 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and learning the language for different types of harassment
Nov 01, 2018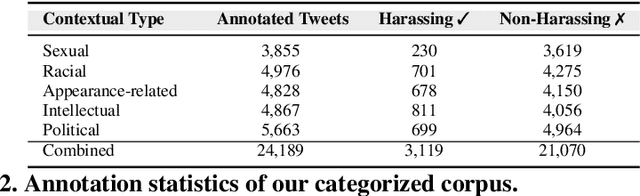
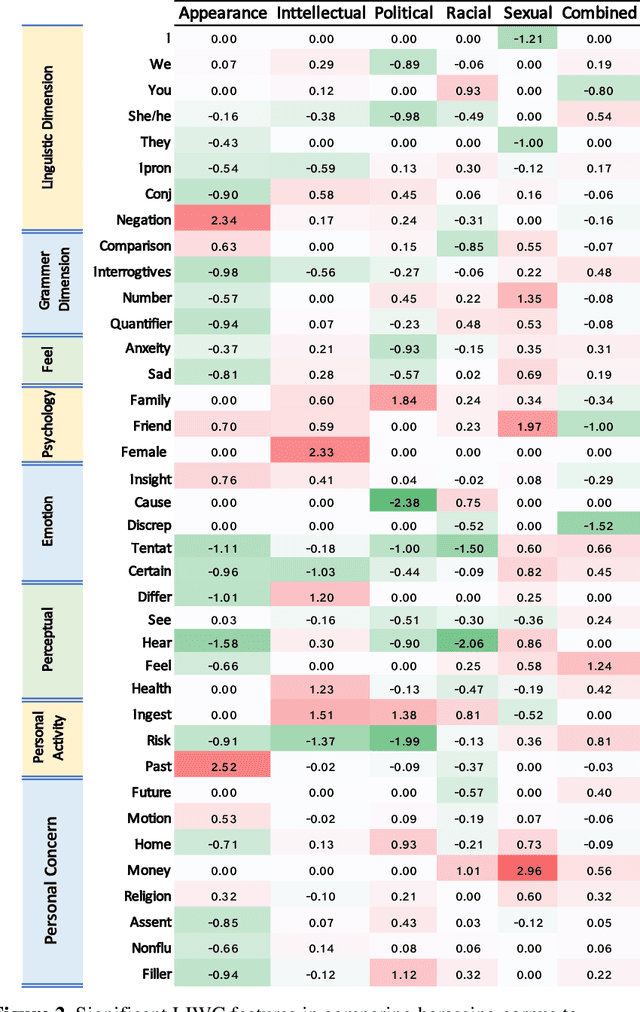
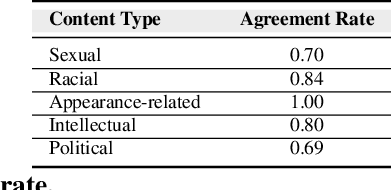
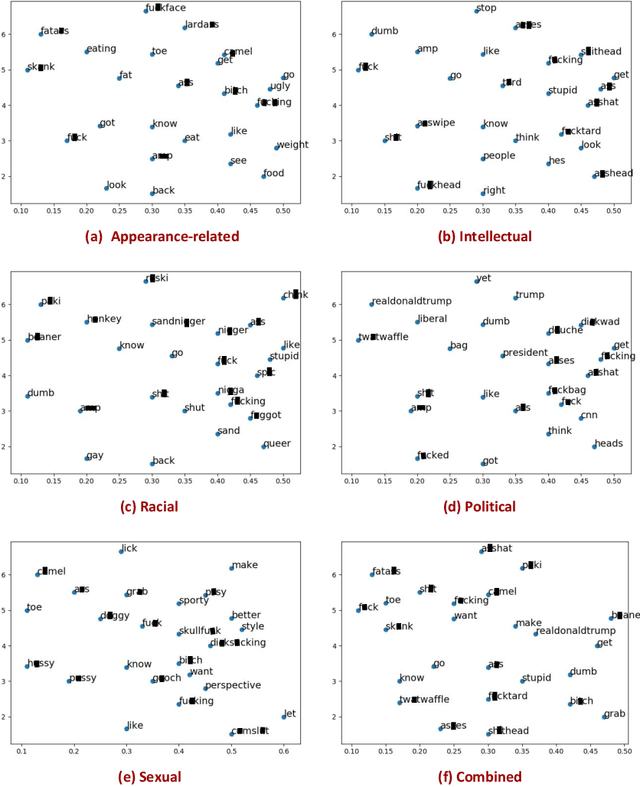
The presence of a significant amount of harassment in user-generated content and its negative impact calls for robust automatic detection approaches. This requires that we can identify different forms or types of harassment. Earlier work has classified harassing language in terms of hurtfulness, abusiveness, sentiment, and profanity. However, to identify and understand harassment more accurately, it is essential to determine the context that represents the interrelated conditions in which they occur. In this paper, we introduce the notion of contextual type to harassment involving five categories: (i) sexual, (ii) racial, (iii) appearance-related, (iv) intellectual and (v) political. We utilize an annotated corpus from Twitter distinguishing these types of harassment. To study the context for each type that sheds light on the linguistic meaning, interpretation, and distribution, we conduct two lines of investigation: an extensive linguistic analysis, and a statistical distribution of unigrams. We then build type-ware classifiers to automate the identification of type-specific harassment. Our experiments demonstrate that these classifiers provide competitive accuracy for identifying and analyzing harassment on social media. We present extensive discussion and major observations about the effectiveness of type-aware classifiers using a detailed comparison setup providing insight into the role of type-dependent features.
A Quality Type-aware Annotated Corpus and Lexicon for Harassment Research
May 23, 2018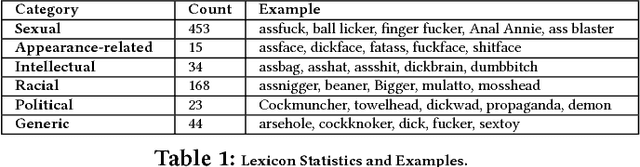
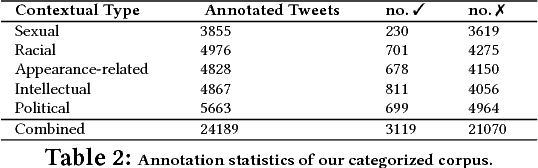

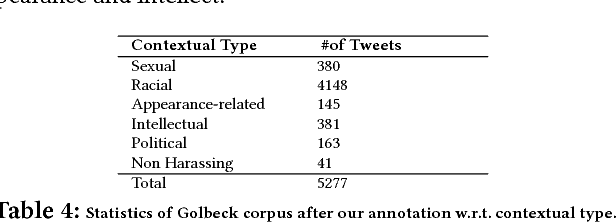
Having a quality annotated corpus is essential especially for applied research. Despite the recent focus of Web science community on researching about cyberbullying, the community dose not still have standard benchmarks. In this paper, we publish first, a quality annotated corpus and second, an offensive words lexicon capturing different types type of harassment as (i) sexual harassment, (ii) racial harassment, (iii) appearance-related harassment, (iv) intellectual harassment, and (v) political harassment.We crawled data from Twitter using our offensive lexicon. Then relied on the human judge to annotate the collected tweets w.r.t. the contextual types because using offensive words is not sufficient to reliably detect harassment. Our corpus consists of 25,000 annotated tweets in five contextual types. We are pleased to share this novel annotated corpus and the lexicon with the research community. The instruction to acquire the corpus has been published on the Git repository.
Machine learning for Internet of Things data analysis: A survey
Feb 17, 2018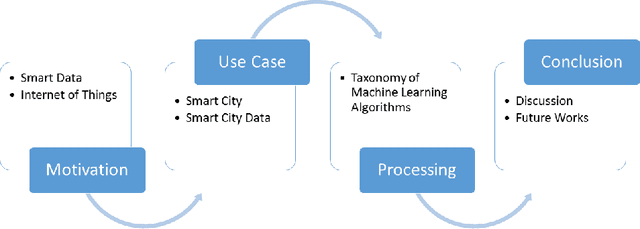
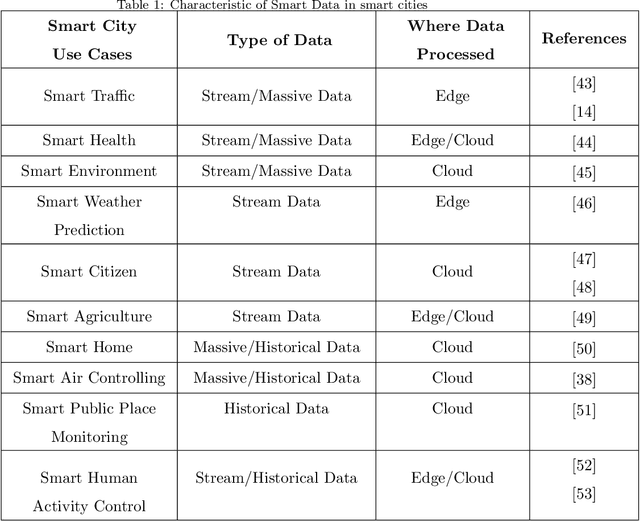
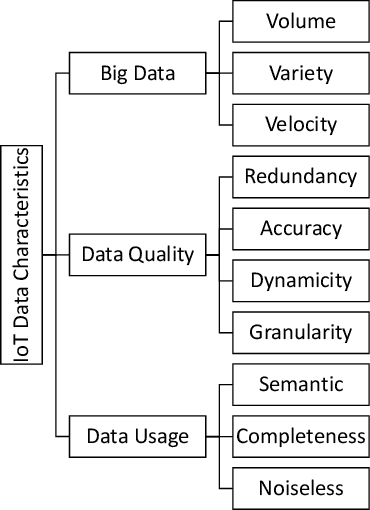
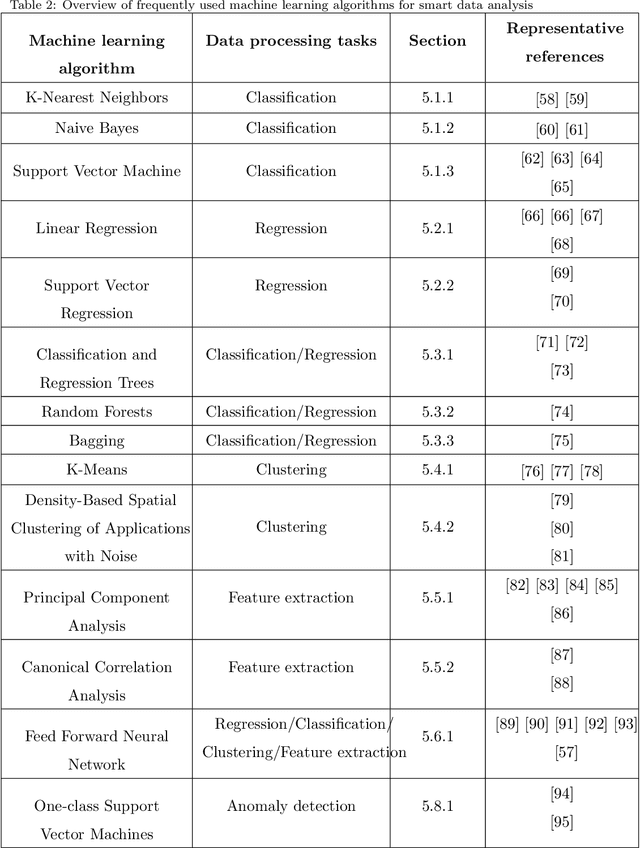
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.