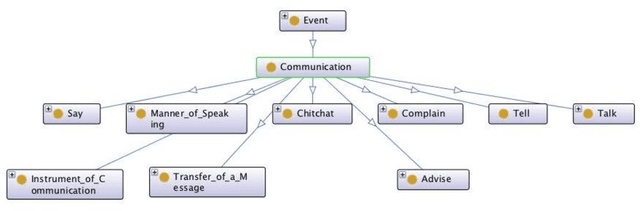
While the general analysis of named entities has received substantial research attention on unstructured as well as structured data, the analysis of relations among named entities has received limited focus. In fact, a review of the literature revealed a deficiency in research on the abstract conceptualization required to organize relations. We believe that such an abstract conceptualization can benefit various communities and applications such as natural language processing, information extraction, machine learning, and ontology engineering. In this paper, we present Comprehensive EVent Ontology (CEVO), built on Levin's conceptual hierarchy of English verbs that categorizes verbs with shared meaning, and syntactic behavior. We present the fundamental concepts and requirements for this ontology. Furthermore, we present three use cases employing the CEVO ontology on annotation tasks: (i) annotating relations in plain text, (ii) annotating ontological properties, and (iii) linking textual relations to ontological properties. These use-cases demonstrate the benefits of using CEVO for annotation: (i) annotating English verbs from an abstract conceptualization, (ii) playing the role of an upper ontology for organizing ontological properties, and (iii) facilitating the annotation of text relations using any underlying vocabulary. This resource is available at https://shekarpour.github.io/cevo.io/ using https://w3id.org/cevo namespace.
Machine learning for Internet of Things data analysis: A survey
Feb 17, 2018
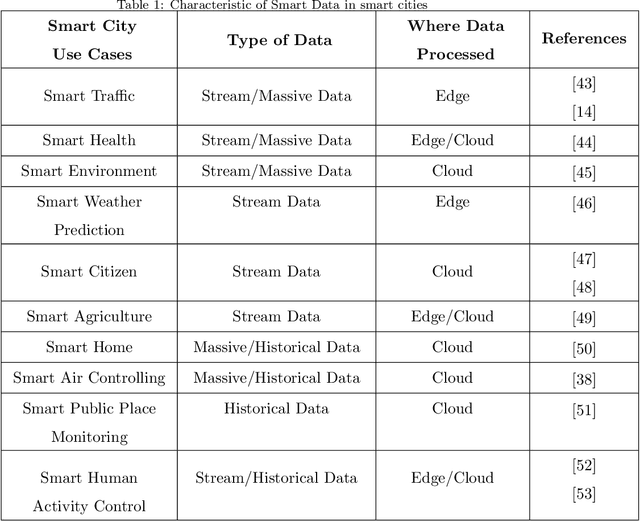
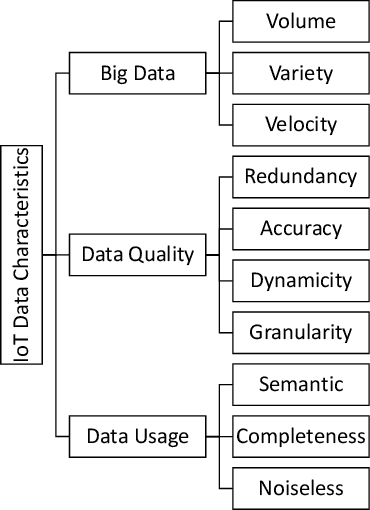
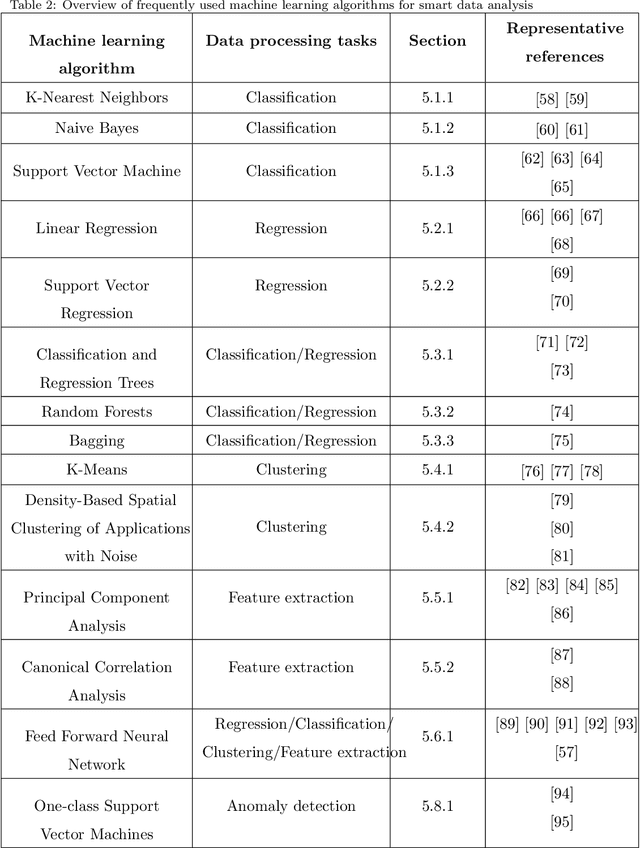
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.