 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHopfE: Knowledge Graph Representation Learning using Inverse Hopf Fibrations
Aug 12, 2021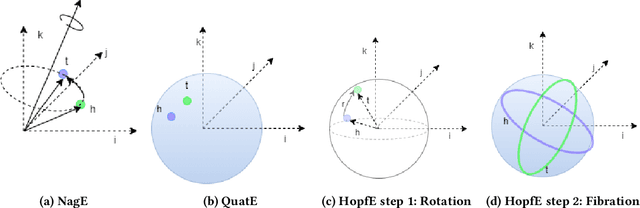

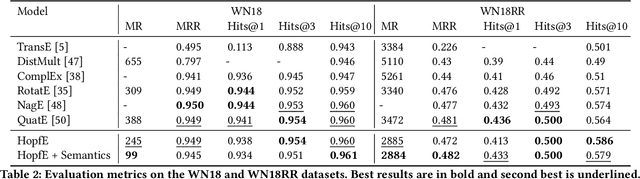
Recently, several Knowledge Graph Embedding (KGE) approaches have been devised to represent entities and relations in dense vector space and employed in downstream tasks such as link prediction. A few KGE techniques address interpretability, i.e., mapping the connectivity patterns of the relations (i.e., symmetric/asymmetric, inverse, and composition) to a geometric interpretation such as rotations. Other approaches model the representations in higher dimensional space such as four-dimensional space (4D) to enhance the ability to infer the connectivity patterns (i.e., expressiveness). However, modeling relation and entity in a 4D space often comes at the cost of interpretability. This paper proposes HopfE, a novel KGE approach aiming to achieve the interpretability of inferred relations in the four-dimensional space. We first model the structural embeddings in 3D Euclidean space and view the relation operator as an SO(3) rotation. Next, we map the entity embedding vector from a 3D space to a 4D hypersphere using the inverse Hopf Fibration, in which we embed the semantic information from the KG ontology. Thus, HopfE considers the structural and semantic properties of the entities without losing expressivity and interpretability. Our empirical results on four well-known benchmarks achieve state-of-the-art performance for the KG completion task.
KGPool: Dynamic Knowledge Graph Context Selection for Relation Extraction
Jun 06, 2021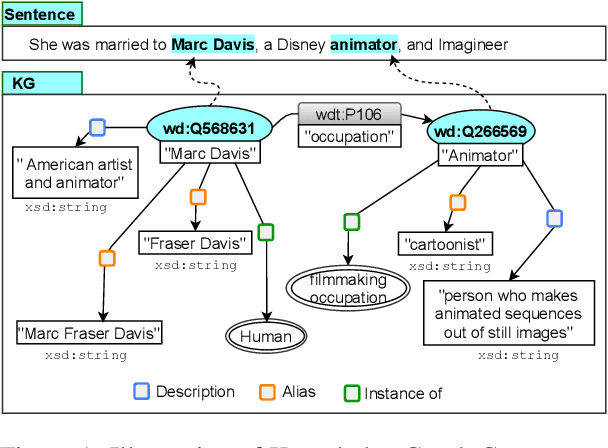
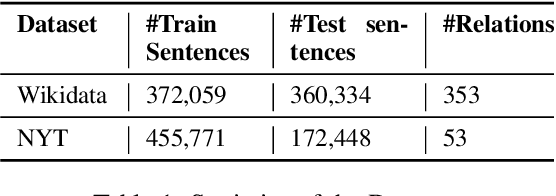
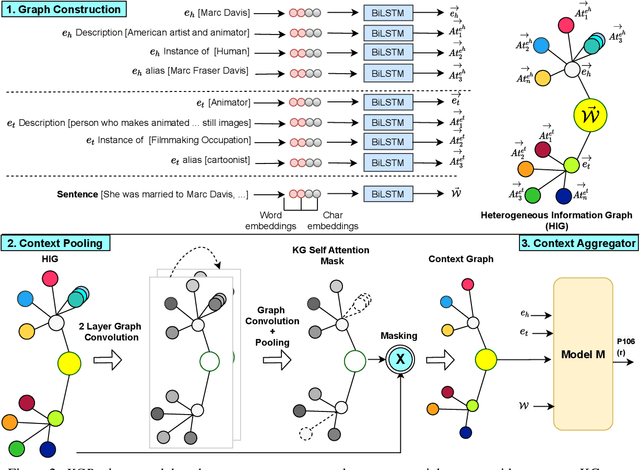
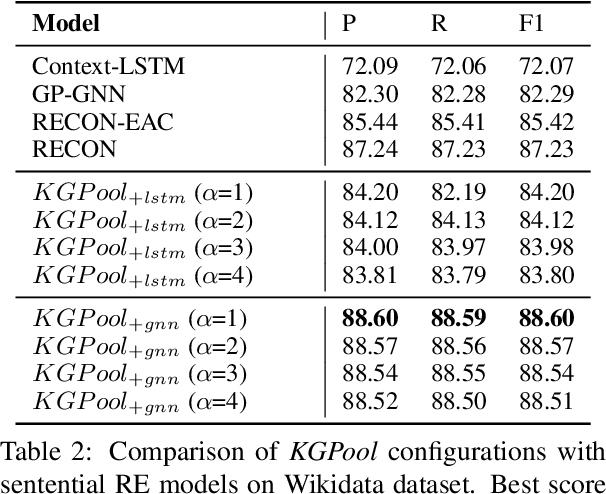
We present a novel method for relation extraction (RE) from a single sentence, mapping the sentence and two given entities to a canonical fact in a knowledge graph (KG). Especially in this presumed sentential RE setting, the context of a single sentence is often sparse. This paper introduces the KGPool method to address this sparsity, dynamically expanding the context with additional facts from the KG. It learns the representation of these facts (entity alias, entity descriptions, etc.) using neural methods, supplementing the sentential context. Unlike existing methods that statically use all expanded facts, KGPool conditions this expansion on the sentence. We study the efficacy of KGPool by evaluating it with different neural models and KGs (Wikidata and NYT Freebase). Our experimental evaluation on standard datasets shows that by feeding the KGPool representation into a Graph Neural Network, the overall method is significantly more accurate than state-of-the-art methods.
Capturing Knowledge of Emerging Entities From Extended Search Snippets
Mar 17, 2021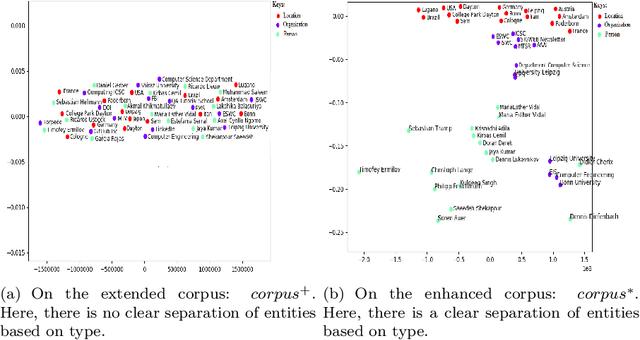

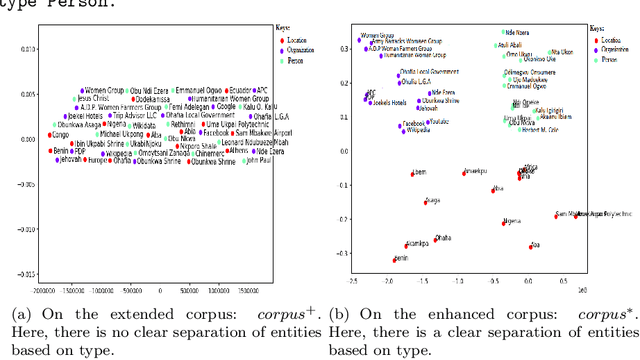
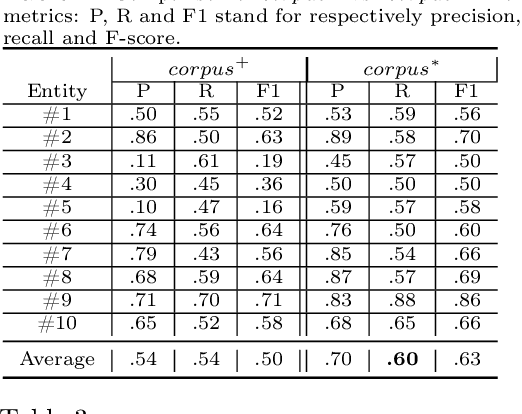
Google and other search engines feature the entity search by representing a knowledge card summarizing related facts about the user-supplied entity. However, the knowledge card is limited to certain entities that have a Wiki page or an entry in encyclopedias such as Freebase. The current encyclopedias are limited to highly popular entities, which are far fewer compared with the emerging entities. Despite the availability of knowledge about the emerging entities on the search results, yet there are no approaches to capture, abstract, summerize, fuse, and validate fragmented pieces of knowledge about them. Thus, in this paper, we develop approaches to capture two types of knowledge about the emerging entities from a corpus extended from top-n search snippets of a given emerging entity. The first kind of knowledge identifies the role(s) of the emerging entity as, e.g., who is s/he? The second kind captures the entities closely associated with the emerging entity. As the testbed, we considered a collection of 20 emerging entities and 20 popular entities as the ground truth. Our approach is an unsupervised approach based on text analysis and entity embeddings. Our experimental studies show promising results as the accuracy of more than $87\%$ for recognizing entities and $75\%$ for ranking them. Besides $87\%$ of the entailed types were recognizable. Our testbed and source code is available on Github https://github.com/sunnyUD/research_source_code.
CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata
Feb 08, 2021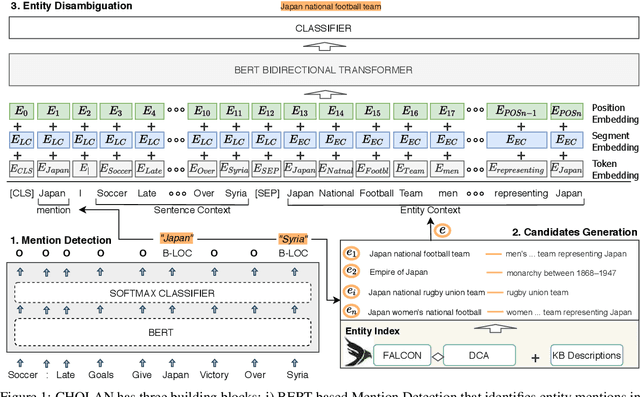
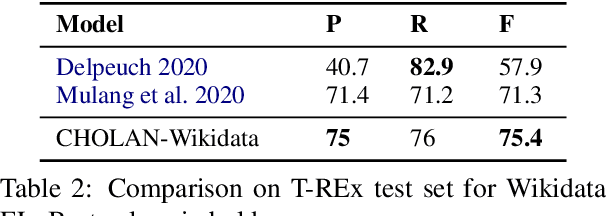
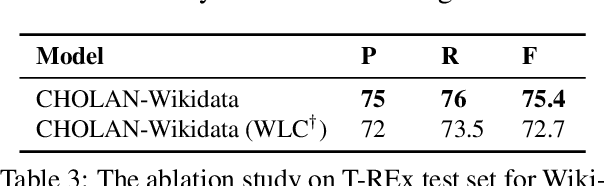
In this paper, we propose CHOLAN, a modular approach to target end-to-end entity linking (EL) over knowledge bases. CHOLAN consists of a pipeline of two transformer-based models integrated sequentially to accomplish the EL task. The first transformer model identifies surface forms (entity mentions) in a given text. For each mention, a second transformer model is employed to classify the target entity among a predefined candidates list. The latter transformer is fed by an enriched context captured from the sentence (i.e. local context), and entity description gained from Wikipedia. Such external contexts have not been used in the state of the art EL approaches. Our empirical study was conducted on two well-known knowledge bases (i.e., Wikidata and Wikipedia). The empirical results suggest that CHOLAN outperforms state-of-the-art approaches on standard datasets such as CoNLL-AIDA, MSNBC, AQUAINT, ACE2004, and T-REx.
QA2Explanation: Generating and Evaluating Explanations for Question Answering Systems over Knowledge Graph
Oct 16, 2020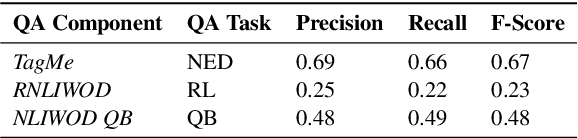
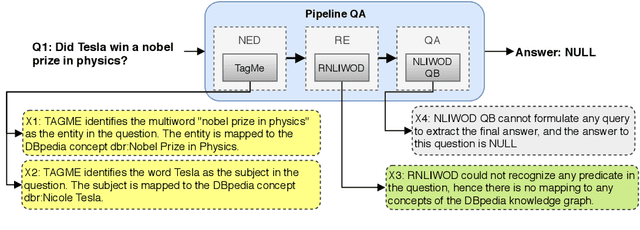
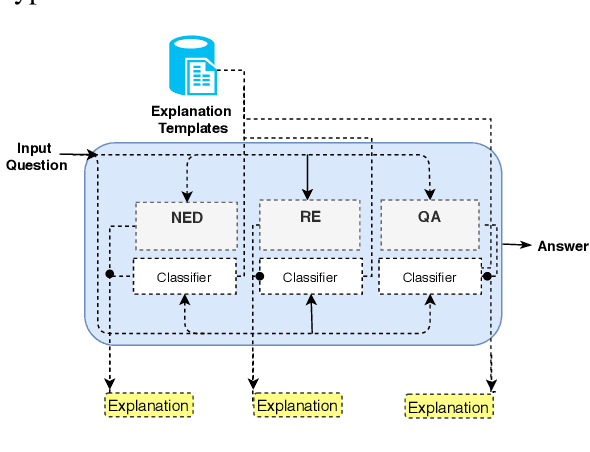

In the era of Big Knowledge Graphs, Question Answering (QA) systems have reached a milestone in their performance and feasibility. However, their applicability, particularly in specific domains such as the biomedical domain, has not gained wide acceptance due to their "black box" nature, which hinders transparency, fairness, and accountability of QA systems. Therefore, users are unable to understand how and why particular questions have been answered, whereas some others fail. To address this challenge, in this paper, we develop an automatic approach for generating explanations during various stages of a pipeline-based QA system. Our approach is a supervised and automatic approach which considers three classes (i.e., success, no answer, and wrong answer) for annotating the output of involved QA components. Upon our prediction, a template explanation is chosen and integrated into the output of the corresponding component. To measure the effectiveness of the approach, we conducted a user survey as to how non-expert users perceive our generated explanations. The results of our study show a significant increase in the four dimensions of the human factor from the Human-computer interaction community.
* Accepted in IntEx-SemPar: Interactive and Executable Semantic Parsing EMNLP 2020 Workshop
RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network
Sep 18, 2020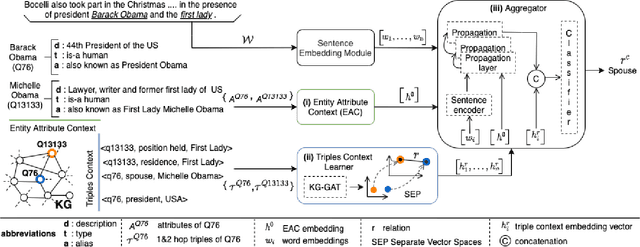
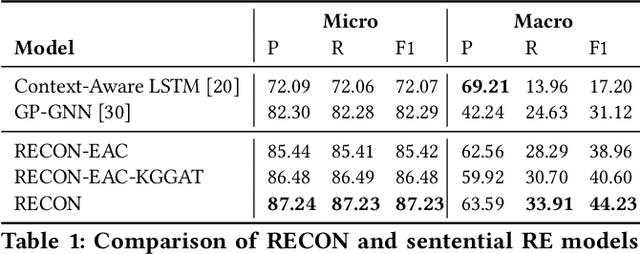
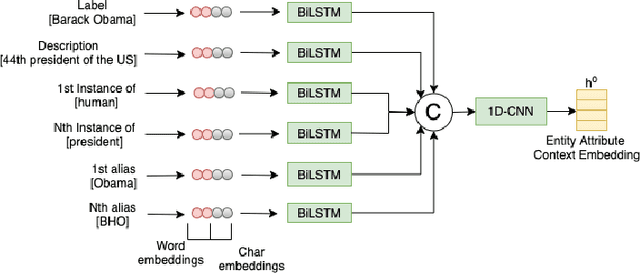
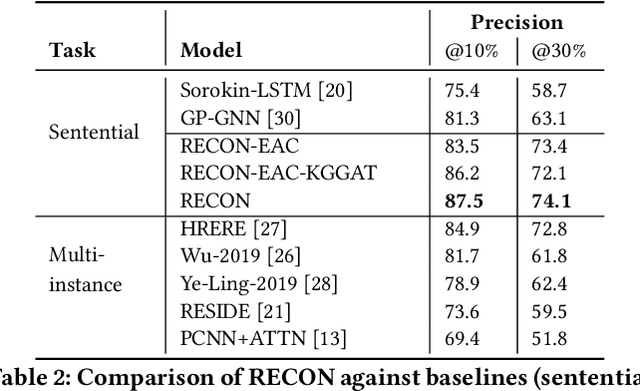
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets. RECON reports 87.23 F1 score (Vs 82.29 baseline) on Wikidata dataset whereas on NYT Freebase, reported values are 87.5(P@10) and 74.1(P@30) compared to the previous baseline scores of 81.3(P@10) and 63.1(P@30).
Context-aware Entity Linking with Attentive Neural Networks on Wikidata Knowledge Graph
Dec 12, 2019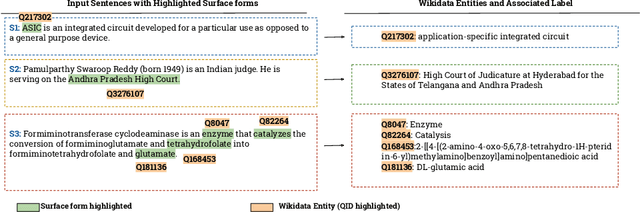
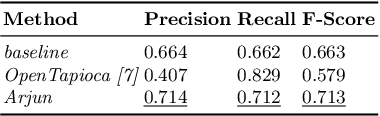
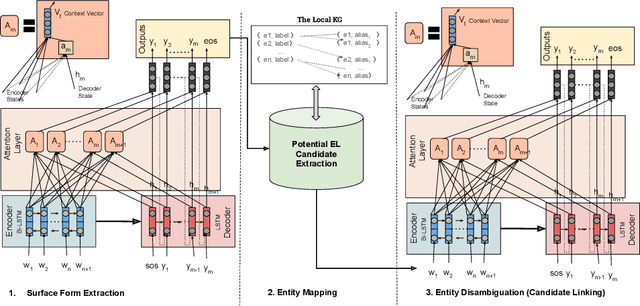
The Entity Linking (EL) approaches have been a long-standing research field and find applicability in various use cases such as semantic search, text annotation, question answering, etc. Although effective and robust, current approaches are still limited to particular knowledge repositories (e.g. Wikipedia) or specific knowledge graphs (e.g. Freebase, DBpedia, and YAGO). The collaborative knowledge graphs such as Wikidata excessively rely on the crowd to author the information. Since the crowd is not bound to a standard protocol for assigning entity titles, the knowledge graph is populated by non-standard, noisy, long or even sometimes awkward titles. The issue of long, implicit, and nonstandard entity representations is a challenge in EL approaches for gaining high precision and recall. In this paper, we advance the state-of-the-art approaches by developing a context-aware attentive neural network approach for entity linking on Wikidata. Our approach contributes by exploiting the sufficient context from a Knowledge Graph as a source of background knowledge, which is then fed into the neural network. This approach demonstrates merit to address challenges associated with entity titles (multi-word, long, implicit, case-sensitive). Our experimental study shows $\approx$8\% improvements over the baseline approach, and significantly outperform an end to end approach for Wikidata entity linking. This work, first of its kind, opens a new direction for the research community to pay attention to developing context-aware EL approaches for collaborative knowledge graphs.
Towards Optimisation of Collaborative Question Answering over Knowledge Graphs
Aug 14, 2019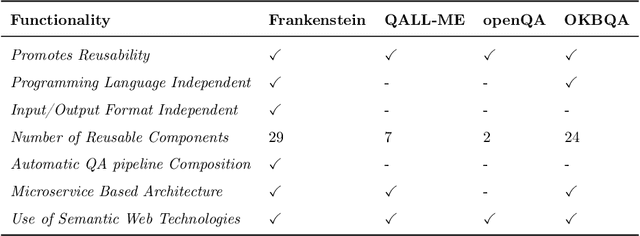
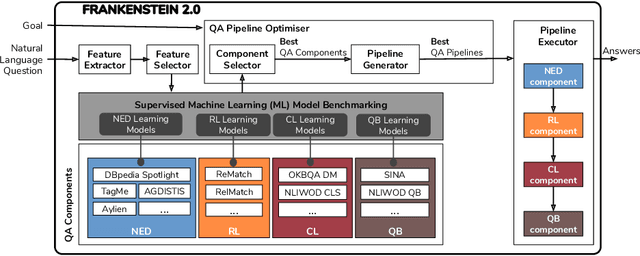
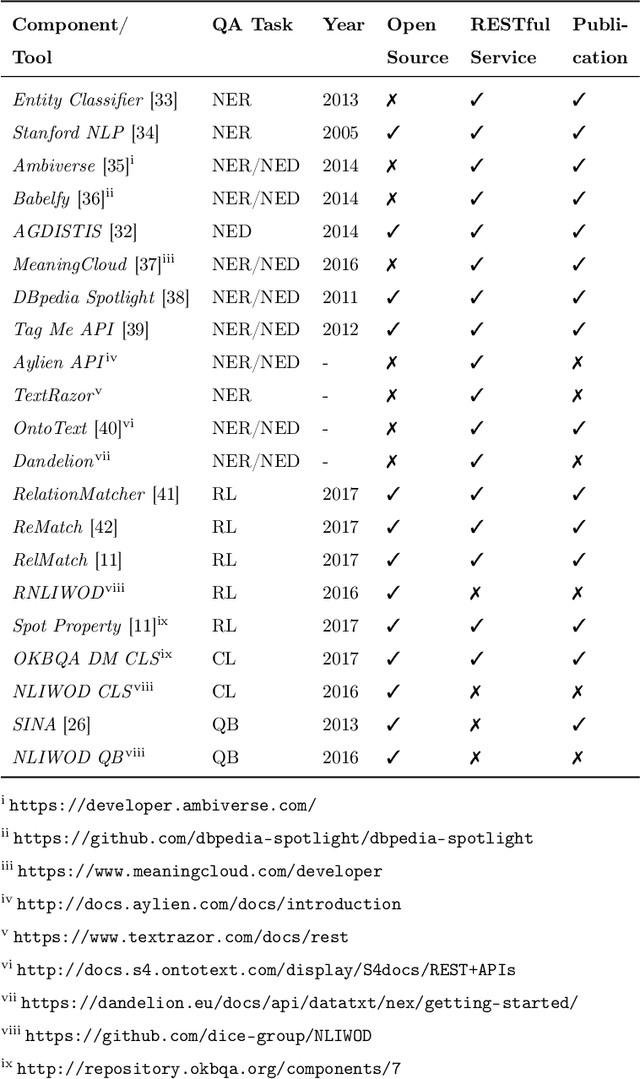
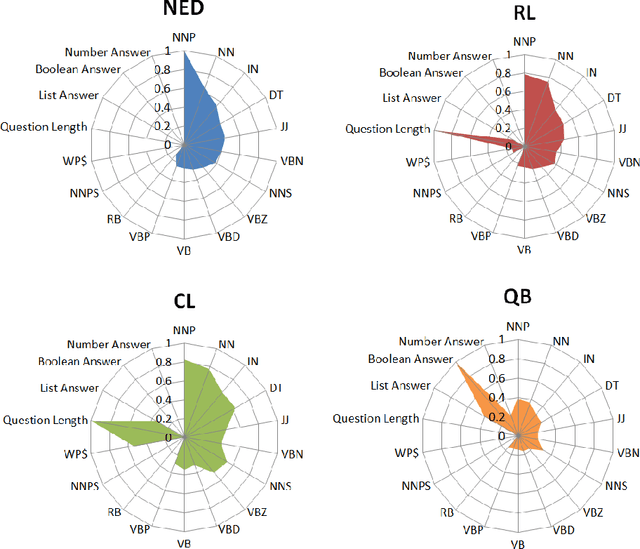
Collaborative Question Answering (CQA) frameworks for knowledge graphs aim at integrating existing question answering (QA) components for implementing sequences of QA tasks (i.e. QA pipelines). The research community has paid substantial attention to CQAs since they support reusability and scalability of the available components in addition to the flexibility of pipelines. CQA frameworks attempt to build such pipelines automatically by solving two optimisation problems: 1) local collective performance of QA components per QA task and 2) global performance of QA pipelines. In spite offering several advantages over monolithic QA systems, the effectiveness and efficiency of CQA frameworks in answering questions is limited. In this paper, we tackle the problem of local optimisation of CQA frameworks and propose a three fold approach, which applies feature selection techniques with supervised machine learning approaches in order to identify the best performing components efficiently. We have empirically evaluated our approach over existing benchmarks and compared to existing automatic CQA frameworks. The observed results provide evidence that our approach answers a higher number of questions than the state of the art while reducing: i) the number of used features by 50% and ii) the number of components used by 76%.
A Road-map Towards Explainable Question Answering A Solution for Information Pollution
Jul 04, 2019

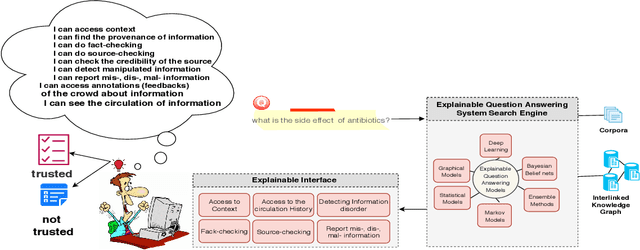

The increasing rate of information pollution on the Web requires novel solutions to tackle that. Question Answering (QA) interfaces are simplified and user-friendly interfaces to access information on the Web. However, similar to other AI applications, they are black boxes which do not manifest the details of the learning or reasoning steps for augmenting an answer. The Explainable Question Answering (XQA) system can alleviate the pain of information pollution where it provides transparency to the underlying computational model and exposes an interface enabling the end-user to access and validate provenance, validity, context, circulation, interpretation, and feedbacks of information. This position paper sheds light on the core concepts, expectations, and challenges in favor of the following questions (i) What is an XQA system?, (ii) Why do we need XQA?, (iii) When do we need XQA? (iv) How to represent the explanations? (iv) How to evaluate XQA systems?
HCqa: Hybrid and Complex Question Answering on Textual Corpus and Knowledge Graph
Nov 24, 2018



Question Answering (QA) systems provide easy access to the vast amount of knowledge without having to know the underlying complex structure of the knowledge. The research community has provided ad hoc solutions to the key QA tasks, including named entity recognition and disambiguation, relation extraction and query building. Furthermore, some have integrated and composed these components to implement many tasks automatically and efficiently. However, in general, the existing solutions are limited to simple and short questions and still do not address complex questions composed of several sub-questions. Exploiting the answer to complex questions is further challenged if it requires integrating knowledge from unstructured data sources, i.e., textual corpus, as well as structured data sources, i.e., knowledge graphs. In this paper, an approach (HCqa) is introduced for dealing with complex questions requiring federating knowledge from a hybrid of heterogeneous data sources (structured and unstructured). We contribute in developing (i) a decomposition mechanism which extracts sub-questions from potentially long and complex input questions, (ii) a novel comprehensive schema, first of its kind, for extracting and annotating relations, and (iii) an approach for executing and aggregating the answers of sub-questions. The evaluation of HCqa showed a superior accuracy in the fundamental tasks, such as relation extraction, as well as the federation task.