 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Knowledge of Emerging Entities From Extended Search Snippets
Paper and Code
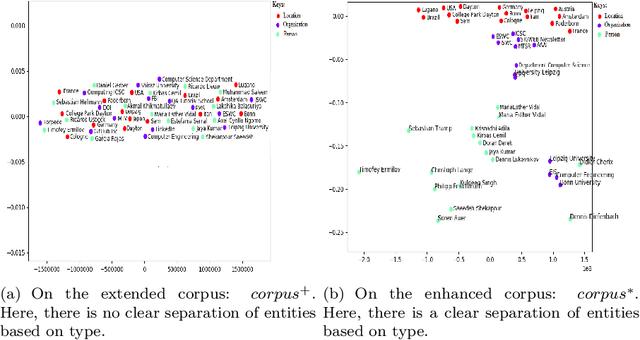

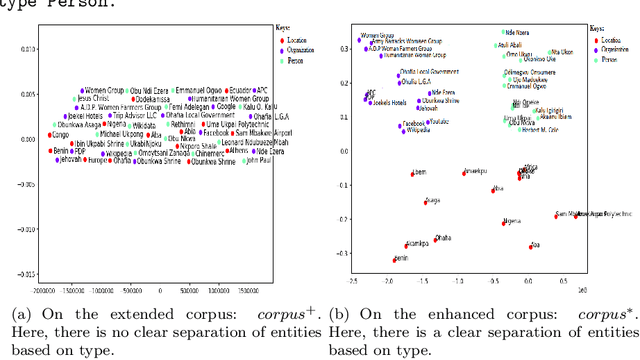
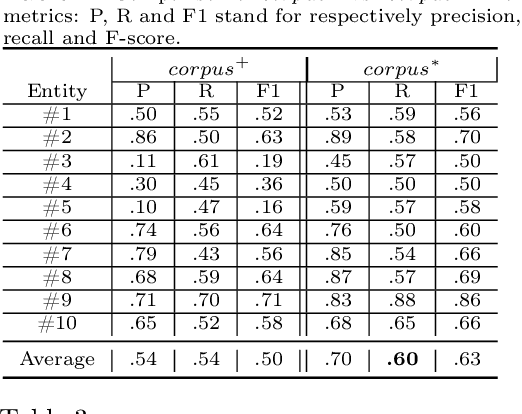
Google and other search engines feature the entity search by representing a knowledge card summarizing related facts about the user-supplied entity. However, the knowledge card is limited to certain entities that have a Wiki page or an entry in encyclopedias such as Freebase. The current encyclopedias are limited to highly popular entities, which are far fewer compared with the emerging entities. Despite the availability of knowledge about the emerging entities on the search results, yet there are no approaches to capture, abstract, summerize, fuse, and validate fragmented pieces of knowledge about them. Thus, in this paper, we develop approaches to capture two types of knowledge about the emerging entities from a corpus extended from top-n search snippets of a given emerging entity. The first kind of knowledge identifies the role(s) of the emerging entity as, e.g., who is s/he? The second kind captures the entities closely associated with the emerging entity. As the testbed, we considered a collection of 20 emerging entities and 20 popular entities as the ground truth. Our approach is an unsupervised approach based on text analysis and entity embeddings. Our experimental studies show promising results as the accuracy of more than $87\%$ for recognizing entities and $75\%$ for ranking them. Besides $87\%$ of the entailed types were recognizable. Our testbed and source code is available on Github https://github.com/sunnyUD/research_source_code.